UFO-VIT: HIGH PERFORMANCE LINEAR VISION TRANSFORMER WITHOUT SOFTMAX
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

UFO-ViT: High Performance Linear Vision Transformer without Softmax
Jeong-geun Song
Kakao Enterprise
po.ai@kakaoenterprise.com
PREPRINT
arXiv:2109.14382v1 [cs.CV] 29 Sep 2021
Abstract
Vision transformers have become one of the most im-
portant models for computer vision tasks. While they
outperform earlier convolutional networks, the complexity
quadratic to N is one of the major drawbacks when using
traditional self-attention algorithms. Here we propose the
UFO-ViT(Unit Force Operated Vision Trnasformer), novel
method to reduce the computations of self-attention by elim-
inating some non-linearity. Modifying few of lines from
self-attention, UFO-ViT achieves linear complexity without
the degradation of performance. The proposed models out-
perform most transformer-based models on image classi-
fication and dense prediction tasks through most capacity
regime.
1. Introduction
Recently, several results of transformers[10, 37, 42, 32, Figure 1: ImageNet1k Top-1 Acc. vs. FLOPS. Xmeans
19, 14, 12] have shown many breakthroughs in vision tasks distilled model.
as well as in natural language processing. The vision
transformer[10] shows better scalability with large dataset
by removing inductive bias of CNN-based architectures. In We suggest simple alternative self-attention mechanism
recent studies, transformer-based architectures renew the to avoid those two major drawbacks. It is called Unit Force
state of the art on image classification, object detection and Operated Vision Transformer, or simply UFO-ViT. This
semantic segmentation[2, 26, 41, 49, 51], and generative method eliminates softmax function to use associative law
models[23, 13, 11]. of matrix multiplication. It is not a kind of approximation
Transformer-based models have been shown competi- but similar to low rank approximation. It has been presented
tive performance compared to earlier state-of-the-art mod- at Performer[19] and Efficient Attention[31] earlier. Here
els. Despite their great successes, the models using self- we suggest another mechanism to drop the softmax function
attention have well-known drawbacks. One is that self- by two-step L2 -normalization, called XNorm. It can com-
attention mechanism has time and memory complexity pute self-attention with linear complexity, exploiting asso-
quadratic to N . When computing self-attention, QK T ∈ ciative law as mentioned above.
RN ×N is multiplied to value matrix to extract pairwise Unlike previous results of linear approximation meth-
global relations. It could be critical issue on the tasks that ods, UFO-ViT achieves higher or competitive results on
require high resolution, i.e., object detection or segmenta- benchmarks of vision tasks compared to the state of the
tion. If width and height is doubled, self-attention requires art models. It is detailed in Section 4, including results
16 times of resource to compute. Another major issue is on ImageNet1k[9] and COCO benchmarks[25]. It has been
about data efficiency. ViT[10] has to be pre-trained using obtained without any extra dataset like JFM-300M or Ima-
large extra dataset to achieve competitive performance com- geNet21k.
pared to CNN-based architectures. Our approaches have contributions as follows:
1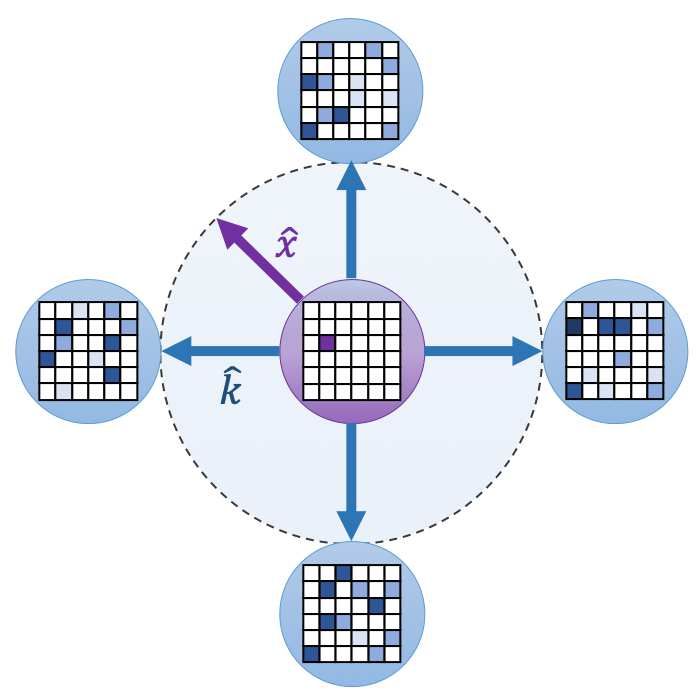
1. We propose novel constraint scheme, XNorm, which duce the computation except using small channels. Zhang
generates unit hypersphere to extract relational features. et al.[50] propose the nested self-attention structure. They
Detailed in Section 3, it prevents self-attention from being split the patches to several blocks and apply local attention
dependent to initialization. Furthermore, it has O(N ) com- to them. At the end of the stage, blocks are flatten and
plexity, handling high resolution input efficiently. pooled by convolution with stride 2. Above this, various
2. We demonstrate UFO-ViT can be adopted to general patch merging methods are introduced[3].
purpose. Our models are experimented on both image clas- Different methods to integrate convolutional layers[19,
sification and dense prediction tasks. Even it uses linear 41, 14, 12, 44, 15] are introduced too. LeViT, designed
self-attention scheme, UFO-ViT models outperform most by Graham et al.[14] applies multi-stage networks to trans-
of state-of-the-art models based on transformer at lower ca- formers, inspired by common structure of early CNN-based
pacity and FLOPS. Especially, our models perform well in networks. Xiao et al.[44] have found that to replace lin-
lightweight regime. ear patch embedding layers to convolutions helps the trans-
3. We propose new module which can process input im- formers capture the better features. At XCiT[12], El-Nouby
age dynamically. It means the size of weights are irrele- et al. introduce local patch interaction. By adding two
vant to the input resolution. It is useful at dense prediction depthwise convolutions[6] after XCA, XCiT achieves bet-
tasks like object detection or semantic segmentation which ter performance. From another point of view, alternative
usually requires higher resolution compared to pre-training self-attention method is introduced by Chu et al[8]. Their
stage. For MLP-based structures[35, 36], post-process is model uses global attention and local attention together.
required if the model is pre-trained on different resolution. For data efficiency, our models are mostly inspired by in-
trinsic optimization strategies XCiT[12] presents. But UFO
2. Related Works scheme is not based on their method, as detailed in follow-
Vision transformers. Dosovitskiy et al.[10] has shown ing paragraph.
potential of transformers in vision. After the achieve- Efficient self-attention. Instead of architectural strate-
ments of ViT, DeiT[37] introduced the most efficient train- gies, several approaches are proposed to directly solve
ing strategies for vision transformer by detailed ablation O(N 2 ) problem of self-attention mechanism. They are
studies. They have solved the data efficiency problem of summarized to some categories; Special patterns[20, 5, 33],
ViT successfully and most of concurrent transformer-based exploiting associative law[7, 31], using low rank factor-
models have been following their schemes. ization method[40], linear approximation through sampling
In further researches, various architectural strategies to important tokens[24, 46], and using cross-covariance matri-
improve training stability have been presented. Touvron ces instead of Gram matrices[12]. Although detailed meth-
et al.[38] propose two simple modules to train deep vision ods are quite different, our UFO scheme is mainly related
transformer models. One is class attention layers, which is to utilizing associative law.
additional self-attention modules for the class token only.
Proposed modules help the class token aggregate features 3. Methods
from the patches by detaching them from main modules.
Another is LayerScale module. They claims that it helps The structure of our model is depicted in Figure 2. It is a
larger transformer models generalize better by scaling resid- mixture of convolutional layers, UFO module, and a simple
ual connections. Simple modified version of that has pre- feed-forward MLP layer. In this section, we point out how
sented at ResMLP[36], which is LayerScale with the bias our proposed method can replace the softmax function and
term. While MLP-based models are not directly related to ensures linear complexity.
our models, we adopt Affine modules to our model for scal-
ing normalized heads and residuals. Module Type Complexity
Hybrid architectures. To solve several limitations of ViT[10] O(N 2 d)
transformers, designing schemes used in CNNs are re- Linformer[40] O(kN d)
visited on further works. Liu et al.[26] propose the shifting
window and patch merging. It generates hierarchical fea-
Efficient Attention[31] √ d)
O(hN
Axial[20] O(N N d)
tures by grouped attention and gradually merges the patches
XCiT[12] O(N d2 )
to shrink the input resolution. This methods help self-
UFO-ViT O(hN d)
attention modules learn local structures as well as reduce
the computation. Tokens-to-token ViT, introduced by Yuan Table 1: Complexity of self-attention methods. h means
et al.[48], aims similar problem with different approaches. hidden dimension of key-query-value.
They present the method overlapping tokens to correlate
patches locally. But they do not use special tricks to re-
2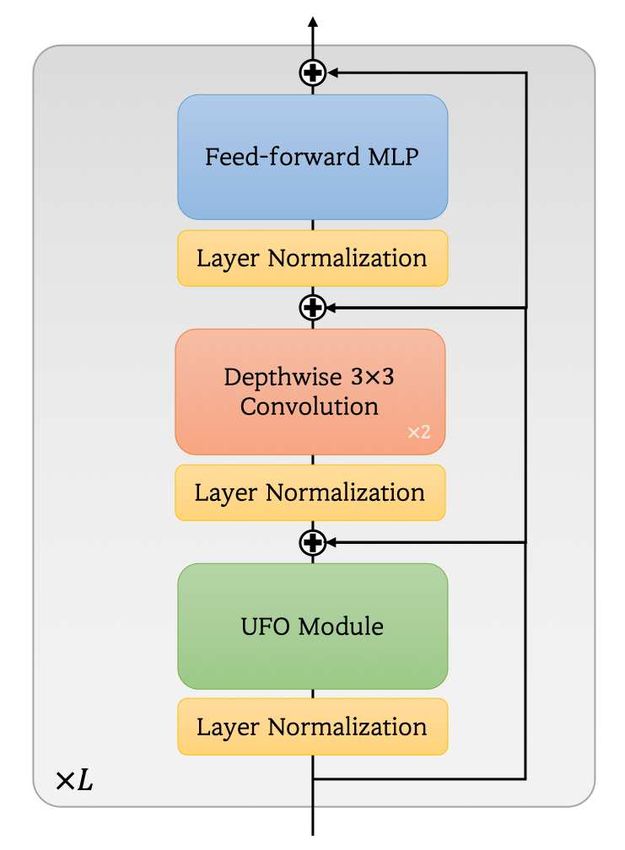
Figure 4: Centroids generating harmonic potentials.
Each patch, represented as a particle, is interfered by
parabolic potentials generated from h clusters.
Figure 2: Overview of UFO-ViT module. Note that affine XNorm, is defined as follows:
layers[36] are following each module. A(x) = XNdim=filter (Q)(XNdim=space (K T V )) (3)
γa
XN(a) := qP (4)
h
i=0 ||a||2
where γ is a learnable parameter and h is the number of
embedding dimension. It is simple L2 -norm, but it is ap-
plied along two dimensions; Spatial dimension of K T V
and channel dimension of Q. That is why it is called cross-
normalization.
Using associative law, key and value are multiplied first
and query is multiplied after. It is depicted at Figure 3. Both
Figure 3: UFO module. multiplication has complexity of O(hN d), so this process is
linear to N . (To compare with other methods, see Table 1.)
3.2. XNorm
3.1. Theoretical Interpretation Replace softmax to XNorm. Key and value multiplied
N ×C directly in our process. It is same with linear kernel method,
For an input x ∈ R , traditional self-attention mech-
generating h clusters.
anism is formulated as follows:
n
X
p
T [K T V ]ij = T
Kik Vkj (5)
A(x) = σ(QK / dk )V (1) k=1
Q = xWQ , K = xWK , V = xWV (2)
XNorm applied to both query and output.:
q̂0 · k̂0 q̂0 · k̂1 · · · q̂0 · k̂h
where A denotes the attention operator.
q̂1 · k̂0 q̂1 · k̂1 · · · q̂1 · k̂h
σ(QK T )V cannot be decomposed to O(N × h + h × A(x) = .
(6)
.. .. ..
N ) because of non-linearity of softmax. Our approach is .. . . .
eliminating softmax to compute K T V first with associative q̂N · k̂0 q̂N · k̂1 · · · q̂N · k̂h
law. Since applying identity instead causes degradation, we
q̂i = XN[(Qi0 , Qi1 , · · · , Qih )] (7)
suggest simple constraint to prevent it.
T T T
Our proposed method, called cross-normalization or k̂i = XN[([K V ]0i , [K V ]1i , · · · , [K V ]hi )] (8)
3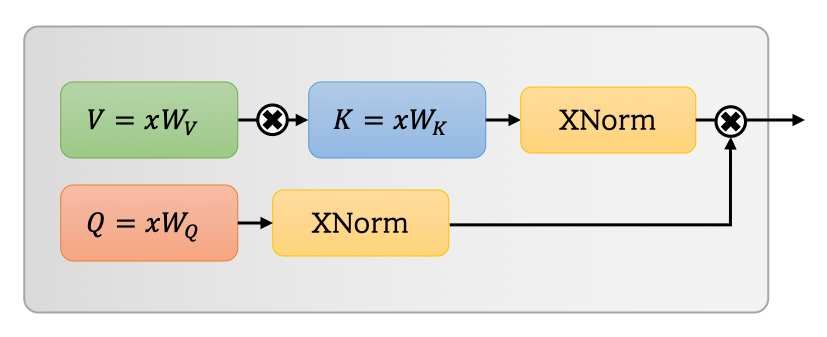
Model Depth #Dim #Embed #Head GFLOPS Params (M) Res. Patch Size
UFO-ViT-U 12 192 96 4 1.0 5.6 224 16
UFO-ViT-T 24 192 96 4 1.9 10.0 224 16
UFO-ViT-S 12 384 128 8 3.7 20.7 224 16
UFO-ViT-M 24 384 128 8 7.0 37.3 224 16
UFO-ViT-B 24 512 128 8 11.9 63.7 224 16
UFO-ViT-L 12 384 128 8 14.3 20.6 224 8
UFO-ViT-XL 24 384 128 8 27.4 37.3 224 8
Table 2: UFO-ViT models.
where x denotes the input. Finally, projection weight scales Above formulation is generally used to approximate po-
and aggregates them by weighted sum. tential energy of molecule at x ≈ 0. For multiple molecules,
using linearity of elasticity,
h
X n
[Wproj A(x)]ij = wmj q̂i · k̂j (9) X
m=1
F=− ki · x (15)
i=1
In this formulation, relational features are defined by co-
It is similar equation to Eq.9 except that above formula
sine similarity between the patches and the clusters. XNorm
is not normalized. (Note that wmj terms are static. They are
restricts the query and clusters to be unit vectors. It prevents
irrelevant to each batch so do not perform significant roles
their values to suppress relational properties, by regulariz-
in this simulation.) Assume that small number of k are too
ing them to narrow range. If they have arbitrary values, the
large. The shapes of their potentials are wide and deep.
region of attention is too dependent on initialization.
(See Eq.14.) If a certain particle moves around them, it is
However, this interpretation is not enough to explain why
not easy for it to escape. In this case, only two cases exist.
XNorm has to be L2 -normalization form. Here we intro-
1. Collapsed. The particles are aligned to the direction of
duce another theoretical view, considering simple physical
the largest k. 2. Relational features are neglected. A few
simulation.
particles with large x are survived from collapsing.
Details of XNorm. Considering residual connection, the
This is exactly same case as mentioned at previous part.
output of arbitrary module is formulated as follows.
XNorm enforces all vectors to unit vector to prevent this
xn+1 = xn + f (xn ) (10) situation. In other words, XNorm is not normalization, but
constraint.
where n and x denote current depth and the input image. If To show this empirically, we have demonstrated that
we assume that x is the displacement of certain object and other normalization methods cannot work well. For detailed
n is time, then above equation is re-defined as: results, refer to our ablation study(See Table 4).
Feed-forward layers(FFN). In attention module, FFN
xt+1 = xt + f (xt ) (11) cannot be ignored. However, there is simple nice interpre-
∆x tation. FFN is static and not dependent to spatial dimension.
f (x) = (12) Physically, this type of function represents driven force of
∆t
harmonic oscillator equation.
Most of neural networks are discrete, so ∆t is constant.
(Let ∆t = 1 for simplicity.) Residual term expresses veloc- F = −k · x + g(t) (16)
ity, and it has same value with force where ∆t = 1. This performs the role of amplifier or reducer, which
In physics, Hooke’s law is defined as dot product of elas- boosts or kills the features irrelevant to spatial relation.
ticity vector k and displacement vector x. The elastic force
generates harmonic potential U , a function of x2 . Phys- 3.3. UFO-ViT
ically, the potential energy interferes the path of particle To build our UFO-ViT model, we adopted some architec-
moving through it. (To easily understand, imagine a ball tural strategies from earlier vision transformer models[14,
moves around a track with parabola shape.) 44, 12, 38]. In this section, we introduce several archi-
tectural optimization techniques. Overall structure is illus-
F = −k · x (13)
trated at Figure 2.
1 2 Patch embedding with convolutions. Recent several
U= kx (14)
2 researches[14, 44] claim that vision transformers are trained
4well with convolutional patch embedding layers, instead of Method Top-1 Acc. (%)
linear projection. Adopting their strategy, we use convolu- Baseline(Linear Embed+XNorm) 81.8
tional layers at the early stage of our models. XNorm → LN[1], GN[43] Failed
Positional encoding. We use positional encoding XNorm → Learnable p-Norm 81.8
as learnable parameters, which Dosovitskiy et al. has XNorm → Single L2Norm Failed
proposed[10] earlier. Using positional encoding does not Linear Embed[10] → Conv Embed 82.0
affect ablation study, but we have decided to add it to pre- +Tuned Hyperparameter 82.8
pare same experimental environment.
Multi-headed attention. Following the original[39], Table 4: Ablation study on ImageNet1k classification.
our modules are multi-headed for better regularization. γ The results of ablation study on UFO-ViT-M. Note that sin-
parameter in Eq.3 is applied to all heads to scale importance gle L2Norm means applying L2Norm to only one of query
of each heads. and key-value interaction. The learnable parameter p of p-
Local patch interaction. It is not special idea re- norm is initialized by 2.
cently to design the extra module to extract local features
for self-attention module. We choose the most simplistic
method among them, 3 × 3 depthwise separable convolu-
tions. Adopting LPI proposed in XCiT[12] early, we use
stacked two Conv-BN[22]-GELU[18] layers.
Feed-forward network. Like traditional transformer-
based models, our model uses a point-wise feed-forward
MLP with 4d hidden dimension.
Class attention. In ImageNet1k experiments, we use
the class attention layers presented in CaiT[38]. It helps the
class token gather spatial information. To reduce compu-
tation, Class attention is computed on class token only. It
is same with the original paper. Note that class attentions
consist of UFO modules, while CaiT uses the normal self-
attention module for class attention.
Hyperparam Model Value
UFO-ViT-S, L, XL 5e-4
learning rate UFO-ViT-M 4e-4
UFO-ViT-B 3.5e-4
UFO-ViT-S, L 0.05 Figure 5: Memory consumption according to the num-
weight decay[27] UFO-ViT-M, XL 0.07 ber of input tokens. Maximum GPU memory allocated
UFO-ViT-B 0.09 using UFO-ViT-M model with 64 batches. It is linear to
UFO-ViT-S, L 0.1 the number of input tokens. We use torch.cuda API
drop path[21] UFO-ViT-M, XL 0.15 PyTorch[29] library provides.
UFO-ViT-B 0.2
UFO-ViT-S/L 1.0
Implementation details. Our setup is almost same with
grad clip[28] UFO-ViT-M, XL 0.7
DeiT[37]. However, we use small learning rate and larger
UFO-ViT-B 0.5
weight decay for up-scaled models for training stability.
Table 3: Hyperparameters for image classification. All (See Table 3 for more details.) The learning rate follows
the other hyperparameters are same as DeiT[37]. linear scaling rule[47], scaled per 512 batch size. We train
our model for 400 epochs with the AdamW optimizer[27].
Learning rate is linearly warmed up during first 5 epochs
and decayed with a cosine schedule after that.
4. Experiments Ablation study on UFO-ViT-M. Our ablation study fo-
cus on the importance of XNorm, and architectural opti-
4.1. Image Classification
mizations which have explained in Section 3.3. We have ex-
Dataset. For image classification task, we evaluate our perimented various normalization methods. Most of other
models using ImageNet1k[9] dataset. Extra dataset or dis- normalization methods do not decrease the loss. It can be
tilled knowledge from convolutional teacher is not used. the one of implicit evidences to prove that our theoretical
5interpretation is reasonable. Interestingly, applying single
L2Norm also shows bad performance. All results are de-
tailed in Table 4.
Comparison with the state of the art models. We ex-
perimented three models which have same architecture de-
signing schemes with DeiT[37]. (See Table 5.) As summa-
rized in Figure 1, all our models have shown higher per-
formance and parameter efficiency than most of concur-
rent transformer-based models. Additionally, our proposed
model has advantages on complexity and data efficiency,
while original ViT[10] requires larger extra dataset like JFT-
300M or ImageNet21k for competitive performance.
Top-1 Params FLOPs
Model Res
Acc (M) (G)
RegNetY-1.6G[30] 78.0 224 11 1.6
DeiT-Ti[37] 72.2 224 5 1.3
XCiT-T12/16[12] 77.1 224 26 1.2
UFO-ViT-T 78.3 224 10 1.9
ResNet-50[17] 75.3 224 26 3.8
RegNetY-4G[30] 80.0 224 21 4.0
DeiT-S[37] 79.8 224 22 4.6 Figure 6: Visualized UFO-module outputs. UFO
Swin-T[26] 81.3 224 29 4.5 schemes cannot be visualized like traditional N × N self-
XCiT-S12/16[12] 82.0 224 26 4.8 attention maps. Instead, we visualize tensor length map of
UFO-ViT-S 81.8 224 21 3.7 UFO-module output from UFO-ViT-M pretrained on Im-
ResNet-101[17] 75.3 224 47 7.6 ageNet1k. All maps are extracted from first layer which
RegNetY-8G[30] 81.7 224 39 8.0 gathers most of spatial information. This map is scaled at
Swin-S[26] 83.0 224 50 8.7 (0, 1). Red means the value is close to 1.
XCiT-S24/16[12] 82.6 224 48 9.1
UFO-ViT-M 82.8 224 37 7.0
RegNetY-16G[30] 82.9 224 84 16.0 classification, we use same hyperparameters for all models,
DeiT-B[37] 81.8 224 86 17.5 learning rate of 1e-4 and 0.05 weight decay. All experi-
Swin-B[26] 83.5 224 88 15.4 ments are performed on 3x schedule. Input resolution is
XCiT-S12/8[12] 83.4 224 26 18.9 fixed to 800 × 1333 for all experiments.
UFO-ViT-L 83.1 224 21 14.3 Evaluation on COCO dataset. We compare to
EfficientNet-B7[34] 84.3 600 66 37.0 CNNs[17, 45] and transformer-based vision models on ob-
XCiT-S24/8[12] 83.9 224 48 36.0 ject detection and instance segmentation tasks. For fair
UFO-ViT-XL 83.9 224 37 27.4 comparison, the experimental environment is same for all
results. All models are pre-trained on ImageNet1k dataset.
Table 5: Comparison with the state of the art models. Our models significantly outperforms CNN-based mod-
Note that the properties of the other models are taken from els. Also they achieves higher or competitive results com-
original papers. pared to state-of-the-art vision transformers with lower ca-
pacity. But XCiT[12] shows slightly better results with
same design space. It might be that XCiT models have
4.2. Object Detection with Mask R-CNN larger embedding space d. UFO-ViT-B performs slightly
worse than UFO-ViT-M on bounding box detection task,
Implementation details. Our models are evaluated on but better on smaller bounding boxes and overall instance
COCO benchmark dataset[25] for object detection task. segmentation scores. All detailed results are reported on
We use UFO-ViT as backbone and Mask R-CNN[16] as Table 6.
detector. This implementation is based on mmdetection
library.[4] The training schemes, like multiscale training
and data augmentation setup, are same as DETR[2]. We use
16 NVIDIA A100 GPUs at training, for 36 epochs with 2
batch size per GPU using AdamW optimizer. Unlike image
6Backbone Params (M) APb APb50 APb75 APm APm
50 APm
75
ResNet50[17] 44.2 41.0 61.7 44.9 37.1 58.4 40.1
PVT-Small[41] 44.1 43.0 65.3 46.9 39.9 62.5 42.8
Swin-T[26] 47.8 46.0 68.1 50.3 41.6 65.1 44.9
XCiT-S12/16[12] 44.3 45.3 67.0 49.5 40.8 64.0 43.8
UFO-ViT-S 39.7 44.6 66.7 48.7 40.4 63.6 42.9
ResNet101[17] 63.2 42.8 63.2 47.1 39.2 60.1 41.3
PVT-Medium[41] 63.9 44.2 66.0 48.2 40.5 63.1 43.5
Swin-S[26] 69.0 48.5 70.2 53.5 43.3 67.3 46.6
XCiT-S24/16[12] 65.8 46.5 68.0 50.9 41.8 65.2 45.0
UFO-ViT-M 56.4 46.0 68.2 50.0 41.0 64.6 43.7
ResNeXt101-64[45] 101.9 44.4 64.9 48.8 39.7 61.9 42.6
PVT-Large[41] 81.0 44.5 66.0 48.3 40.7 63.4 43.7
XCiT-M24/16[12] 101.1 46.7 68.2 51.1 42.0 65.6 44.9
UFO-ViT-B 82.4 45.8 67.4 50.1 41.2 64.5 44.1
Table 6: Object detection performance on the COCO val2017.
5. Conclusion lab detection toolbox and benchmark. arXiv preprint
arXiv:1906.07155, 2019. 6
In this paper, we propose the simple method to
make self-attention have linear complexity without loss [5] Rewon Child, Scott Gray, Alec Radford, and Ilya
of performance. By replacing softmax function, we Sutskever. Generating long sequences with sparse
remove quadratic operation by associate law of ma- transformers. arXiv preprint arXiv:1904.10509, 2019.
trix multiplication. This type of factorization usually 2
causes degradation of performance in earlier researches. [6] François Chollet. Xception: Deep learning with
UFO-ViT models outperform most of existing the state- depthwise separable convolutions. In Proceedings of
of-the-art results of transformer-based and CNN-based the IEEE conference on computer vision and pattern
models at image classification. We have shown that recognition, pages 1251–1258, 2017. 2
our models can be deployed for general purpose well.
Our UFO-ViT models show competitive or higher [7] Krzysztof Choromanski, Valerii Likhosherstov, David
performance than earlier results on dense prediction Dohan, Xingyou Song, Andreea Gane, Tamas Sar-
tasks. With further strategies like multi-stage structure, los, Peter Hawkins, Jared Davis, Afroz Mohiuddin,
we expect UFO-ViT to be more efficient and perform better. Lukasz Kaiser, et al. Rethinking attention with per-
formers. arXiv preprint arXiv:2009.14794, 2020. 2
[8] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang,
References Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chun-
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E hua Shen. Twins: Revisiting the design of spa-
Hinton. Layer normalization. arXiv preprint tial attention in vision transformers. arXiv preprint
arXiv:1607.06450, 2016. 5 arXiv:2104.13840, 1(2):3, 2021. 2
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai
Nicolas Usunier, Alexander Kirillov, and Sergey Li, and Li Fei-Fei. Imagenet: A large-scale hierarchi-
Zagoruyko. End-to-end object detection with trans- cal image database. In 2009 IEEE conference on com-
formers. In European Conference on Computer Vi- puter vision and pattern recognition, pages 248–255.
sion, pages 213–229. Springer, 2020. 1, 6 Ieee, 2009. 1, 5
[3] Chun-Fu Chen, Quanfu Fan, and Rameswar Panda. [10] Alexey Dosovitskiy, Lucas Beyer, Alexander
Crossvit: Cross-attention multi-scale vision trans- Kolesnikov, Dirk Weissenborn, Xiaohua Zhai,
former for image classification. arXiv preprint Thomas Unterthiner, Mostafa Dehghani, Matthias
arXiv:2103.14899, 2021. 2 Minderer, Georg Heigold, Sylvain Gelly, et al.
[4] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, An image is worth 16x16 words: Transformers
Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, for image recognition at scale. arXiv preprint
Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mm- arXiv:2010.11929, 2020. 1, 2, 5, 6
7[11] Ricard Durall, Stanislav Frolov, Andreas Dengel, internal covariate shift. In International conference on
and Janis Keuper. Combining transformer genera- machine learning, pages 448–456. PMLR, 2015. 5
tors with convolutional discriminators. arXiv preprint [23] Yifan Jiang, Shiyu Chang, and Zhangyang Wang.
arXiv:2105.10189, 2021. 1 Transgan: Two transformers can make one strong gan.
[12] Alaaeldin El-Nouby, Hugo Touvron, Mathilde Caron, arXiv preprint arXiv:2102.07074, 2021. 1
Piotr Bojanowski, Matthijs Douze, Armand Joulin, [24] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya.
Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Reformer: The efficient transformer. arXiv preprint
Jakob Verbeek, et al. Xcit: Cross-covariance image arXiv:2001.04451, 2020. 2
transformers. arXiv preprint arXiv:2106.09681, 2021.
1, 2, 4, 5, 6, 7 [25] Tsung-Yi Lin, Michael Maire, Serge Belongie, James
Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and
[13] Patrick Esser, Robin Rombach, and Bjorn Ommer. C Lawrence Zitnick. Microsoft coco: Common ob-
Taming transformers for high-resolution image syn- jects in context. In European conference on computer
thesis. In Proceedings of the IEEE/CVF Conference vision, pages 740–755. Springer, 2014. 1, 6
on Computer Vision and Pattern Recognition, pages
12873–12883, 2021. 1 [26] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei,
Zheng Zhang, Stephen Lin, and Baining Guo. Swin
[14] Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, transformer: Hierarchical vision transformer using
Pierre Stock, Armand Joulin, Hervé Jégou, and shifted windows. arXiv preprint arXiv:2103.14030,
Matthijs Douze. Levit: a vision transformer in con- 2021. 1, 2, 6, 7
vnet’s clothing for faster inference. arXiv preprint
arXiv:2104.01136, 2021. 1, 2, 4 [27] Ilya Loshchilov and Frank Hutter. Decou-
pled weight decay regularization. arXiv preprint
[15] Ali Hassani, Steven Walton, Nikhil Shah, Abulikemu arXiv:1711.05101, 2017. 5
Abuduweili, Jiachen Li, and Humphrey Shi. Escap-
ing the big data paradigm with compact transformers. [28] Razvan Pascanu, Tomas Mikolov, and Yoshua Ben-
arXiv preprint arXiv:2104.05704, 2021. 2 gio. On the difficulty of training recurrent neural net-
works. In International conference on machine learn-
[16] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross ing, pages 1310–1318. PMLR, 2013. 5
Girshick. Mask r-cnn. In Proceedings of the IEEE
international conference on computer vision, pages [29] Adam Paszke, Sam Gross, Francisco Massa, Adam
2961–2969, 2017. 6 Lerer, James Bradbury, Gregory Chanan, Trevor
Killeen, Zeming Lin, Natalia Gimelshein, Luca
[17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Antiga, et al. Pytorch: An imperative style, high-
Sun. Deep residual learning for image recognition. performance deep learning library. Advances in neural
In Proceedings of the IEEE conference on computer information processing systems, 32:8026–8037, 2019.
vision and pattern recognition, pages 770–778, 2016. 5
6, 7
[30] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Gir-
[18] Dan Hendrycks and Kevin Gimpel. Gaussian error lin- shick, Kaiming He, and Piotr Dollár. Designing net-
ear units (gelus). arXiv preprint arXiv:1606.08415, work design spaces. In Proceedings of the IEEE/CVF
2016. 5 Conference on Computer Vision and Pattern Recogni-
[19] Byeongho Heo, Sangdoo Yun, Dongyoon Han, tion, pages 10428–10436, 2020. 6
Sanghyuk Chun, Junsuk Choe, and Seong Joon Oh. [31] Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai
Rethinking spatial dimensions of vision transformers. Yi, and Hongsheng Li. Efficient attention: Atten-
arXiv preprint arXiv:2103.16302, 2021. 1, 2 tion with linear complexities. In Proceedings of
[20] Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, the IEEE/CVF Winter Conference on Applications of
and Tim Salimans. Axial attention in multidimen- Computer Vision, pages 3531–3539, 2021. 1, 2
sional transformers. arXiv preprint arXiv:1912.12180, [32] Aravind Srinivas, Tsung-Yi Lin, Niki Parmar,
2019. 2 Jonathon Shlens, Pieter Abbeel, and Ashish Vaswani.
[21] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Bottleneck transformers for visual recognition. In
Kilian Q Weinberger. Deep networks with stochastic Proceedings of the IEEE/CVF Conference on Com-
depth. In European conference on computer vision, puter Vision and Pattern Recognition, pages 16519–
pages 646–661. Springer, 2016. 5 16529, 2021. 1
[22] Sergey Ioffe and Christian Szegedy. Batch normaliza- [33] Sainbayar Sukhbaatar, Edouard Grave, Piotr Bo-
tion: Accelerating deep network training by reducing janowski, and Armand Joulin. Adaptive attention span
8in transformers. arXiv preprint arXiv:1905.07799, [45] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu,
2019. 2 and Kaiming He. Aggregated residual transformations
[34] Mingxing Tan and Quoc Le. Efficientnet: Rethinking for deep neural networks. In Proceedings of the IEEE
model scaling for convolutional neural networks. In conference on computer vision and pattern recogni-
International Conference on Machine Learning, pages tion, pages 1492–1500, 2017. 6, 7
6105–6114. PMLR, 2019. 6 [46] Yunyang Xiong, Zhanpeng Zeng, Rudrasis
[35] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Chakraborty, Mingxing Tan, Glenn Fung, Yin
Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jes- Li, and Vikas Singh. Nystr\” omformer: A nystr\”
sica Yung, Daniel Keysers, Jakob Uszkoreit, Mario om-based algorithm for approximating self-attention.
Lucic, et al. Mlp-mixer: An all-mlp architecture for arXiv preprint arXiv:2102.03902, 2021. 2
vision. arXiv preprint arXiv:2105.01601, 2021. 2 [47] Yang You, Igor Gitman, and Boris Ginsburg. Large
[36] Hugo Touvron, Piotr Bojanowski, Mathilde Caron, batch training of convolutional networks. arXiv
Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, preprint arXiv:1708.03888, 2017. 5
Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, and [48] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun
Hervé Jégou. Resmlp: Feedforward networks for im- Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, and
age classification with data-efficient training. arXiv Shuicheng Yan. Tokens-to-token vit: Training vision
preprint arXiv:2105.03404, 2021. 2, 3 transformers from scratch on imagenet. arXiv preprint
[37] Hugo Touvron, Matthieu Cord, Matthijs Douze, Fran- arXiv:2101.11986, 2021. 2
cisco Massa, Alexandre Sablayrolles, and Hervé [49] Pengchuan Zhang, Xiyang Dai, Jianwei Yang, Bin
Jégou. Training data-efficient image transformers Xiao, Lu Yuan, Lei Zhang, and Jianfeng Gao. Multi-
& distillation through attention. arXiv preprint scale vision longformer: A new vision transformer
arXiv:2012.12877, 2020. 1, 2, 5, 6 for high-resolution image encoding. arXiv preprint
[38] Hugo Touvron, Matthieu Cord, Alexandre Sablay- arXiv:2103.15358, 2021. 1
rolles, Gabriel Synnaeve, and Hervé Jégou. Go- [50] Zizhao Zhang, Han Zhang, Long Zhao, Ting Chen,
ing deeper with image transformers. arXiv preprint and Tomas Pfister. Aggregating nested transformers.
arXiv:2103.17239, 2021. 2, 4, 5 arXiv preprint arXiv:2105.12723, 2021. 2
[39] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob [51] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian
Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng
Kaiser, and Illia Polosukhin. Attention is all you need. Feng, Tao Xiang, Philip HS Torr, et al. Rethinking
In Advances in neural information processing systems, semantic segmentation from a sequence-to-sequence
pages 5998–6008, 2017. 5 perspective with transformers. In Proceedings of the
[40] Sinong Wang, Belinda Z Li, Madian Khabsa, Han IEEE/CVF Conference on Computer Vision and Pat-
Fang, and Hao Ma. Linformer: Self-attention with tern Recognition, pages 6881–6890, 2021. 1
linear complexity. arXiv preprint arXiv:2006.04768,
2020. 2
[41] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan,
Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and
Ling Shao. Pyramid vision transformer: A versatile
backbone for dense prediction without convolutions.
arXiv preprint arXiv:2102.12122, 2021. 1, 2, 7
[42] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu,
Xiyang Dai, Lu Yuan, and Lei Zhang. Cvt: Intro-
ducing convolutions to vision transformers. arXiv
preprint arXiv:2103.15808, 2021. 1
[43] Yuxin Wu and Kaiming He. Group normalization. In
Proceedings of the European conference on computer
vision (ECCV), pages 3–19, 2018. 5
[44] Tete Xiao, Mannat Singh, Eric Mintun, Trevor Dar-
rell, Piotr Dollár, and Ross Girshick. Early convo-
lutions help transformers see better. arXiv preprint
arXiv:2106.14881, 2021. 2, 4
9You can also read

















































