A new exponentially decaying error correlation model for assimilating OCO-2 column-average CO2 data using a length scale computed from airborne ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022 © Author(s) 2022. This work is distributed under the Creative Commons Attribution 4.0 License. A new exponentially decaying error correlation model for assimilating OCO-2 column-average CO2 data using a length scale computed from airborne lidar measurements David F. Baker1 , Emily Bell1 , Kenneth J. Davis2,3 , Joel F. Campbell4 , Bing Lin4 , and Jeremy Dobler5 1 Cooperative Institute for Research in the Atmosphere, Colorado State University, Fort Collins, CO, USA 2 Department of Meteorology and Atmospheric Science, Pennsylvania State University, University Park, PA, USA 3 Earth and Environmental Systems Institute, Pennsylvania State University, University Park, PA, USA 4 NASA Langley Research Center, Hampton, VA, USA 5 Spectral Sensor Solutions LLC, Fort Wayne, IN, USA Correspondence: David F. Baker (david.f.baker@colostate.edu) Received: 30 December 2020 – Discussion started: 18 February 2021 Revised: 18 November 2021 – Accepted: 27 November 2021 – Published: 26 January 2022 Abstract. To check the accuracy of column-average dry air with-distance error model that was used to summarize the CO2 mole fractions (XCO2 ) retrieved from Orbiting Carbon OCO-2 version 9 XCO2 retrievals as part of the OCO-2 flux Observatory (OCO-2) data, a similar quantity has been mea- inversion model intercomparison project. We then derive a sured from the Multi-functional Fiber Laser Lidar (MFLL) new one-dimensional error model using correlations that de- aboard aircraft flying underneath OCO-2 as part of the Atmo- cay exponentially with separation distance, apply this model spheric Carbon and Transport (ACT) – America flight cam- to the OCO-2 data using the correlation length scales derived paigns. Here we do a lagged correlation analysis of these from the MFLL–OCO-2 differences, and compare the results MFLL–OCO-2 column CO2 differences and find that their (for both the average and its uncertainty) to those given by correlation spectrum falls off rapidly at along-track separa- the current constant correlation error model. To implement tion distances under 10 km, with a correlation length scale of this new model, the data are averaged first across 2 s spans about 10 km, and less rapidly at longer separation distances, to collapse the cross-track distribution of the real data onto with a correlation length scale of about 20 km. the 1-D path assumed by the new model. Considering cor- The OCO-2 satellite takes many CO2 measurements with related errors can cause the average value to fall outside the small (∼ 3 km2 ) fields of view (FOVs) in a thin (< 10 km range of the values averaged; two strategies for preventing wide) swath running parallel to its orbit: up to 24 separate this are presented. The correlation lengths over the ocean, FOVs may be obtained per second (across a ∼ 6.75 km dis- which the land-based MFLL data do not clarify, are assumed tance on the ground), though clouds, aerosols, and other fac- to be twice those over the land. tors cause considerable data dropout. Errors in the CO2 re- The new correlation model gives 10 s XCO2 averages that trieval method have long been thought to be correlated at are only a few tenths of 1 ppm different from the constant these fine scales, and methods to account for these when as- correlation model. Over land, the uncertainties in the mean similating these data into top-down atmospheric CO2 flux in- are also similar, suggesting that the +0.3 constant correla- versions have been developed. A common approach has been tion coefficient currently used in the model there is accurate. to average the data at coarser scales (e.g., in 10 s long bins) Over the oceans, the twice-the-land correlation lengths that along-track, then assign an uncertainty to the averaged value we assume here result in a significantly lower uncertainty on that accounts for the error correlations. Here we outline the the mean than the +0.6 constant correlation currently gives methods used up to now for computing these 10 s averages – measurements similar to the MFLL ones are needed over and their uncertainties, including the constant-correlation- the oceans to do better. Finally, we show how our 1-D expo- Published by Copernicus Publications on behalf of the European Geosciences Union.
650 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
nential error correlation model may be used to account for model; similarly, any error in surface CO2 flux in a forward
correlations in inversion methods that choose to assimilate model will result in highly correlated errors in neighboring
each XCO2 retrieval individually and also to account for cor- XCO2 measurements influenced by these fluxes. Also, sys-
relations between separate 10 s averages when these are as- tematic errors in the individual CO2 retrievals are correlated
similated instead. at finer scales because incorrect assumptions are made about
the scatterers, water vapor, temperature, and surface proper-
ties used in the retrieval scheme, and these variables them-
selves have errors that are correlated at these scales. The
1 Introduction OCO-2 satellite, for example, makes 24 separate observa-
tions per second across a distance of ∼ 6.75 km along the
Column-averaged CO2 mixing ratio measurements taken ground track: these data provide mostly redundant column
from satellites provide coverage across the globe that is far CO2 information across that time. When deciding how to
more extensive than that from in situ measurements. These weight the satellite data in the inversions relative to the a
satellite measurements are often used in global atmospheric priori information, some assumptions about these measure-
flux inversions to provide a “top-down” constraint on surface ment error correlations must therefore be made: if these er-
sources and sinks of CO2 . The atmospheric transport mod- rors were assumed to all be independent, the total amount of
els underlying these global inversions are generally run at a measurement information going into the inversions would be
coarse resolution using grid boxes of hundreds of kilometers much too high, resulting in improper weighting versus the a
on a side. The resolution is limited for computational rea- priori or dynamically propagated information in the problem.
sons (the models must be run many dozens of times across Our goal here is to present a new model of the errors in the
the measurements to obtain the inverse estimate) and because OCO-2 CO2 measurements that assumes correlations that die
the spatial coverage of the satellite measurements is currently off exponentially with distance, as opposed to the constant
not dense enough to resolve spatial scales much finer than correlation models used previously. This new model will al-
this when solving at typical timescales (the gap in longitude low the CO2 measurements to be weighted more accurately
between subsequent passes of a typical low-Earth-orbiting in inversions, yielding more accurate CO2 flux estimates.
(LEO) satellite taking a single thin swath of data along its or- Until recently, there have not been any good ground-truth
bit path is ∼ 25◦ , resulting in gaps of between 3 and 4◦ across data available to evaluate satellite CO2 measurement errors
a week, gaps which are generally never filled in further due at finer scales. At coarser scales, data from the Total Carbon
to the repeat cycle of the satellite’s orbit). The typical field Column Observing Network (TCCON) have been used to as-
of view (FOV) of individual retrievals is often much smaller sess the magnitude and seasonal variability of OCO-2 errors
than this grid box scale, however: FOVs for retrievals from (Wunch et al., 2017), as well as what portion of these might
the Orbiting Carbon Observatory (OCO-2) satellite (Crisp et be considered random as opposed to systematic (Kulawik et
al., 2004, 2008), for example, are typically ∼ 2.25 km along- al., 2019). Worden et al. (2017) have done a similar random
track by at most 1.25 km across-track (Eldering et al., 2017). versus systematic partitioning of OCO-2 errors by looking
The individual OCO-2 retrievals are generally averaged to- at the variability of retrieved XCO2 across small areas inside
gether along-track across some distance closer to the model which the real CO2 is thought not to vary much. Compar-
grid box size before being assimilated in the inversion: this isons to realistic CO2 fields given by atmospheric transport
is because the modeled measurements to which the true mea- models (e.g., using plausible prior flux estimates and forced
surements will be compared in the inversion are available to agree with the available in situ CO2 measurements) have
only at the grid box resolution, so it makes little sense to as- also been used to assess systematic errors in the satellite re-
similate each measurement individually when assimilating a trievals (O’Dell et al., 2012, 2018) at seasonal timescales and
coarse-resolution average that summarizes those values will regional spatial scales. The TCCON sites provide column-
do just as well. averaged CO2 measurements that can be compared directly
Whether the individual OCO-2 retrievals or coarser- to the OCO-2 column measurements, but because they are
resolution averages of them are assimilated into the inverse available only in a few fixed locations, they cannot assess
model, correlations between the errors in the individual CO2 how these errors vary along-track. There have been many air-
measurements must be considered. CO2 mixing ratios in the craft underflights of OCO-2, but these generally have taken
upper part of the atmospheric column (at all levels but the only in situ measurements of CO2 representative of a partic-
immediate surface layer) feel the influence of multiple flux ular elevation rather than a column average. Some of these
locations at the surface due to atmospheric mixing, which flights provide data across most of the atmospheric column
widens and homogenizes the zone of influence as time goes (i.e., vertical profiles) but only generally at widely spaced lo-
on. XCO2 is a measure of CO2 across the full column and cations. None of these data are really well-suited for assess-
is dominated by such effects: any error in XCO2 will be ing along-track errors in the column average.
translated into highly correlated errors in neighboring sur- Over the past several years, however, column-average
face fluxes when used as a measurement in an inversion measurements of CO2 from aircraft-based lidars have be-
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022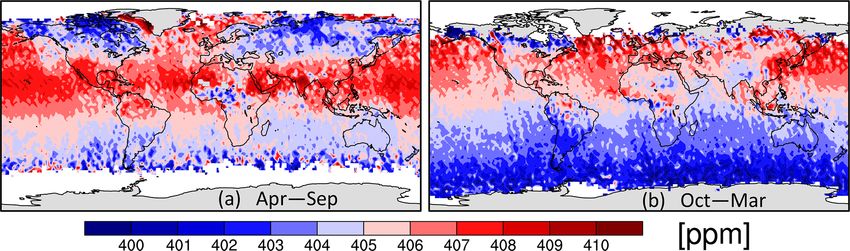
D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them 651 come available. Several of these lidars were instrument test leaving the form of the correlation matrix, C, general. Sec- beds developed as part of NASA’s Active Sensing of CO2 tion 3.1.1 discusses averages in which all the averaged re- Emissions over Nights, Days, and Seasons (ASCENDS) trievals are assumed to be independent (i.e., a diagonal C), satellite project (Jucks et al., 2015; Kawa et al., 2018). One Sect. 3.1.2 the case in which the errors in all the averaged of these, the Multi-functional Fiber Laser Lidar (MFLL) retrievals are assumed to be correlated with all the others (Dobbs et al., 2008; Dobler et al., 2013), has been flown in the span with the same positive correlation coefficient (Campbell et al., 2020) as part of NASA’s Atmospheric Car- (all the off-diagonal terms in C having the same value), and bon and Transport (ACT) – America project, an effort to de- Sect. 3.1.3 the case in which the correlations are assumed to tail CO2 variability as a function of weather and front loca- die out exponentially with distance along the satellite track tion across the eastern half of North America (Davis et al., (exponential decay off main diagonal in C). When averag- 2021). Several of these MFLL flights were designed to pass ing data with unequal uncertainty values, considering cor- underneath OCO-2 along its ground track as it passed by, related errors can cause the average value computed to fall allowing CO2 from the better part of the full column to be outside the range of the input values to be averaged. While compared between the two. Bell et al. (2020) have lined up this is a correct and natural consequence of the correlated er- the MFLL and OCO-2 data for these flights as a function ror assumption, it does violate a key condition usually spec- of horizontal location and have assessed the accuracy of the ified when defining a weighted average to prevent just that along-track change in CO2 (the linear slope) from OCO-2 behavior: that all the weights be non-negative. Section 3.2 using the MFLL data as a ground truth: they accounted for discusses this issue in more detail and lays out a couple of the differences in the vertical averaging kernels and vertical fallback options that we have used to stay with non-negative- extent between the two measurements in doing this compari- weighted averages, while still reaping the benefits of the cor- son. Here, we use this same Bell et al. (2020) dataset to assess related error assumption. Section 3.3 applies these different the along-track correlation length scale of the MFLL–OCO-2 correlation models (including both those with the fallback measured column CO2 differences. weighting and those without it) to two simple example cases, A team of inverse modelers using the OCO-2 XCO2 re- calculating the total measurement information content given trievals have formed an OCO-2 flux inversion model inter- by each model. Section 3.4 shows how the exponentially de- comparison project (MIP) to help differentiate the CO2 fluxes caying correlation model (or “exponential” model hereafter) robustly constrained by the OCO-2 data from the confound- may be used to compute the effect of correlations between ing biases in those same data (Crowell et al., 2019; Peiro et the full-span averages themselves (instead of the values go- al., 2021): doing this as a MIP helps mitigate the impact of ing into them). In Sect. 3.5, we assess the impact of the corre- the errors in individual transport models (by looking at the lation length scale determined from the MFLL–OCO-2 data results across the full ensemble of models) and the impact of on the averages of actual OCO-2 version 10 XCO2 retrievals any differences in the measurements and measurement errors by calculating 10 s average values and their uncertainties us- used in the inversions (all MIP participants were directed to ing the new exponential correlation error model and com- use the same 10 s average OCO-2 XCO2 measurements and paring them to those given by the constant correlation er- uncertainties). Here, we use the OCO-2 XCO2 10 s averag- ror model. Finally, we discuss the implications of the new ing problem as an application to test the impact of the newly length-scale-dependent correlations in the conclusion. computed length scale. We interpret the MFLL–OCO-2 dif- ferences as OCO-2 retrieval errors and use the associated er- ror correlation length scale to formulate a new model for the 2 Computing a correlation length scale from measured 10 s average XCO2 value and its uncertainty. We then com- MFLL–OCO-2 column-average CO2 differences pare the results of this new error model to the results of the current error model to assess the impact of the newly cal- 2.1 MFLL measurements and their pairing with culated correlation length scale on both the absolute values OCO-2 overflight data of XCO2 and the uncertainty calculated for the 10 s average values. The NASA-funded Atmospheric Carbon and Transport To better present the logical flow of our argument, we will (ACT) – America project flew five aircraft campaigns over split the paper into two parts, presenting both the method and the 2016–2019 time period, measuring CO2 , CH4 , and me- results of our MFLL–OCO-2 analysis in the first (Sect. 2), teorological variables in an effort to understand the relation- then the method and results for the OCO-2 averaging ap- ship between atmospheric carbon and weather patterns, as plication in the second. Since a few different averaging ap- well as the processes driving the uptake and release of car- proaches have been used over time with the OCO-2 data, bon. These campaigns were done across all four seasons, these previous methods will be outlined in this second sec- each with flights in the mid-Atlantic, Midwest, and Gulf tion for context, before describing a new averaging approach Coast regions of North America (Davis et al., 2021). As part using the correlation length scale. Section 3.1 presents a of this effort, flights were made along the ground tracks of general framework for the OCO-2 data averaging approach, the OCO-2 satellite, instrumented with downward-viewing https://doi.org/10.5194/gmd-15-649-2022 Geosci. Model Dev., 15, 649–668, 2022
652 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
lidars taking CO2 measurements that could be compared with ing for the differences in vertical weighting has fortunately
the column-averaged CO2 data taken by OCO-2. already been done by Bell (2018) and Bell et al. (2020). They
The OCO-2 satellite measures radiances that are sensi- used these data to test the accuracy of the spatial trend in CO2
tive to dry air CO2 mixing ratios throughout the depth of retrieved by OCO-2 across the flight legs; here, we will use
the atmospheric column. CO2 mixing ratios are retrieved a subset of that same dataset to look at shorter-scale spatial
from these data at 20 levels in the vertical, evenly spaced in variability (Baker et al., 2020). The reader is referred to Bell
terms of pressure. Because there is not enough information et al. (2020) for further details of the MFLL and OCO-2 mea-
to robustly differentiate these 20 values, a single pressure- surements, as well as the comparison method and the details
weighted vertical average value, XCO2 , is computed from of the measurements on each flight leg.
these. How much information is contributed to the XCO2
value from each level, as opposed to being taken from some 2.2 Method for analyzing a correlation length scale
prior guess, is shown by the shape of the vertical averag-
ing kernel vector (see Fig. 6 of Bell et al., 2020): a value As described in Bell (2018) and Bell et al. (2020), the MFLL
of 1 meaning all from the measurement and of 0 meaning all data have been binned and averaged across 60 s blocks cor-
from the prior. The satellite flies in a sun-synchronous orbit, responding to swaths of from 7 to 9 km in length along the
passing over the Equator at about 13:30 local time, as the OCO-2 ground track, depending on how fast the C-130 air-
Earth rotates underneath it; its 81◦ orbital inclination means craft was flying at the time. All valid cloud-free OCO-2 re-
that the flight path over North America is tilted somewhat, trievals (those declared “good” by the OCO-2 quality screen-
with the basic south-to-north motion going a bit SE to NW. ing criteria) falling within the MFLL horizontal location
Its 7077.7 km orbital semi-major axis results in a velocity range are similarly averaged. (Note, again, that the co-located
of ∼ 6.75 km s−1 for its field of view (FOV) on the surface MFLL and OCO-2 data may have measurement times that
and gives 15 or 16 orbits per day. The observed path is at differ by up to an hour or more.) Only spans with more than
most 10 km wide, located along the ground track in nadir- about 20 MFLL and 3 OCO-2 measurements are used in the
viewing mode, and roughly parallel to it in glint mode: there analysis. Here we use the satellite FOV latitude and longi-
are eight FOVs in the cross-track direction, each at most tude to calculate the distance between different measurement
1.25 km wide, and three cross-track scans are taken per sec- blocks. We subtract the OCO-2 average from its correspond-
ond, making each FOV extend ∼ 2.25 km in the along-track ing MFLL average for each common bin, then divide the
direction. difference Xj by the following OCO-2 XCO2 measurement
The MFLL lidar (Dobbs et al., 2008; Dobler et al., 2013) uncertainty value:
was one of several flight instruments developed as a test bed σj2 = σj,retr
2
+ (0.3 ppm)2 , (1)
for the CO2 lidar to be used aboard NASA’s proposed AS-
CENDS satellite (Jucks et al., 2015; Kawa et al., 2018). We where the XCO2 uncertainty from the retrieval, σj,retr , has
examine MFLL data from six OCO-2 underflights here, four been increased by a floor of 0.3 ppm to account for nonlin-
taken over the Great Plains and two over the Mid-Atlantic earities in the uncertainty calculation; this gives Yj = Xj /σj .
(Table 1). The flight legs were generally around 500 km in We then detrend this weighted-difference time series across
length, with the aircraft taking about an hour to fly that dis- each flight leg – subtracting either a single constant value
tance. The satellite FOV, on the other hand, would take only or a linear trend Y (x), where x is the along-track distance.
about 75 s to traverse the same route so that, although the air- The autocovariance function of this difference time series
craft and satellite would be looking at very close to the same was then computed as
point on the ground at some point during the flight, the time
Nh
difference in viewing could be up to 40 min or so at the ends 1 X
ch = (Yx − Y )(Yx+h − Y ), (2)
of each leg: some change in the CO2 actually measured at Nh x=1
the same location could thus be expected due to the blow-
ing winds. The lidar was carried on a C-130 aircraft flying where Nh is the number of data values falling into each
generally 8–9 km above ground level, or at about 350 hPa; distance lag bin h (using an 8 km resolution) across all
because the OCO-2 measurements give lower weight to the six flight legs. Finally, the autocorrelation coefficient val-
upper parts of the column, the MFLL data are therefore able ues were computed as rh = ch /co to give the autocorrelation
to provide an independent validation constraint on at least spectrum shown in Fig. 1. A variety of sensitivity tests were
the lower 2/3 of the OCO-2 column averages. The vertical performed, as well: (1) the correlations were computed with-
weighting of the two measurements, as embodied in their out first dividing by the OCO-2 measurement uncertainties;
averaging kernel vectors, is also different, with the MFLL (2) the data used in the analysis were restricted to pairs for
instrument giving more weight to the upper part of the mea- which the MFLL and OCO-2 sampling times were within
sured column just underneath the flight level, while the OCO- some threshold (3000, 1500, 1000 s); (3) whole flight legs of
2 weight is more flat with pressure (see Fig. 6 of Bell et al., data were left out of the computation in succession; and (4)
2020). Lining up the two sets of measurements and account- the pre-conditioning of the time series was switched between
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022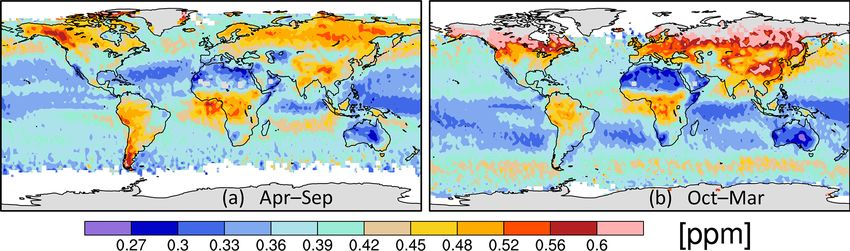
D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them 653
Table 1. Information on which MFLL–OCO-2 co-location points from which ACT-America flight legs were used in this study, including the
crossing locations (points of closest approach between the aircraft and OCO-2 FOVs). See Bell (2018) and Bell et al. (2020) for more details.
Date Data Length Altitude Leg start Leg end Crossing Flight
[YYYYMMDD] Points [km] [km] ◦ long ◦ lat ◦ long ◦ lat ◦ long ◦ lat location
20160727 46 414 9.0 −77.6 39.5 −78.8 43.1 −78.0 40.8 Pennsylvania
20160805 59 539 9.0 −102.1 43.3 −103.7 48.0 −103.3 46.8 S and N Dakota
20170215 58 535 8.7 −101.1 40.1 −99.4 35.5 −100.3 38.2 Kansas – Oklahoma
20170308 43 453 6.0 −76.9 37.0 −78.1 40.9 −77.2 38.0 Virg.–Maryland–Penn.
20171022 78 501 8.9 −98.6 35.4 −100.2 39.7 −99.6 38.2 Oklahoma – Kansas
20171027 66 618 8.5 −99.5 35.3 −101.2 40.7 −100.4 38.5 Oklahoma – Kansas
subtracting a constant value versus a linear trend. The only 0.3 or 0.5 ppm. This is large enough to be a significant frac-
test that significantly changed the character of the spectrum tion of the systematic errors in the OCO-2 data taken over
was the last one. land, which have been calculated to be about 0.6 ppm by Ku-
lawik et al. (2019).
2.3 Correlation length scale results Because the MFLL data have been blocked into bins of 7
to 9 km in length, this analysis cannot resolve scales finer
than that. That we obtain a length scale 2 to 3 times this
As shown in Fig. 1, the autocorrelation of the MFLL–OCO-2
minimum scale does suggest that it is real and not an arti-
differences falls off quickly, with no significant correlations
fact of the analysis. This 20 km length scale provides a sig-
at scales of more than about 20 km along-track. Even corre-
nificant constraint on the information content of the OCO-2
lations at length scales shorter than 20 km are only weakly
data in an average: it the scale was shorter, the uncertainty on
significant (at about the 1.5σ level); this analysis is pushing
longer averages would drop considerably, so if we consider
the boundaries of what this small set of comparison data can
the 20 km scale as an upper bound, we are being conservative
tell us. Still, for the case in which only a constant offset be-
(i.e., giving the data less weight in an inversion by applying
tween the MFLL and OCO-2 time series is subtracted off,
a larger uncertainty to them). An exponential decay model
an exponentially decaying curve with a correlation length of
of the shape of the correlations is not perfect but does not
20 km does a reasonable job of fitting the spectrum, although
seem unreasonable to try when implementing the correlation
there is a tendency for the actual spectrum to fall immedi-
structure found here.
ately to a correlation level of about +0.4 and then plateau
somewhat out to a lag of 40 km. When the difference time
series are detrended with a sloping line, the correlations drop 3 Application: 10 s averages of the OCO-2 XCO2 data
off more quickly, with a correlation length of about 15 km,
which is not surprising since more broad-scale information is We examine how the error correlation length scale derived
removed by subtracting off the trend. We feel that subtract- above can help in weighting the column CO2 data from the
ing off a sloped trend from spans of OCO-2 data this short OCO-2 satellite when used in global flux inversions. We fo-
(< 600 km) is not appropriate, since the actual OCO-2 bias cus here on the specific case of averaging the data across 10 s
correction procedure is done globally and certainly leaves measurement spans (equivalent to an along-track distance of
uncorrected gradients at these scales that ought to be consid- ∼ 67.5 km), but in the process we will get insight into how to
ered in the analysis, so we believe that the longer length scale handle data assimilated at both coarser scales and finer scales
(20 km) would be more appropriate to apply as an OCO-2 er- down to the 7–9 km MFLL binning size used here. We treat
ror correlation length. (However, when averaging over very the MFLL data as the “truth” and interpret the entire MFLL–
short spatial scales, say 10 km or less, the data would then OCO-2 difference as an error in the retrieved OCO-2 XCO2
support a correlation length scale of about 10 km due to the values. An averaging approach that considers these correla-
rapid initial fall.) tion lengths is derived below, along with alternatives that use
The magnitude of the correlated variability is given by simpler assumptions, to help illustrate the differences caused
multiplying the square roots of the correlation coefficients by using our new approach.
shown in Fig. 1 by the normalization factors obtained in com-
puting them (0.59 ppm or 1.003 ppm when the trend is re- 3.1 Data averaging approach
moved or not removed; or in terms of multiples of the uncer-
tainty assumed on each MFLL–OCO-2 difference: 0.84 or Most estimation methods used in global atmospheric trace
1.04σ ). Moving over to 20 km on the x axis, a coefficient of gas inversion work (Bayesian synthesis inversions, Kalman
0.25 translates into a magnitude of 0.5× (0.59 or 1.003) = filters, variational data assimilation) combine measurement
https://doi.org/10.5194/gmd-15-649-2022 Geosci. Model Dev., 15, 649–668, 2022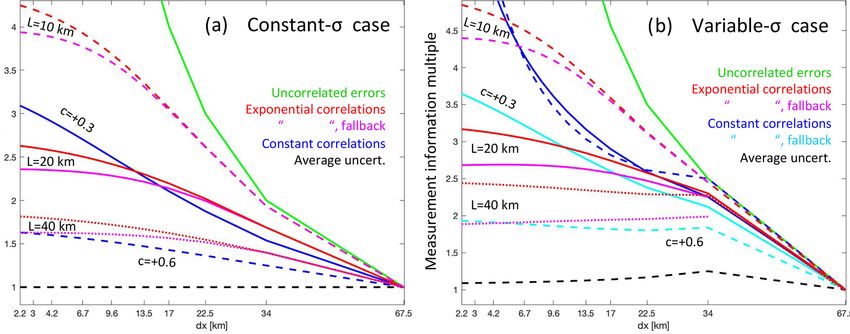
654 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
Figure 1. The autocorrelation of the MFLL–OCO-2 difference computed across six ACT-America flight legs as a function of the sepa-
ration distance 1x [km] along the OCO-2 ground track (blue), plus its 1σ significance bounds (red). Plots are given for two different
pre-conditioning methods: (a) subtracting off only a constant offset or (b) subtracting off a linear trend from each flight leg. An exponentially
decaying curve with a correlation length of 20 km is also plotted in both panels.
information in different time spans as inversions, has often been followed in assimilating OCO-2
CO2 data in global flux inversions: the measurements are first
R−1 −1 −1
6 x 6 = R1 x 1 + R2 x 2 , (3)
averaged across a certain time span (with any error corre-
R−1
6 = R−1 −1
1 + R2 , (4) lations across these finer timescales and space scales being
considered in the averaging process), then when these mea-
where x i is a vector of measurements within time span i and
surement averages are assimilated into the inversion, their er-
Ri the measurement error covariance matrix for x i . If R−1
rors are considered to be independent in a manner similar to
is thought of as measurement “information” (i.e., the Fisher
that used in the inversion methods themselves.
information matrix: see Rodgers, 2000), then R−1 6 represents The OCO-2 satellite makes three cross-scans per second,
the sum of the information in time spans 1 and 2, and x 6 can
each of which spans only 10 km across-track and is di-
be thought of as a weighted average of x 1 and x 2 that sum-
vided into eight separate fields of view. Because the satel-
marizes their information. Note, however, that this approach
lite “pirouettes” to keep the sun perpendicular to the view-
veers wildly between extremes in its treatment of error corre-
ing slit, this cross-scan is not always perpendicular to the
lations in time: measurement vectors x 1 and x 2 for different
ground track but can come within about 20◦ of being par-
time spans are assumed to have errors that are uncorrelated
allel to it (Eldering et al., 2017). Thus, OCO-2 senses only a
with each other, while the elements of a measurement vec-
very thin swath, up to 10 km wide, but which may be as thin
tor (at possibly different times inside the same time span)
as only 2 or 3 km at near-sub-solar latitudes. The satellite’s
are permitted to have any nonzero correlations, as long as
FOV moves at ∼ 6.75 km s−1 along-track. Across a single
they may be described by an error covariance matrix. This as-
second, then, OCO-2 takes up to 24 measurements across a
sumption of uncorrelated errors between different time spans
quadrilateral with sides of 10 and 6.75 km, flattened to dif-
is built into the derivations of these inverse methods explic-
ferent degrees around the orbit. Not all of these 24 FOVs
itly, for example in the Kalman filter, in which the dynam-
produce reliable retrievals due to clouds, high aerosol optical
ical errors related to propagating the measurement informa-
depths, or other problems that prevent the scene from passing
tion from time to time are assumed to be uncorrelated with
the quality filters (xco2_quality_flag = 0 indicating a “good”
the measurement errors themselves (see Eq. 7.2-3 in Catlin,
scene).
1989, and Eq. 4.2-11 in Gelb, 1974). The more general case,
Suppose we want to average the OCO-2 measurements
in which errors between measurements at different times are
across some distance along-track that will be closer to the
considered to be correlated, may be written out and solved
grid box size of the typical atmospheric transport model used
(see, e.g., Bennett, 2002, Sect. 1.5.3), but the greater com-
in global flux inversion studies (hundreds of kilometers on a
putational complexity and workload involved, coupled with
side). The OCO-2 flux inversion MIP has averaged across a
a general lack of knowledge as to what the temporal corre-
10 s (67.5 km) swath, so we will use that here. If we form a
lations ought to be assumed to be, result in the more simple
vector x ≡ [X1 , X2 , . . ., XJ ]T of J (out of 240) “good” re-
forms being used more generally.
trieved XCO2 values to be averaged in our 10 s span, then
This same philosophy of considering the error correlations
between measurements within a given time span, but neglect-
ing them between time spans when assimilating them into
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022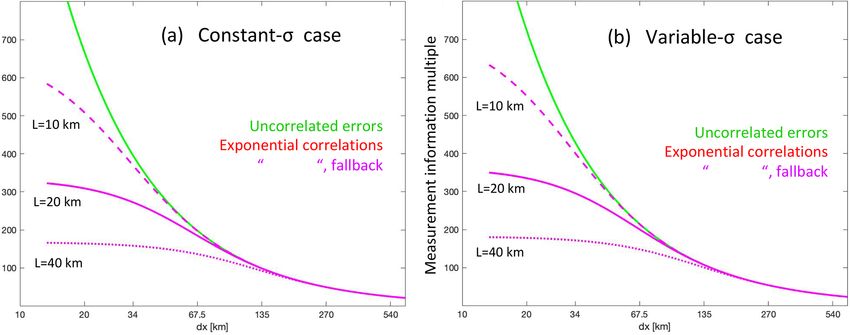
D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them 655
their weighted average is calculated as If σj = σo √for all j , this gives the well-known result that
PJ σindp = σo / J .
wT x j =1 wj Xj One might use the straight information-weighted average
X = T = PJ , (5)
w 1 given by Eq. (8) even in cases in which the errors are known
j =1 wj
to be correlated but when no good model for those corre-
with 1 being a vector of ones. Choosing weights w = lations is available. In such a case, one could calculate an
R−1 1 gives the scalar version of the sort of measurement average uncertainty on the mean as follows:
information-weighted average shown in Eq. (3), which al- s
lows correlations between measurement errors within a given −2 1 X −2 J
σavg = σj → σavg = P −2 . (10)
measurement span to be considered by specifying nonzero el- J σj
ements on the off-diagonal portion of the measurement error
covariance matrix R. Suppose we break out the error covari- This gives an average uncertainty on the mean that is simi-
ance R into a form that explicitly represents the correlations lar in magnitude to the uncertainties of the averaged values
as R = SCS, where C is the correlation matrix, with ones on rather than an uncertainty that decreases to reflect the sum of
the main diagonal and the correlation coefficients between the incoming information. This former approach was the one
the elements of measurement error dx on the off-diagonals, used in the first attempt to compute 10 s averages from the
and where S = diag[σ1 , σ2 , . . ., σJ ]. The general form for the OCO-2 XCO2 data (using the version 7 release) – see Crow-
average then becomes ell et al. (2019) for details.
1T R−1 x (S−1 1)T C−1 S−1 x s T C−1 S−1 x 3.1.2 Averaging assuming constant correlations not
X= T
= T
= , (6) depending on distance
1 R−1 1 −1 −1
(S 1) C (S 1) −1 s T C−1 s
where s = [σ1−1 , σ2−1 , . . ., σJ−1 ]T and with the uncertainty in Suppose that the error on each retrieval inside the averaging
X found from span is correlated with the error in every other retrieval inside
the span with the same correlation coefficient, c, such that we
s T C−1 S−1 s T C−1 S−1 T
have the J × J correlation matrix.
σX2 = E (dX)2 = T −1 E dxdx T
s C s s T C−1 s
1 c ... c
1 c 1 ... c
= T −1 2 (s T C−1 S−1 )(SCS)(S−1 C−1 s)
(s C s) C= . . . (11)
.. .. . . ...
1
= T −1 . (7) c c ... 1
s C s
Whether we want to consider correlations between these If we define H to be a J × J matrix with ones in every ele-
averages X inside a given orbit is a separate matter. We might ment, then C = (1−c)I+cH, and (noting that H2 = J H) we
be forgiven from considering them to be independent in light get
of the choices made in the estimation methods themselves,
especially if the along-track averaging length were to be long −1 1 c
C = I− H . (12)
compared to the dominant error correlation length scale. But 1−c J c + (1 − c)
more on that later (in Sect. 3.4).
Solving Eqs. (6) and (7) with this for C−1 gives
In the following subsections, we consider three different
averages defined by Eq. (6), each using a different form for P P
c
xj /σj2 − J c−(1−c) σj−1
P
the correlation matrix C. xj /σj
X flatc = P 2 , (13)
P −2
3.1.1 Averaging assuming uncorrelated errors
c
σj − J c+(1−c) σj−1
X 2
−2 1 c X
If the data values going into the average are assumed to have σflatc = σj−2 − σj−1 . (14)
independent errors, setting the correlations to zero (C = I) 1−c J c + (1 − c)
gives Based on work done by Susan Kulawik examining cor-
relations between the OCO-2 retrievals, TCCON, and in
σj−2 Xj
P
X indp = P −2 , (8) situ aircraft measurements (personal communication, mid-
σj March 2019), we used the following positive OCO-2 mea-
−2
X surement correlation values in the MIP.
σindp = σj−2 . (9)
+0.3 over land
The summations here and hereafter are taken over j = c= +0.6 over water (15)
1, . . ., J , unless otherwise indicated, to simplify the notation.
+0.6 for mixed land/water (data_type = 9)
https://doi.org/10.5194/gmd-15-649-2022 Geosci. Model Dev., 15, 649–668, 2022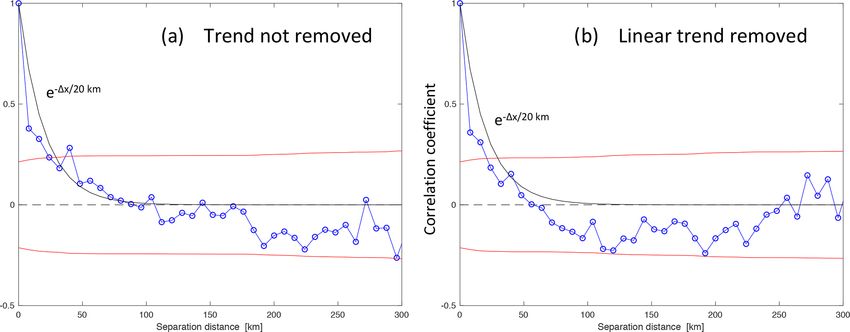
656 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
1 JX −1
c 2
3.1.3 Averaging assuming correlations that decay −2 1
σclen = σ1−2 + − (22)
exponentially with distance 1 − c2 j =1 σj +1 σj
If an error correlation length, L, is known, consider a 1-D −2 sT
σclen Xclen = s T C−1 S−1 x =
error correlation model with positive correlations of the form 1 − c2
−1x
c = e L . We will use the correlation length scale calculated s1 x1 − cs2 x2
for OCO-2 from the MFLL measurements for L. If we have (1 + c2 )s2 x2 − c(s1 x1 + s3 x3 )
J points to be averaged, spaced equally in the along-track (1 + c2 )s3 x3 − c(s2 x2 + s4 x4 )
direction and separated by distance 1x, then we have × .. (23)
.
c2 c3 cJ −1 (1 + c2 )sJ −1 xJ −1 − c(sJ −2 xJ −2 + sJ xJ )
1 c ...
c 1 c c2 ... cJ −2 −csJ −1 xJ −1 + sJ xJ
c2
c 1 c ... cJ −3
1
C=
c3 c2 c 1 ... cJ −4 ,
(16) = (s1 x1 − cs2 x2 )s1 + (sJ xJ − csJ −1 xJ −1 )sJ
1 − c2
.. .. .. .. .. ..
. . . . . . JX−1 h i
2 2
cJ −1 cJ −2 cJ −3 cJ −4 ... 1 + (1 + c )sj xj − c(sj −1 xj −1 + sj +1 xj +1 )sj (24)
j =2
with C−1 having the following convenient tridiagonal form:
"
J JX −1 JX −1
1 X
2 2 2
= sj xj + c sj xj − c sj xj sj +1
1 1 − c2 j =1 j =2 j =1
C−1 =
1 − c2 X J
#
−c sj xj sj −1 (25)
1 −c 0 0 ... 0 0
−c 1 + c2 −c 0 ... 0 0 j =2
1 + c2
0 −c −c ... 0 0 JX −1 h
1 2 2
× 0 . (17) = (1 − c )s x + c2 sj2 xj
0 −c 1 + c2 ... 0 0 1 − c2 1 1
. .. .. .. .. .. .. j =1
..
. . . . . . i
0 0 0 0 ... −c 1 −csj sj +1 (xj + xj +1 ) + sj2+1 xj +1 (26)
(Note that Chevallier, 2007, handled exponentially decaying
"
−2 x1 1 JX −1
c2 xj c(xj + xj +1 )
correlated errors as well and used a similar tridiagonal matrix σclen Xclen = 2+ −
σ1 1 − c2 j =1 σj2 σj σj +1
for the inverse of the covariance.)
Plugging this form for C−1 into Eqs. (7) and (6) gives the xj +1
#
following. + 2 (27)
σj +1
s1 − cs2
(1 + c2 )s2 − c(s1 + s3 ) This gives
−2 sT (1 + c2 )s3 − c(s2 + s4 )
= s T C−1 s = (18) JP
−1
σclen .. (1−c2 )x1 c 2 xj c(xj +xj +1 ) xj +1
1 − c2 . + − +
σ12 σj2 σj σj +1 σj2+1
(1 + c2 )sJ −1 − c(sJ −2 + sJ ) X clen =
j =1
. (28)
−csJ −1 + sJ JP
−1 2
1−c2 c 1
+ − σj +1
1 σ12 σj
= (s1 − cs2 )s1 + (sJ − csJ −1 )sJ j =1
1 − c2
JX
−1 h i To use this 1-D error correlation model for actual OCO-
+ (1 + c2 )sj2 − c(sj −1 + sj +1 )sj (19) 2 data, which may fall as much as 5 km on either side of
j =2 the center of the ground track, some averaging in the cross-
"
J JX
−1 JX −1
track direction must be done first. Once that is done, the data
1 X
2 2 2 could then be averaged in the along-track direction at scales
= s + c s − c sj sj +1
1 − c2 j =1 j j =2 j j =1 of anywhere from 1x = 2.25 km (given by the 3 Hz cross-
J
# track scan frequency) all the way up to the 67.5 km distance
−c
X
sj sj −1 (20) traveled across the 10 s averaging span. To use the 1-D model
j =2
with real data, for which there are data gaps, the missing data
"
JX −1 h
# would be given sj values equal to zero in the formulas above.
1 2 2 2 2 2
i
The local nature of the average in Eq. (28) suggests a sec-
= (1 − c )s1 + c sj − 2csj sj +1 + sj +1 (21)
1 − c2 j =1 ond use of this model: as a pre-conditioner for data to be
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them 657
assimilated retrieval by retrieval (individually, without aver- Thus, most uncertainties that are larger than average (an av-
aging) in an inversion, with each measurement assumed to erage in terms of the inverse of the uncertainty) can cause
have errors independent of all the others. Currently, many in- negative weights.
version schemes ingest the data without averaging, retrieval The exponential correlation model can also yield negative
by individual retrieval, sometimes inflating the uncertainties weights. Taking an interior element of Eq. (18) as a guide,
on individual data in an ad hoc manner to account for corre- we have
lations and sometimes not. Equations (18) and (23) present a
way to adjust the data beforehand so that when they are as- σj−1
wj = (R−1 1)j = (S−1 C−1 s)j = (1 + c2 )σj−1
similated retrieval by retrieval, the correlations are accounted 1 − c2
for in a statistically justifiable manner: pass over the data
−c(σj−1
−1 + σ −1
j +1 ,
) (34)
once before assimilating them, modifying each datum xj and
its associated σj using the two data points on either side of which goes negative when
it, along-track, such that
c
σj−1 < (σ −1 + σj−1+1 )
σ́j−2 = σj−1 [(1 + c2 )σj−1 − c(σj−1 −1 2
−1 + σj +1 )]/(1 − c ) (29) 1 + c2 j −1
−1 −1
x́j = σ́j2 σj−1 [(1 + c2 )xj /σj − c(xj −1 /σj −1 2 σj −1 + σ j +1
= −1 (35)
+ xj +1 /σj +1 )]/(1 − c2 ), (30) c + c+1 2
or (since c = e−1x/L ) when
where the primes indicate the new adjusted values. Rather
than being an approximation, this will give the same answer, cosh(1x/L)
when each datum is assimilated independently, that assimi- σj > . (36)
(σj−1 −1
−1 + σj +1 )/2
lating the original data, with correlations handled properly in
the equations, would give. This condition is violated only somewhat less frequently than
Eq. (33): whenever σj is cosh(1x/L) times greater than a
3.2 Negative weights and their implications similar average (of the inverses) of the uncertainties of the
two neighboring points. When averaging many points at finer
In the definition of a weighted average, the weights on the
scales (1x < L), 1 < cosh(1x/L) < 1.54, and up to half the
averaged values are usually required to be non-negative, with
points will cause negative weights.
at least one weight being positive. Non-negative weights can
A simple example helps explain why the error correlation
cause the averaged value to fall outside the range of the val-
models drive the weights negative and the average value out
ues to be averaged, a result that is generally considered un-
of range of the input values. Consider two data points, each
desirable in an average: the added requirement on the sign
measuring a quantity for which the true value is Xtrue = 0: let
of the weights prevents this. However, under certain condi-
the value and uncertainty on these points be x1 = 1, x2 = −1,
tions the average values given by Eqs. (13) and (28) can give
σ1 = σ2 /β. The error covariance matrix, given by
negative weights in Eq. (5) and out-of-range average values.
This out-of-range behavior was discovered when the con-
σ1 0 1 c σ1 0
stant correlation model from Sect. 3.1.2 was applied to the R= , (37)
0 σ2 c 1 0 σ2
OCO-2 v9 XCO2 data by the OCO-2 flux inversion MIP team.
The weights R−1 1 for that model are describes the (correlated) errors: the differences between the
measurements and the truth, which, since the truth equals
1 −1 c zero, are just the values of the measurements themselves.
w = R−1 1 = S I− H S−1 1, (31)
1−c J c + (1 − c) Then
σ1−2 σ1−1
−1
1 σ1 0 1 −c
σ2−2 σ2−1 X
J R−1 =
1 c/(1 − c) 1 − c2 0 σ2−1 −c 1
= .. − .. σj−1 , (32)
1−c . J c + (1 − c) . j =1
−1
σ1 0
× . (38)
σJ−2 σJ−1 0 σ2−1
any element of which can go negative when σi−1 < Plugging this into Eq. (6) gives the correlated mean.
1 PJ −1
1
J −1+ c j =1 σj or σ1−2 − σ2−2 σ1−2 − 2cσ1−1 σ2−1 + σ2−2
X= /
!−1 1 − c2 1 − c2
J
1 X σ1−2 − σ2−2 β2 − 1
σi > 1
σj−1 . (33) = = (39)
J −1+ c j =1 σ1−2 − 2cσ1−1 σ2−1 + σ2−2 β 2 − 2cβ + 1
https://doi.org/10.5194/gmd-15-649-2022 Geosci. Model Dev., 15, 649–668, 2022658 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
For β = 1 (both uncertainties being the same), X = 0 for all one might expect that the uncertainties on the mean obtained
values of the correlation coefficient, c, except c = ±1. But would be higher than those given by Eq. (14) or Eq. (22).
for β > 1, X moves more positive, closer to the measurement In general, if Cw is the correlation model assumed in set-
with more information or lower uncertainty, until β = 1/c, at ting the weights for the average and Cerr the correlation
which point X = +1 = x1 . For larger β values, X > 1, which model assumed for the actual errors dx, then
is outside the range of the two data values being averaged.
Apparently, the correlated average, taking a clue from the s T C−1
w S
−1 S−T C−1
w s
σ 2 = E[dxdx T ] = E[dx(dx)T ]
value of the higher-uncertainty input, x2 , believes that the er- s T C−1
w s s T C−1
w s
rors on both x2 and (because of the positive correlation) x1 1
are negative (x2 being negative) and corrects for these errors = s T C−1 −1 T −T −1
w S [SCerr S ]S Cw s, (40)
(s T C−1
w s)2
by choosing a more positive value to the average value than
the relative weighting of the two measurements, if uncorre- s T C−1 −1
w Cerr Cw s
= . (41)
lated, would otherwise require. When the difference between (s T C−1
w s)
2
the uncertainties, β, is large enough (compared to 1/c), the
average value is driven outside the range of the input values. 3.2.1 Constant error correlation case with sub-optimal
The weight on x2 is driven negative to achieve this. For this average
error correlation model, all this makes sense.
When the OCO-2 flux inversion MIP group encountered
If the correlated averages given by Eqs. (13) and (28) are
this out-of-range negative weight problem when applying
physically realistic, why not use them, even if they do not
Eq. (13) to the OCO-2 v9 XCO2 data, this was in fact the
conform to the usual requirements of the weighted average?
work-around that we fell back to: the mean was specified by
If it is clear that one’s chosen model for the error correlations
Eq. (8), but the errors between individual retrievals were as-
is correct, then yes, they should be used. But if one is not
sumed to be correlated according to the constant error cor-
entirely sure of the model, that might be one reason to be
relation model from Eq. (11) (Peiro et al., 2021). Setting
hesitant to accept an average value that falls outside the range
Cw = I and Cerr = [(1 − c)I + cH] allows the uncertainty on
of the inputs. Is there an intermediate approach to fall back
the mean to be computed as
on that enforces the usual non-negative weight constraint for
the average while still garnering the benefits of the correlated 2 1 1
error models? One could try discarding the retrievals with σflatc2 = s T [(1 − c)I + cH] s =
(s T s)2
2
σj−2
P
higher retrieval uncertainties σj that seem to be driving the
weights negative. X X 2
In the case of the constant correlation model, this would σj−2 + c
(1 − c) σj−1
be impractical, as roughly half of the retrievals would have P 2
above-average σj values, and if those were thrown out, half σ −1
1 j
of the remainder would have to be thrown out, and so on. For = P −2 (1 − c) + c P −2 .
(42)
the exponential correlation model, however, a sort of filter- σj σj
ing approach might be feasible when cosh(1x/L) is signifi-
cantly above 1 (i.e., for 1x values approaching L): one could In terms of the measurement information, this gives
throw out the retrievals with anomalously high σj values to
σj−2
P
the point that σj varied smoothly enough from retrieval to
−2
retrieval to ensure that the condition in Eq. (36) would never σflatc2 = P 2 . (43)
σj−1
be violated. This might be practicable for spans with sparser (1 − c) + c P −2
data (longer 1x values) or when averaging together data that σj
had already been binned together at finer scales.
3.2.2 Exponentially decaying error correlation case
As an alternative to using the negative weight criterion as a
with sub-optimal average
(possibly harsh) data filter, one might specify the form of the
weighted average a priori in a way that forces the weights to If one falls back to using Eq. (8) to calculate the means but
be positive rather than letting the weights be determined in- still uses the exponential error correlation model, then (set-
directly by specifying the correlation model as we have done ting Cerr = C from Eq. 16) the uncertainty on the mean is
above. For example, one could specify the form of the aver- −1x
computed (with c = e L ) as follows.
age to be the information-weighted mean given in Eq. (8),
but then impose the correlated error assumptions of one’s
choice when calculating the uncertainty on that mean. Since
the mean given by Eq. (8) would, in general, no longer be
the optimal (minimum variance) value for that error model,
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them 659
we specified the weighted averaged to be given by Eq. 8 then
1
computed its uncertainty using the correlated errors) are also
2
σclen2 = sT shown in Fig. 2. For the exponential correlation model, the
(s T s)2
fallback approach (magenta lines) results in only slightly less
1 c c2 c3 ... cJ −1 information (or higher uncertainty) for the average compared
c 1 c c2 ... cJ −2 to the original approach (red lines). For the constant correla-
c2 c 1 c ... cJ −3 tion fallback model (cyan lines), the loss of information is
× c3 c2 c 1 ... cJ −4 s
.. .. .. .. .. greater, though this is seen only in the variable-σ case, with
..
. . . . . . the two models giving the same result in the constant-σ case.
cJ −1 cJ −2 cJ −3 cJ −4 . . . 1
"
J JX
−1 JX −k
# 3.4 Calculating correlations between averaging spans
1 X
−2 k −1 −1
= 2 σj + 2 c σj σj +k (44)
PJ −2 Above we have accounted for correlated errors between the
j =1 σj
j =1 k=1 j =1
retrievals going into the 10 s averages. The same 1-D error
Or, in terms of measurement information, correlation model developed above can also be used to com-
pute the correlations between adjacent 10 s average spans if
PJ −2
j =1 σj
an error correlation length scale is known. In that case, the
−2
σclen2 = hP i P . (45) spacing 1x between the data assumed in Sect. 3.1.3 and 3.2.2
J −1 k PJ −k −1 −1 J −2
1+2 k=1 c j =1 σj σj +k / j =1 σj is no longer the spacing between individual retrievals but
rather the spacing between the different 10 s average spans
3.3 Comparison of the error models for two simple along the ground track of the satellite.
cases Suppose we look at the daylit side of a single OCO-2 orbit,
which we will assume encompasses a third of the full orbit,
We look now at the uncertainty estimates that the error
or about 13 358 km; there are about 198 10 s spans inside it.
models above give for two simple example cases (Tables 2
If we let 1x = (13 358 km)/J , then we may use Eq. (22) or
and 3): one in which all σj = σo , a constant value, and a
(45) again to compute the total information across the orbit.
second in which σj−1 varies across the sample as σj−1 =
h i Figure 3 plots this information content for the two simpli-
σo−1 21 + Jj −1
−1 . Both cases may be solved analytically. fied error cases used above as a function of 1x: for our 10 s
−2 /σ −2 for each of these correlation
In Fig. 2, we plot σavg averages, we look at 1x = 67.5 km, finding that the total in-
o
models as a function of the data spacing 1x for the two sim- formation multiple is about 200 for the uncorrelated error
ple example cases. For the exponential correlation model, case (green line), which is close to the J = 198 value, as it
where c = e−1x/L , we divide the 10 s swath into equal incre- should be. By comparing the information values for the un-
ments 1x = (67.5 km)/J . For the other error models, which correlated error case (green line) to the values from the expo-
use the number of averaged values J rather than 1x, we cal- nential correlation cases (red and magenta lines), we can see
culate J = 67.5 km)/1x for each point on the x axis, an as- the impact of the correlations in reducing the total informa-
sumption that forces all the data to be equally spaced along- tion content in the lower 1x range. Curves for three different
track for those models, too, in these plots. The average uncer- correlation lengths (10, 20, and 40 km) are given; curves for
tainty (dashed black) and independent error (green) models measurement errors for the two different formulations of the
bound the possible information range as a function of 1x, mean (from Eqs. 22 and 45, the red and magenta curves in
with the independent case setting the maximum. There is Fig. 2) are both plotted but fall on top of each other in this
more variation with J for the variable uncertainty case: for 1x range. By comparing the information assuming no cor-
both simple models, there is a tendency for the constant cor- relations (green) versus exponential correlations (magenta),
relation model to provide more rapidly increasing measure- one can derive a single scalar multiple (greater than 1) of the
ment information at smaller 1x than in the exponential cor- uncertainties on the 10 s averages that will permit the 10 s
relation model: this is to be expected, since the correlations averages to be assimilated in an inversion scheme with the
in the latter when 1x < 20 km are higher than the +0.3 cor- assumption that they are all independent, but this will yield
relation level used in the constant correlation model. In gen- the same amount of total measurement information entering
eral, the constant and exponential correlation models provide the problem as would have been obtained if the correlations
similar results, other than at the smallest 1x. The total infor- had been accounted for properly using the original uncertain-
mation content of the average is limited by the correlations to ties. Using such an inflation factor is generally much easier
only about 3 times that of the typical individual measurement than implementing the machinery for accounting for the cor-
when assuming an error correlation length scale of 20 km. relations properly in the inversion code.
The results for the fallback approaches for the constant and
exponential correlation models that we derived in Sect. 3.2.1
and 3.2.2 to get around the negative weight issue (in which
https://doi.org/10.5194/gmd-15-649-2022 Geosci. Model Dev., 15, 649–668, 2022660 D. F. Baker et al.: Error correlations in OCO-2 XCO2 data and how to average them
Table 2. The analytical expressions for the uncertainty on the average given by each correlation model for a simple case in which all
measurement uncertainties have the same constant value, σo .
−2 −2
Correlation model Equation Result for σj = σo σavg /σo
−2
Independent errors (9) σindp = J σo−2 J
−2
Information-averaged uncert. (10) σavg = J1 J σo−2 1
h i
−2 1 J σ −2 − c −1 2 J
Constant correlations (14) σflatc = 1−c o J c+(1−c) (J σo ) 1+c(J −1)
−2 J σo−2 J
” ” , fallback weights (43) σflatc2 =
(J σ −1 )2 1+c(J −1)
(1−c)+c o−2
J σo
−2 −2
Correlation length scale (22) σclen = 1 + (J − 1) 1−c
1+c σo 1 + (J − 1)tanh( 1x
2L )
J σo−2 J tanh 1x
2L
−2
” ” , fallback weights (45) σclen2 = −J 1x/L
1+ J2 Jk=1
P −1
(J −k)ck 1− 1−e csch 1x
J L
Table 3. The analytical expressions for the uncertaintyhon the average
i given by each correlation model for a simple case in which the inverse
of the measurement uncertainty varies as σj−1 = σo−1 21 + Jj −1
−1 .
h i
Correlation model Equation Result for σj−1 = σo−1 12 + Jj −1
−1
−2 −2
σavg /σo
−2
= σj−2
P
Independent errors (9) σindp α
−2
= J1 σj−2 α
P
Information-averaged uncert. (10) σavg J
J 2c
h P −1 2 i
−2 1 P σ −2 − c 1
Constant correlations (14) σflatc = 1−c j J c+(1−c) ( σj ) 1−c α − J c+1−c
σj−2
P
−2 α
” ” , fallback weights (43) σflatc2 = P 2 2
σj−1 1−c+ Jα c
(1−c)+c P −2
σj
2γβ+γ 2 σ1−2 +σJ−2
γ2
Correlation length scale (22) −2
σclen = 12 + 1 PJ −1 − σj 2γ 1
σj +1 + σ 2
α
tanh(1x/L) −
σ1 1−γ 2 j =1 σj2 j +1
1−γ 2
P 2
σj−2
−2 α
” ” , fallback weights (45) σclen2 =P P
J −1 k PJ −k −1 −1
h
1−γ J −1
i
σj−2 +2 k=1 c j =1 σj σj +k 1+ 2γ
α
2 1 2 2 1
1−γ Jf − 3 1−γ 2 J f g+ 3 (1−γ )4 h
h i
J 13J −11 , β = 1 1 1 1 −1x/L ,
α = 12 J −1 J −1 4 (J − 1)(J − 3) + 2 J (J − 2) + 6 J (2J − 1) , γ = e
f = (J − 3)2 + (J + 1)(10J − 16)/3, g = 1 − J γ J −1 + (J − 1)γ J ,
h = (1 + 4γ + γ 2 )g − J (J − 1)γ J −1 (1 + 2γ + J (1 − γ ))(1 − γ )2
3.5 Application of the error correlation models to the cross-track dimension (10 km) somewhat, we average all
OCO-2 v10 XCO2 data the OCO-2 v10 XCO2 data values (Baker et al., 2020) falling
inside each 2 s span (spaced 1x = 13.5 km apart, along-
To apply the exponential error correlation models presented track) in this manner. We could then apply any of the error
in Sect. 3.1.3 and 3.2.2, one must somehow account for the correlation models that we have discussed so far (constant
fact that the real OCO-2 data are not one-dimensional but or exponential using the original or fallback forms for the
fall up to 5 km on either side of the center of the OCO-2 weighted means) to the five 2 s average values falling inside
FOV ground track. As Fig. 2 shows that there is little inde- each 10 s span to get the 10 s averages. As shown in Fig. 1,
pendent information obtained from data spaced at 1x values the MFLL–OCO-2 spectrum suggests that the error correla-
much below the correlation length scale L, one would be jus- tions fall off even more rapidly at small 1x than the 20 km
tified in computing an average value at scales that fine using correlation length that we decided was the best fit to the data
the independent error Eq. (8) and then applying a constant- across the full 1x range would suggest: we use a 10 km cor-
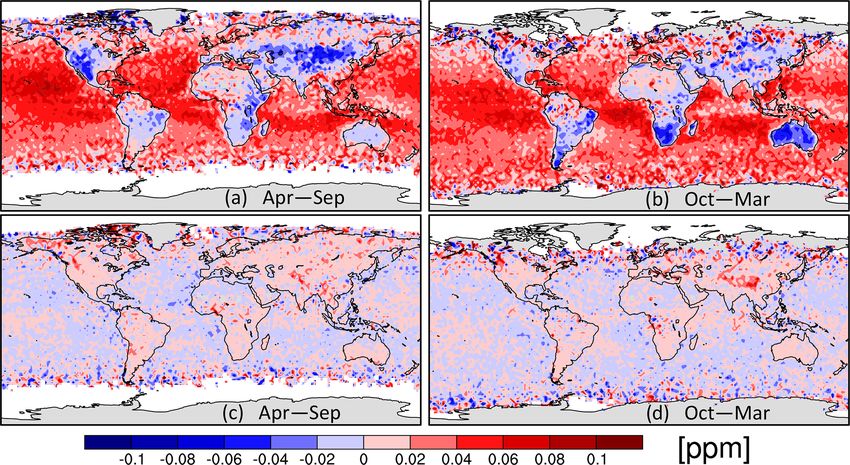
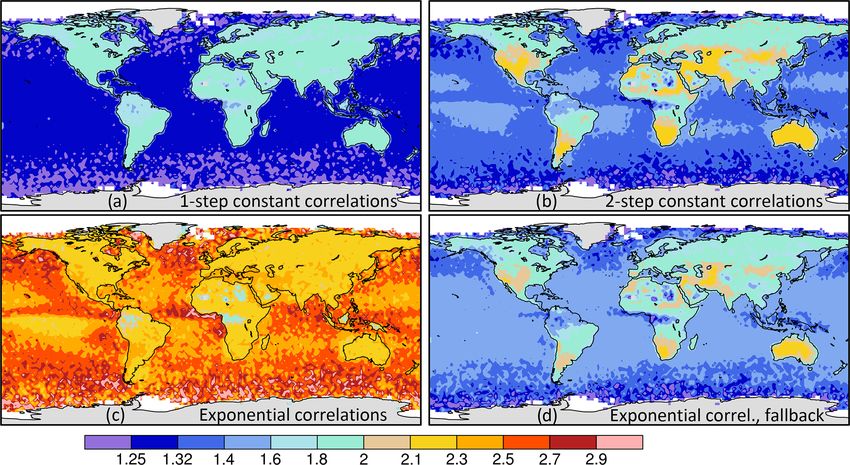
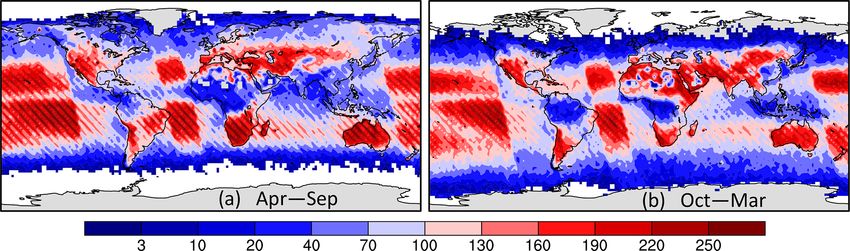
correlation-based uncertainty to it using Eq. (43). To match
Geosci. Model Dev., 15, 649–668, 2022 https://doi.org/10.5194/gmd-15-649-2022You can also read

















































