Towards optimizing electrode configurations for silent speech recognition based on high-density surface electromyography
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Journal of Neural Engineering
PAPER • OPEN ACCESS
Towards optimizing electrode configurations for silent speech recognition
based on high-density surface electromyography
To cite this article: Mingxing Zhu et al 2021 J. Neural Eng. 18 016005
View the article online for updates and enhancements.
This content was downloaded from IP address 46.4.80.155 on 11/10/2021 at 02:41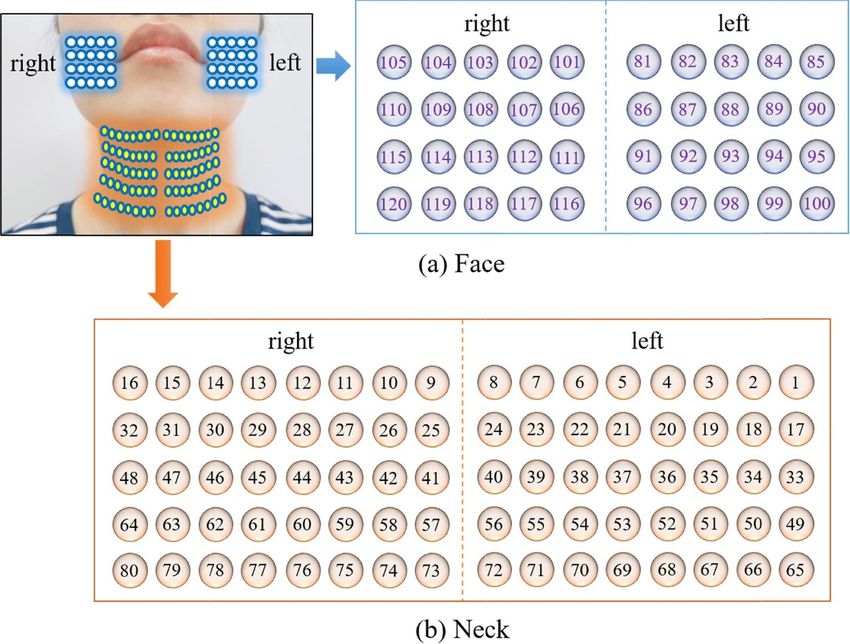
J. Neural Eng. 18 (2021) 016005 https://doi.org/10.1088/1741-2552/abca14
Journal of Neural Engineering
PAPER
Towards optimizing electrode configurations for silent speech
OPEN ACCESS
recognition based on high-density surface electromyography
RECEIVED
22 July 2020 Mingxing Zhu1,2,3, Haoshi Zhang1,2,3, Xiaochen Wang1,2, Xin Wang1,2, Zijian Yang1, Cheng Wang1,2,
REVISED Oluwarotimi Williams Samuel1, Shixiong Chen1 and Guanglin Li1
27 October 2020
1
ACCEPTED FOR PUBLICATION
CAS Key Laboratory of Human-Machine Intelligence-Synergy Systems, Shenzhen Institutes of Advanced Technology, Chinese Academy
12 November 2020 of Sciences, Shenzhen 518055, People’s Republic of China
2
Shenzhen College of Advanced Technology, University of Chinese Academy of Sciences, Shenzhen 518055, People’s Republic of China
PUBLISHED 3
25 January 2021 The first two authors contributed equally to the work.
E-mail: sx.chen@siat.ac.cn and gl.li@siat.ac.cn
Original content from
this work may be used
Keywords: electrode placement optimization, high-density surface electromyography, sequential forward selection algorithm,
under the terms of the silent speech recognition
Creative Commons
Attribution 4.0 licence.
Any further distribution
of this work must
Abstract
maintain attribution to Objective. Silent speech recognition (SSR) based on surface electromyography (sEMG) is an
the author(s) and the title
of the work, journal attractive non-acoustic modality of human-machine interfaces that convert the neuromuscular
citation and DOI.
electrophysiological signals into computer-readable textual messages. The speaking process
involves complex neuromuscular activities spanning a large area over the facial and neck muscles,
thus the locations of the sEMG electrodes considerably affected the performance of the SSR system.
However, most of the previous studies used only a quite limited number of electrodes that were
placed empirically without prior quantitative analysis, resulting in uncertainty and unreliability of
the SSR outcomes. Approach. In this study, the technique of high-density sEMG was proposed to
provide a full representation of the articulatory muscle activities so that the optimal electrode
configuration for SSR could be systemically explored. A total of 120 closely spaced electrodes were
placed on the facial and neck muscles to collect the high-density sEMG signals for classifying ten
digits (0–9) silently spoken in both English and Chinese. The sequential forward selection
algorithm was adopted to explore the optimal electrodes configurations. Main Results. The results
showed that the classification accuracy increased rapidly and became saturated quickly when the
number of selected electrodes increased from 1 to 120. Using only ten optimal electrodes could
achieve a classification accuracy of 86% for English and 94% for Chinese, whereas as many as 40
non-optimized electrodes were required to obtain comparable accuracies. Also, the optimally
selected electrodes seemed to be mostly distributed on the neck instead of the facial region, and
more electrodes were required for English recognition to achieve the same accuracy. Significance.
The findings of this study can provide useful guidelines about electrode placement for developing a
clinically feasible SSR system and implementing a promising approach of human-machine
interface, especially for patients with speaking difficulties.
1. Introduction communication disorders [1–7]. It is worth noting
that a large number of the existing systems util-
Speaking, as a natural form of human communic- ize acoustic signals as input for its speech recogni-
ation via speech, is a tremendously important way tion task, which was widely reported in the literature
to engage in social interaction through transmit- [8–12]. However, the quality of the acoustic signals
ting information, expressing emotions, and convey- is easily affected by various factors such as environ-
ing intentions. In this regard, automatic speech recog- mental noises and non-target human speeches, res-
nition systems have been developed and used in ulting in dramatic declines in recognition accuracies
numerous aspects of our current life very success- under complex conditions. For instance, in loud noisy
fully and widely to enable effective communication environments such as the airport, acoustic signals
in the context of human-machine interactions and of speeches are easily influenced by large-amplitude
© 2021 The Author(s). Published by IOP Publishing Ltd
J. Neural Eng. 18 (2021) 016005 M Zhu et al
environmental noises, making it rather difficult to of sEMG signals, and accomplished average classific-
obtain acoustic signals with a satisfactory signal ation accuracies (CAs) of 94.5% and 89.4% in the
to noise ratio. Such degradation in the quality of healthy and dysarthric volunteers, respectively, using
the acoustic signals would undoubtedly comprom- a feed-forward neural network classifier with five-
ise the performance of the speech recognition sys- fold cross-validation [25]. However, most of the stud-
tem. Moreover, in the circumstances where the acous- ies used myoelectric information from only a few
tic signals cannot be transmitted (such as space and electrodes for sEMG-based SSR. The placement of
underwater), acoustic signals may be unavailable to the electrodes was also completely dependent on the
serve as the input for the speech recognition tasks. knowledge of the individual researchers without prior
Besides, for certain categories of patients with speak- quantitative analysis or benchmark standard.
ing difficulties (e.g. those with laryngectomee and The speaking process involves complex neur-
dysphonia), it is impossible for them to properly omuscular activities over a large group of facial and
use those acoustic-based recognition systems due to neck muscles, spanning a relatively large area [26–28].
lack of speech input. Thus, these limitations of the Thus, the use of a few sEMG electrodes that are placed
commonly used acoustic speech recognition systems empirically may not cover enough regions of muscles
have prompted the need for alternative physiological and provide essentially adequate information for SSR
information that could release the extensive depend- in practical applications. Therefore, it is essential to
ency on acoustic signals and might be used for reliable obtain full knowledge of the sEMG activities over a
speech recognition in silent voice circumstances. large area covering all the articulatory muscles, and
Towards addressing the limitations of acoustic thereafter we could understand which regions con-
signals, surface electromyography (sEMG) that con- tain the most important information towards a high
sists of electrophysiology information of muscles accuracy speech recognition [29–33]. The technology
associated with speaking has been considered as an of high-density sEMG (HD sEMG) uses a 2D closely-
alternative input for automatic speech recognition spaced electrode array (instead of a few electrodes)
[13–16]. Compared with the acoustic signals, the to acquire muscle activities over a relatively large
sEMG signals would not be affected by interfer- portion of the skin surface and therefore provides
ences from the acoustic ambient noises, making it greater representation of the behaviors of multiple
possible to achieve accurate recognition of human muscles or muscle groups [34–37]. In the past dec-
speech even in noisy environments. Moreover, the ades, the HD sEMG technique had been employed in
sEMG signals measured from the articulatory muscles many studies to provide controlling input for human-
could facilitate the development of human-machine machine interfaces, to decode motion intents for arti-
interaction speech interfaces for the rehabilitation of ficial prosthesis, and to decompose motor units for
patients with speech disorders [17–20]. Interestingly, motion analyses [38–41]. Moreover, the HD sEMG
the sEMG signals can be obtained seamlessly in both technique has also been used as a useful tool to
silent and audible modes, making it an ideal candid- dynamically visualize and evaluate muscular activities
ate to overcome the limitation of acoustic signals for associated with swallowing and phonating in previous
speech recognition. studies [42–45]. Therefore, the HD sEMG technique
Due to its important role in the field, the approach could be a great candidate to provide full information
of silent speech recognition (SSR) based on sEMG about the articulatory muscles so that the perform-
has been reported by many studies in the past dec- ance of the sEMG-based SSR could be improved.
ades. The first study in 1985 used three-electrode However, the HD sEMG method requires cum-
channels located near the mouth to record the sEMG bersome time-consuming preparation of a large
signals and to classify five Japanese vowels in real- number of electrodes and could lead to patient dis-
time [21]. In another study, sEMG signals recor- comfort as a consequence. Moreover, the processing
ded from two pairs of electrodes on the neck areas of high-volume HD sEMG requires large compu-
below the chin were used to classify four sub-vocal tation complexity and high power consumption,
Hindi phonemes [22]. Afterward, eight sEMG sensors making it impossible to perform automatic speech
(four on the face, and four on the neck) were util- recognition in real-time, especially in portable applic-
ized for alaryngeal speech recognition in patients ations. Moreover, there is high redundancy in the HD
with surgical removal of the larynx and reported sEMG recordings, and it may lead to over-fitting of
an averaged error rate of 10.3% for the full eight- the data, leading to a decline of classification per-
sensor set, as well as a mean error rate of 13.6% formance as a result. Thus, it is important to explore
when reducing the sensor set to four locations [23]. the least electrode number and optimal electrode
Then, the researchers achieved a 91.1% recognition positions to provide adequate information for reli-
rate in 1200-phrase subvocal speech experiments able speech recognition. However, the comprehens-
using 11 sEMG sensors placed on small articu- ive exploration of the optimal electrode number and
lator muscles of the face and neck [24]. Addition- positions in the context of SSR have rarely been
ally, a speech recognition system was developed for investigated to the best of our knowledge. Moreover,
classifying nine Thai Syllables by using five channels whether there is a significant difference in the optimal
2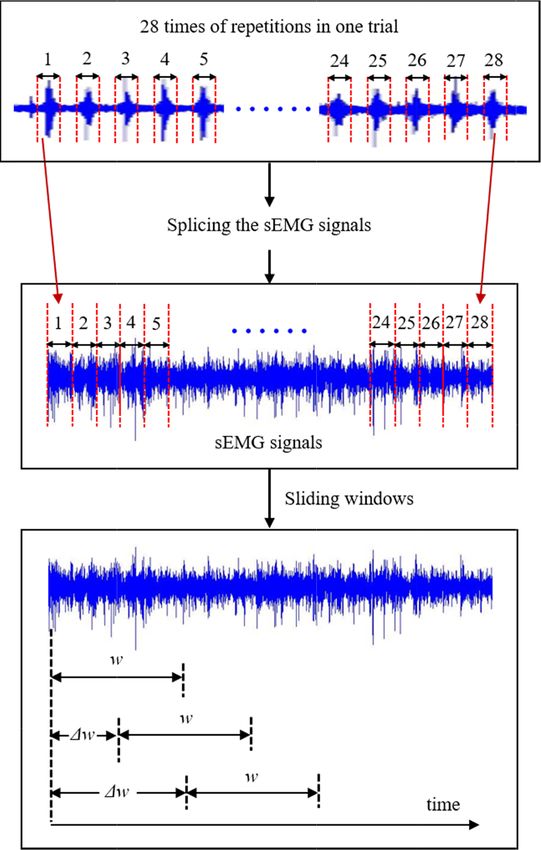
J. Neural Eng. 18 (2021) 016005 M Zhu et al
electrode configuration among different languages Table 1. Speaking tasks of ten English and Chinese digits.
also remains unknown.
The purpose of this study is to investigate the Zero
optimal number and positions of sEMG electrodes One
with the desired classification performance for auto-
Two
matic SSR, using the approach of HD sEMG. A total
of 120 high-density electrodes were evenly placed over Three
the facial and neck muscles, and the HD sEMG sig- Four
nals were simultaneously collected when the subjects
Five
were speaking ten numbers in both Chinese and Eng-
lish. Then the HD sEMG signals were systemically Six
analyzed to explore the contributions from differ- Seven
ent regions of muscles towards a satisfactory SSR so
Eight
that the general guidelines for deciding the optimal
electrode number and positions could be established. Nine
This study could pave the way for the development
of a clinically feasible system for SSR, particularly for
patients with speaking difficulties. in English or Chinese in their normal manner, with
the exception that no sound or voice could be pro-
2. Methodology duced. The subjects could practice the transition from
audible speech to silent speech until they were exper-
2.1. Subjects ienced in silent speech production prior to the exper-
In this study, a total of 12 healthy volunteers (with iments. A microphone was placed near the subject to
a mean age of 25.2 years), including seven males monitor the real-time acoustic signals, and it will ask
and five females, participated in the experiments. the subject to retry the silent speech task if the micro-
All subjects were native Chinese speakers with nor- phone recorded any voices from the subject. Each
mal speaking/hearing abilities and at least 10 years word was repeated 28 times with normal speed (1 s
of experience in English learning. Before the exper- per word) in one trial, and a rest time of 3 s was set
iments, each subject was clearly explained with the between two successive repetitions to avoid muscle
objective and procedures of the experiments. All the fatigue.
subjects voluntarily provided written informed con-
sent, and the experiments were approved by the 2.3. HD sEMG recording
Institutional Review Board of Shenzhen Institutes of The HD sEMG signals were collected via a mul-
Advanced Technology (#IRB ID: SIAT-IRB-170815- tichannel sEMG recording system (REFA 120-model,
H0178). They also gave their permission to use TMS International, the Netherlands), where a total of
their photos and data for scientific and educational 120 channels monopolar electrodes were utilized in
purposes. the current study. The HD sEMG signals were syn-
chronously recorded from all channels of surface elec-
2.2. Experimental procedures trodes on the facial and neck muscles, as presented in
A set of experiments involving various speaking tasks figure 1.
were designed and performed by the recruited sub- The 120-channel electrodes were evenly placed on
jects inside an electromagnetic-shielded room to the articulatory muscles using miniaturized double-
ensure high-quality EMG signals recordings. The sided tapes, with left-right symmetry. Each surface
experiments necessitated the subjects to speak with electrode was approximately 10 mm in diameter,
silent speech mode in two languages, including Eng- and an inter-electrode distance between two neigh-
lish and Chinese, and the corresponding HD sEMG boring electrode centers was kept at 15 mm to
recordings were obtained to compare the articulat- ensure proper coverage of the articulatory muscles
ory muscles contraction patterns of both languages. associated with speaking activities and to minimize
The main goal to apply our methods to Chinese and between-channel interactions during the data col-
English was to investigate the similarities and differ- lection. Considering the mean size of the subjects’
ences in SSR in different languages. In this regard, neck, a total of 80 electrodes were structured in
the subjects were first asked to maintain a quiet relax a 5 × 16 grid array (from channel 1 to channel
state without speaking or moving their body parts for 80) and placed on the suprahyoid and infrahyoid
around 40 s, so that the baseline for the sEMG signals muscles located in the front neck regions (figure
could be determined. Afterward, they were asked to 2(b)). Meanwhile, the rest 40 electrodes were placed
pronounce ten numbers (zero to nine: 0–9) with the on the face muscles, with 20 electrodes (channel 81–
silent (subvocal) mode in English and Chinese lan- 100) on the left and the other 20 electrodes (chan-
guages, respectively (table 1). During the silent speech nel 101–120) on the right (figure 2(a)). The speech-
tasks, the subjects were instructed to say the words related artifacts that mainly originated from the
3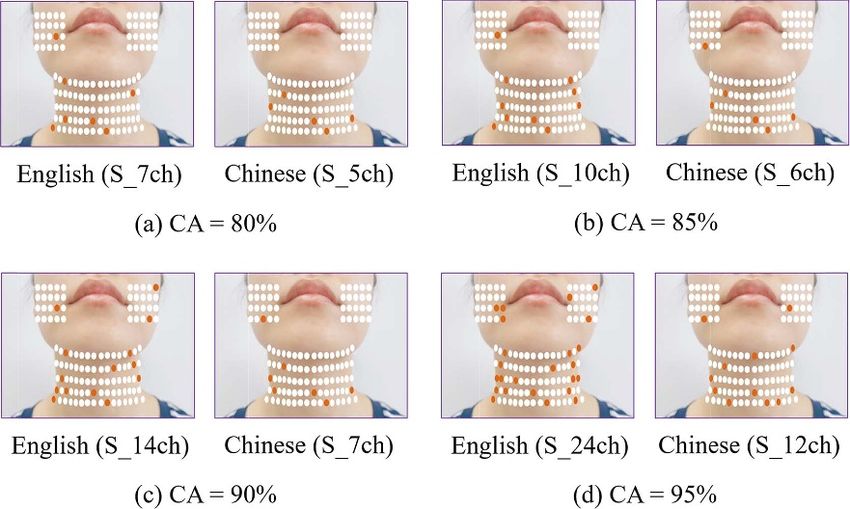
J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 1. Location of the high-density surface electrodes on the facial and neck muscles.
skin-electrode impedance variation during the silent pattern recognition due to their easy implementa-
speech production were minimized by the strong tion and low computation complexity [46, 47]. In this
electrode ring sticker with high-quality conductive study, four prevalent time-domain features, including
gel, so that stable contact between the electrodes and mean absolute value (MAV), waveform length (WL),
the skin could be made even when the subject was zero crossing (ZC), and slope sign change (SSC), were
speaking. extracted from the preprocessed sEMG signals for
In order to evaluate the contribution of different word classification.
muscles, the electrodes were grouped in four different The MAV feature is an average of the absolute
ways (figure 3): the 40 electrodes on the face (F_40ch), amplitude of the EMG signals within a windows seg-
the odd columns of electrodes on the neck (N_40ch), ment calculated by:
all the 80 channels on the neck (N_80ch), and all the
1∑
N
120 channels (All_120ch). Afterward, a reference elec-
MAV = |xi |. (1)
trode was fixed on a fabric bracelet and placed on the N
i=1
left wrist of the subject.
The WL feature could provide a measurement of
the complexity of the EMG signals and is defined as
2.4. Features extracting and word classification the cumulative length of the EMG waveform in the
In this study, All channels of sEMG signals were segment:
sampled at 2048 Hz and filtered with a fourth-
order band-pass Butterworth filter, with cut-off fre- ∑
i=1
quencies of 30–500 Hz to reduce the ECG noise WL = |xi+1 − xi |. (2)
and other low-frequency baseline variations. After N−1
that, a notch filter was used to attenuate the power- The ZC feature is defined as the times that sEMG
line interferences at 50 Hz and its harmonic fre- amplitude crosses zero amplitude and could be calcu-
quencies. Both automated methods during data col- lated by:
lection and visual approach during offline ana-
lyses were employed to exclude faulty trials so that ∑
i=1
satisfactory data quality could be ensured in this ZC = sgn (−xi xi+1 ), (3)
study. N−1
The filtered sEMG data within one trial contain- where sgn(x) equals to 1 when x is not less than a
ing all the repetitions of a given word was sliced chosen threshold, and it equals to 0 otherwise to avoid
according to the instructed speech starting time of the interferences from low-level noises.
the subject (figure 4) to get rid of the non-EMG sig- The SSC feature represents the times that the slope
nals during the resting state. The sEMG signals when of the sEMG signals changes its sign, and it can be
actually pronouncing the words were preserved and mathematically expressed as:
concatenated to get the preprocessed sEMG. Then
the preprocessed sEMG signals were segmented into ∑
i=1
a series of sliding windows with a length w of 400 SSC = |f [(xi − xi−1 ) × (xi − xi+1 )]|. (4)
sampling points (about 200 ms) and an incremental N−1
∆w of 200 sampling points (about 100 ms overlap- All the four proposed features were computed
ping), as shown in figure 4. for each analysis window to serve as the training
Features extracted from the sEMG signals can and testing data of the word recognition classifier
provide useful information embedded in the sig- for the SSR tasks. The linear discriminant analysis
nals for classifying the intended motions. There were (LDA) algorithm that can provide robust classific-
ation against various sEMG interferences with low
various features involving in the time, frequency, computation cost was employed to build the classi-
and time-frequency domain; among those, the time fier [31]. Typically, the LDA assumes that data of each
domain features were used the most frequently in class follow multivariate Gaussian distribution with
4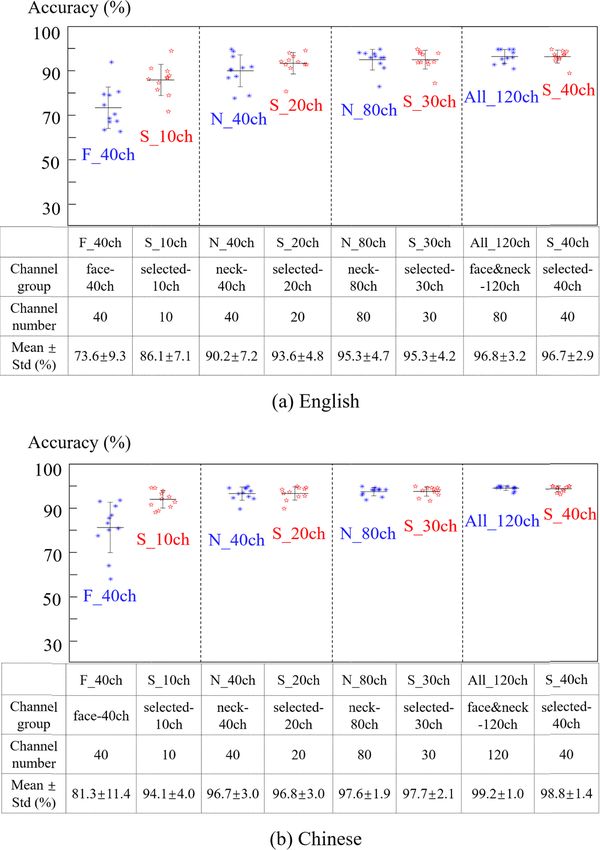
J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 2. The placement of 120-channel electrodes for recording the HD sEMG signals from the face (a) and neck (b) muscles
associated with speaking activities.
Figure 3. Four different ways to group the HD electrodes: (a) the 40 electrodes on the face (F_40ch), (b) the odd columns of
electrodes on the neck (N_40ch), (c) all the 80 channels on the neck (N_80ch), and (d) all the 120 channels (All_120ch).
homoscedastic covariance and the probability dens- above formula can be simplified as follows:
ity function p of class i is defined as:
( )d
p(x|wk ) =
1 1
√ e−1/2 (x − uk ) ′ C− 1 gk ∗ (x) = WK x ′ + Bk (7)
1/2 k (x − uk ) ,
|Ck | 2π
(5)
where d is the dimension of the vector x; uk and
W k = uk C−
k
1
(8)
Ck represent the mean vector and the covariance
matrix for the class i, respectively. According to the
Bayesian classifier, the decision function of LDA can
1
be expressed as: Bk = − uk C−1 ′
k uk − ln{P(wk )}. (9)
2
1
gk ∗ (x) = uk C− 1 ′ −1 ′
k x − uk Ck uk − ln{P(wk )},
2 Then, a five-fold cross-validation technique was
(6) used to partition the matrix of extracted features and
where ln{P (wk )} is the prior probability of class wk . the corresponding targets into training and testing
The pooled covariance matrix Ck is calculated as the sets. These sets were subsequently fed into the LDA
average covariance matrixes of all classes. As a res- classifier that eventually identified the speech pat-
ult, uk and Ck are the only parameters in LDA, where terns inherent in the extracted features. The perform-
ance of the classifier was assessed using the CA metric
k = 1, 2, …, t, and t is the total number of classes.
defined as [48]:
Meanwhile, the LDA is determined by the size of the Number of correctly classifyed samples
comparison gk ∗ (x), so by removing the independent CA = × 100 %.
Total number of testing samples
terms and constant terms in the above formula, the (10)
5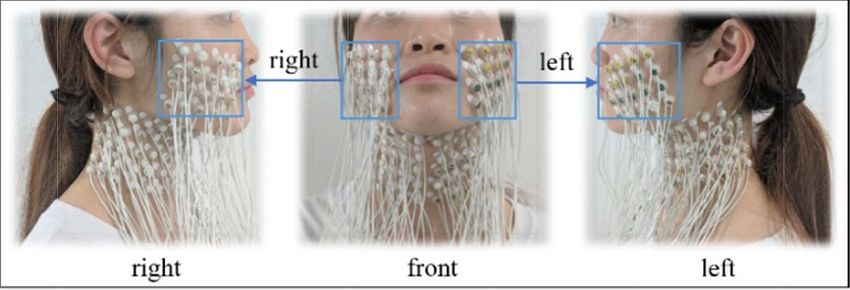
J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 4. Flowchart of creating sliding windows moving along the sEMG time waveform to extract features for speech pattern
recognition, with the window width of w = 400 samples and the overlapping length of ∆w = 200 samples.
2.5. EMG channel selection had already been selected in the (i–1)th iteration,
The spectrogram of the speech signals during the each channel (xj ) from the rest electrodes would
phonation task was derived by using the short-time be picked out and combined with the selected sets
Fourier transform (STFT) method to perform the {S_(i–1)ch} for the speech recognition in the ith iter-
time-frequency analysis. The duration of the STFT ation equation (11). This procedure will be repeated
analysis window was 20 ms and the overlap width until all the rest channels have been tested, and the
between two neighboring windows was 10 ms. The optimal channel x∗ with the highest CA would be
formula of the STFT method implemented in this selected during the ith iteration. Accordingly, the
study could be expressed as follows. sets {S_ (i−1) ch + x∗ } would be selected as the ith
To obtain the minimum possible number of elec- optimal channel sets {S_ich} as a result equation (12).
trode channels with satisfactory CAs, the sequential The iteration process was repeated until i reached
forward selection (SFS) algorithm that is achieved its maximum value N (the maximum number of
by an iterative searching procedure was utilized. channels).
The SFS method, an iterative searching procedure,
firstly selected the best single-channel for classific- CAs ({S_ (i−1) ch} + x∗ )
( )
ation and then added one more channel at a time = max CAs {S_ (i−1) ch} + xj (11)
j∈{1,2,··· ,N−i}
that could reach the maximum CA combine with the
selected electrodes [49, 50]. If the optimal channel
sets {S_(i–1)ch} containing a total of (i–1) channels {S_ich} = {S_ (i−1) ch} + x∗ . (12)
6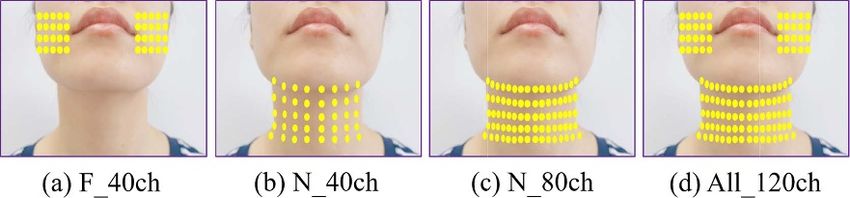
J. Neural Eng. 18 (2021) 016005 M Zhu et al
2.6. Statistical analyses CA showed a similar variation pattern when the D-
The statistical analyses of one-way ANOVA were per- group or S-group changed. Similar findings were
formed to examine whether different groups of elec- also observed when comparing the D-groups and S-
trodes had significant effects on the CA of SSR for groups. Furthermore, the averaged CA for Chinese
Chinese and English, respectively, so that the muscles recognition was significantly higher than that of the
with major contribution could be identified. All the English recognition for the same D-group or S-group,
statistical results were obtained by comparing the p- together with slightly smaller standard deviations.
value with a confidence level of 0.05. The optimal
electrodes that could achieve maximum CA were also 3.2. Effects of the selected channel number
selected for each subject, and the results were ana- The CA averaged across different digits as a function
lyzed across all subjects in order to provide a general of channel number selected by the SFS algorithm was
guideline for practical electrode placements in sEMG- shown in figure 6. As could be observed from the
based SSR. English speech recognition in figure 6(a), the aver-
aged accuracy rapidly increased from 30.8% to 95%
3. Results when the electrode number increased from 1 to 24.
However, the growth in the accuracy was rather lim-
3.1. Effects of electrode groups on classification ited when the channel number further increased. It
performance was noteworthy that the accuracy reached about 80%
In this section, the HD sEMG signals synchronously when only seven optimal channels were selected by
recorded from the facial and neck muscles were used the SFS algorithm, and it could achieve 90% for 14
to classify the silent speech associated with 11 pat- channels. As a comparison, the Chinese speech recog-
terns (ten number 0–9, plus resting state) in Eng- nition in figure 6(b) showed a faster increasing rate
lish and Chinese, respectively. In order to investig- in the accuracy when the selected channel number
ate the effects of electrode configuration, the CAs increased from 1 to 120, with 12 channels accomplish-
were systemically compared when using two differ- ing an accuracy of 95%. It was also seen that an accur-
ent ways to group the HD electrodes: firstly, the elec- acy of 85% could be achieved for merely five electrode
trodes were grouped based on the muscle distribu- channels, and it could reach 90% when adding only
tion and correspondingly divided into four D-groups two more channels.
(F_40ch, N_40ch, N_80ch, and All_120ch), as shown To identify the major contributing muscles
in figure 2; secondly, the electrodes were selected by towards SSR, the distribution of the optimal elec-
employing the SFS algorithm, and there were four trodes selected by the SFS algorithm for increas-
different S-groups depending on how many elec- ing accuracies was shown in figure 7 as a typical
trodes have been selected, namely S_10ch (10 elec- example. A significant observation was that it gener-
trodes selected), S_20ch, S_30ch, and S_40ch. Then ally required more electrodes for English recognition
the CAs in classifying 11 subvocal patterns were com- than Chinese to achieve the same CA. For accuracy of
pared among different groups, and a typical example 80% in figure 7(a), only one out of the seven selected
was shown in figure 5, in which the scatter plots rep- electrodes were distributed on the face for English
resented the CAs of a specific pattern. The means and recognition, whereas none of the five selected elec-
standard deviations were also shown to compare the trodes were located on the face region for Chinese
performances among different groups. recognition. For the accuracy of 85%, only one out of
It could be observed from figure 5(a) that the the ten and six electrodes was located on the face
averaged CA for English recognition consistently for English and Chinese recognition, respectively
increased when the D-group changed from F_40ch (figure 7(b)). Similarly, to achieve higher accuracies
to All_120ch, with the F_40ch having the lowest (figures 7(c) and (d)), while the required electrodes
CA of 73.6%. Similarly, it also showed a monoton- also increased, resulting in much fewer electrodes
ous increase for the averaged CA when the S-group were distributed on the face compared with those on
changed from S_10ch to S_40ch, with the S_10ch the neck, for both English and Chinese recognitions.
group having the lowest CA of 86.1%. When com-
paring between the D-groups and S-groups, it could 3.3. Comparison of optimized channel number
be seen that the S_10ch group had much higher CA between language
than the F_40ch group, although it contained only ten pt In this section, we further analyzed the optim-
electrodes. Meanwhile, the S_20ch group also showed ally selected channels for each subject, and the
slightly larger averaged CA than the N_40ch group, required channel numbers averaged across all the
though it had only half of the electrode number. subjects for four increasing accuracies were shown
Moreover, the S_30ch group had similar averaged CA in figure 8, with the orange color representing Eng-
as the N_80ch group, and the S_40ch group showed lish digit recognition and blue color for Chinese. It
comparable CA as the All_120ch group, despite the could be observed from the figure 8 that the mean
fact that the S-groups had much fewer electrodes. required channel number consistently increased as
In figure 5(b) for Chinese recognition, the averaged the target CA increased for both English and Chinese
7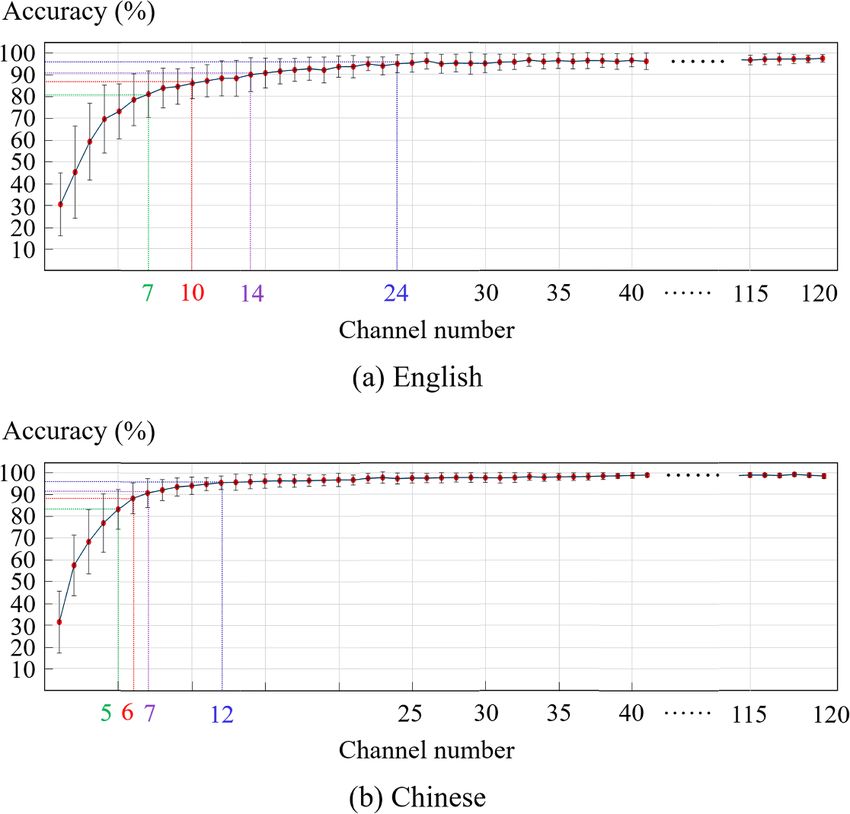
J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 5. Classification accuracies of silent speech recognition in English (a) and Chinese (b) for D-groups (F_40ch, N_40ch,
N_80ch and All_120ch) and S-groups (S_10ch, S_20ch, S_30ch and S_40ch). Each scatter point represented the classification
accuracy for one of the 11 patterns (ten number 0–9, plus resting state).
recognition tasks. When the accuracy increased from distribution similar to figure 7 could be obtained
80% to 95%, the mean optimal channel number individually. Then, occurring times of each of the 120
increased from 6.3 to 25.3 for English, whereas it electrodes were counted when accumulating the res-
was from 5.5 to 22.8 for Chinese. For a given accur- ults of all recruited subjects, and the overall distribu-
acy, the mean required channel number for Chinese tion of the optimally selected electrodes was shown
always seemed lower than that of English recognition. in figure 9, with different colors representing differ-
The variation pattern of the selected channel num- ent occurring times above four.
ber averaged across subjects (figure 8) agreed with For English digit recognition in figure 9(a),
the general observations of the typical example in the optimally selected channels with the maximum
figure 7. occurrences (seven and six times) were consistently
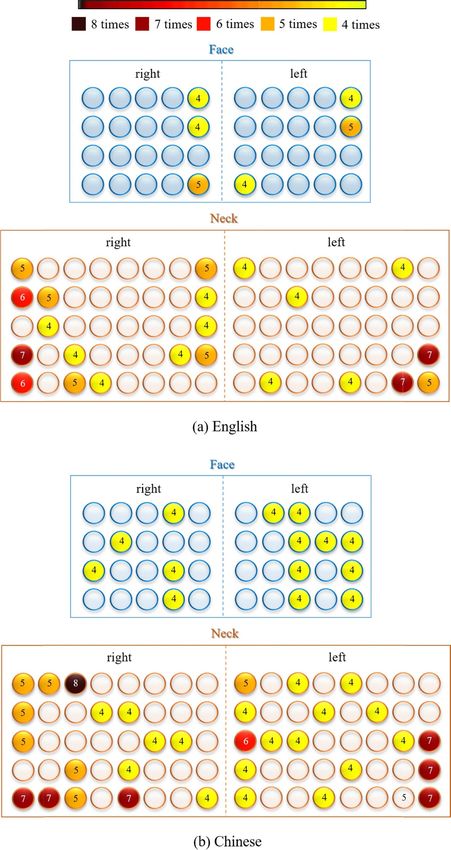
3.4. Distribution of selected electrodes across distributed along the edge of the neck region, and
subjects none of them were observed on the face. For selec-
The selected channels to achieve an accuracy of 95% ted channels with five or four occurrences, there were
were analyzed for each subject, and an electrode also many more electrodes on the neck than on the
8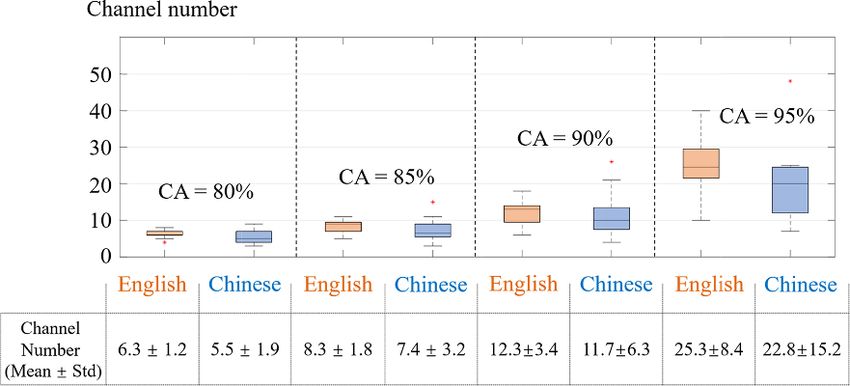
J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 6. Mean classification accuracy (averaged across different words) as a function of the optimal electrode number (from 1 to
120) selected by the SFS algorithm in English (a) and Chinese (b) speech recognition tasks.
Figure 7. Distribution of the selected electrodes for given classification accuracies of 80% (a), 85% (b), 90% (c), and 95% (d).
face. For the neck region, it seemed that there were (figure 9(b)) seemed more than that of English recog-
more optimal electrodes located on the right side than nition (figure 9(a)).
the left side. Meanwhile, for the Chinese digit recog-
nition in figure 9(b), the channels with the highest 4. Discussion
occurrences (eight and seven times) are also distrib-
uted around the edge of the neck, without any of The sEMG-based SSR technique is a viable alternat-
them on the face. The channels that appeared four ive way of communication in situations when acous-
times seemed to be dispersedly distributed on both tic signals are not available as input for automatic
the face and neck regions. Additionally, the selected speech recognition, especially for patients with speak-
channels occurring at least four times for Chinese ing difficulties. Importantly, the optimal electrode
9J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 8. Channel number averaged across all the recruited subjects of different classification accuracy for English and Chinese
digit recognition.
locations and number are key factors to be con- the neck regions would be more likely to record the
sidered in such sEMG-based speech recognition sys- controlling patterns of the articulatory muscles, and
tems. However, the key factors are often arbitrar- therefore the neck electrodes contribute more toward
ily determined via the trial and error method or the SSR. This might be a finding that is intrinsic to
completely by experiences, leading to unsatisfactory the properties of silent speech that is less dependent
recognition accuracies that hinder the widespread on facial articulation. Another interesting finding of
application of such speech recognition systems. The this study is that the optimal electrodes within the
purpose of this study is to systemically investigate the neck seemed to distribute along the edges, as indic-
optimal electrode positions and minimum electrode ated by the typical example in figure 7 and the aver-
number to provide guiding principles for electrode aged results in figure 9. A possible explanation is that
preparation of the sEMG-based SSR system. the articulatory muscles are located closer to the edges
To achieve the goal, HD sEMG signals containing of the electrode array, and there are few articulat-
a rich set of electrophysiological information about ory muscles distributed in the center because of the
the muscles were simultaneously collected from 120 prominent laryngeal. Another possibility might be
channels of surface electrodes located on the facial that the electrodes further away from the center might
and neck regions when the subjects silently pro- be less interfered with by the electrode movements
nounced ten digits in English and Chinese, respect- during the silent pronunciation. It is also possible
ively. As shown in figure 5, electrodes from dif- that the interference of vibrations from both sides of
ferent regions contributed quite differently towards the neck might make these electrodes informational
the speech classification performance of SSR. For redundant. Although there were many studies that
example, the CAs obtained when using electrodes on also proved the feasibility of using sEMG signals for
the neck were much higher than those on the face SSR [23–25, 46, 51], few of them evaluated the con-
for different languages, although with the same chan- tribution difference between the face and neck artic-
nel number. It indicates that the information from ulatory muscles or the muscular difference within the
the neck electrodes plays a more important role, and neck region, due to the lack of full representation of
therefore the muscles on the neck might have more muscular activities using HD sEMG signals. The out-
contributions during the silent speaking tasks. This comes of this study suggest that the sEMG electrodes
conclusion is further supported by figures 6 and 8, should mainly cover the neck muscles rather than the
in which the contributing electrodes mostly came facial muscles for satisfactory classification perform-
from the neck instead of the face when using the ance in practical applications of SSR.
SFS algorithm to select the optimal channels. Very Another important finding of this study was that
few optimal electrodes came from the facial region, the optimal electrodes selected by the SFS algorithm
regardless of the achieved CA or the language. One showed much better performance compared with the
explanation is that the quasi-periodic vibrations of cases when all the electrodes from the neck or facial
vocal cords during speaking are mainly controlled region were used. In figure 5, only 10 optimally selec-
by the neck muscles instead of the facial muscles. ted electrodes could achieve a CA close to 90%, and
There are more articulatory muscles distributed along it significantly outperformed the case when all the
the neck regions, and more muscles are activated or 40 face electrodes were used. Moreover, the CA of
involved during speech production. Meanwhile, the only 30 optimal electrodes was comparable to that
activations of facial muscles are also affected by other of all the 80 electrodes on the neck, while only 40
physiological functions such as expression control, optimal electrodes performed similarly as all the 120
while the neck muscles are more dedicated to speech electrodes. The results suggest that the selection and
and swallowing functions. Thus, the electrodes on optimization of the electrodes are of great importance
10J. Neural Eng. 18 (2021) 016005 M Zhu et al
Figure 9. Distribution of the optimally selected electrodes that occurred at least four times when accumulating the results of all
subjects in English (a) and Chinese (b) silent speech recognition.
for sMEG-based SSR. If there was no optimization In contrast, it is possible to achieve an accuracy as
and all the electrodes were placed on positions with high as 90% when using only 14 electrodes for Eng-
less importance (such as on the face in figure 5), for lish and even less (7 electrodes) for Chinese (figure
example, the CA would be as low as 73.6% even 6). Meanwhile, it was also observed in figure 6 that
though the electrode number was as large as 40. CAs initially grew rapidly when the optimal channel
11J. Neural Eng. 18 (2021) 016005 M Zhu et al
number selected by the SFS algorithm increase from subjects are native Chinese speakers and they were
one, indicating adding more electrodes would be more fluent in Chinese speaking tasks. In contrast,
rather beneficial when the electrode number is quite there might be slightly larger differences in the sEMG
limited. This finding is in accordance with the previ- signals when repeated the same English word in silent
ous study that reported rapidly increasing error rates mode, since the foreign language tasks were not as
with a reduced number of sensors [23]. Also, adding fluent and stable as their native language. There-
nearly 100 more electrodes to the optimally selec- fore, it would require more information from more
ted electrodes (24 for English and 12 for Chinese) electrodes to achieve the same CA due to the larger
with CA above 95% could only lead to an accur- variation in the sEMG signals for English speaking
acy increase of less than 3%, indicating that there tasks. Meanwhile, as could be observed from table
might be large redundancy in the information con- 1, the pronunciation of English digits usually has
tained in the extra 100 electrodes. In other words, a more syllables than those in Chinese (such as zero
continual increase in the electrode channels does not and seven). Although with the same number of syl-
necessarily translate to improved classification per- lables, the pronunciation of English seemed more
formance. Moreover, a large number of electrodes complex than Chinse due to the involvement of more
would lead to high computational complexity, over- consonants (such as five and six). The increase in
fitting of redundant data, and an increase in the sys- pronunciation complexity would need more muscles
tem cost. The electrode optimization could help to to be involved during the speaking process, lead-
greatly reduce the redundancy by selecting optimal ing to the observations that more electrodes were
positions where the activities of all different muscles required for English recognition when compared with
could be recorded using a significantly reduced num- Chinese (figures 7 and 8). Moreover, the subjects
ber of electrodes, which is also supported by the find- recruited in this study are all native Chinese speak-
ings of related studies [16, 29, 30]. By employing ers, and their influence in speaking Chinese might
electrode optimization, a system with a minimum provide more stable sEMG signals that are benefi-
number of electrodes would be easier to operate and cial for speech recognition. The distribution of the
more comfortable for the subjects, which may facil- optimally selected electrodes also demonstrated slight
itate widespread applications of automatic speech differences between English and Chinese (figure 9).
recognition. There are different algorithms to obtain More electrodes with higher occurring times (greater
the optimal combination of electrode positions, such than 6) were observed when the results were accu-
as independent components analysis [30], Genetic mulated across subjects, indicating that there might
algorithm [31], Fisher–Markov selector [52], and the be more in common for the activation patterns of
SFS approach [50]. In this study, the algorithm of the articulatory muscles when the subjects spoke
SFS was used because it is easy to implement and Chinese. It might also be explained by the different
shows great performance in various circumstances proficiency in English among subjects since it is not
of data dimension reduction. The electrode optim- their native language. These findings between English
ization proposed by this study might provide use- and Chinese suggest that we should pay attention to
ful guidelines for sEMG-based SSR on how to use the language differences when deciding the optimal
the least number of electrodes to achieve outstand- electrode positions and number for best practices
ing CAs. However, due to the significant individual of SSR.
differences in pronunciation habits, more subjects Helping Patients who have undergone laryngec-
with various speaking styles should be recruited in tomy or suffered from dysphonia is one of the final
future studies before more solid guidelines could be goals for our proposed sEMG-based SSR techno-
established. logy. However, this study is just the start of this
In this study, differences in classification per- research line and a lot of work still needs to be done
formance were also observed between English and before the technology could be finally applied to these
Chinese. In figure 5, systemically higher averaged patients. The purpose of this study is to investig-
CAs could be found for Chinese digit recognition ate the contributions of different articulatory muscles
than English, for all the electrode configurations. In in SSR and to explore the optimal electrode loca-
figure 6, the accuracy increased more rapidly when tions towards satisfactory classification. Such purpose
the optimally selected electrode number increased was achieved by employing normal healthy individu-
from 1 to 120. Moreover, consistently fewer electrodes als with healthy articulation musculature and nor-
were required for Chinese recognition to achieve the mal anatomy so that a general guideline could be
same accuracy as English tasks, as indicated in figures established on how to place electrodes in patients
5–7. One reason for the language differences could with speaking difficulties, especially when the num-
be that speaking different languages required differ- ber of the available electrodes were limited. In future
ent articulation styles that may influence the contrac- studies, patients with laryngectomy and dysphonia
tion patterns of the articulatory muscles. The slight should also be included to confirm the claims and
superior performance of Chinese speech recognition the system should be made to work in real-time with
may be attributed to the fact that all the recruited online processing and closed-loop classifiers so that
12J. Neural Eng. 18 (2021) 016005 M Zhu et al
the proposed sEMG-based SSR technology could be Oluwarotimi Williams Samuel
more useful in real scenarios. https://orcid.org/0000-0003-1945-1402
Shixiong Chen https://orcid.org/0000-0002-5868-
5. Conclusions 6952
In this study, the optimal number and positions References
of electrodes for SSR in English and Chinese were
investigated based on HD sEMG recordings with 40 [1] De-la-calle-silos F and Stern R M 2017 Synchrony-based
feature extraction for robust automatic speech recognition
electrodes placed on the face and 80 on the front IEEE Signal Process. Lett. 24 1158–62
neck. The findings suggested that the electrodes on [2] Fukui M, Watanabe T and Kanazawa M 2018 Sound source
the neck region had significantly larger contributions separation for plural passenger speech recognition in smart
than those on the face. The electrode groups optim- mobility system IEEE Trans. Consum. Electron. 64 399–405
[3] Li J, Deng L, Gong Y and Haeb-Umbach R 2014 An overview
ally selected by the SFS algorithm outperformed the of noise-robust automatic speech recognition IEEE/ACM
no-optimization group with much larger numbers of Trans. Audio, Speech, Language Process. 22 745–77
electrodes, among which only ten optimal electrodes [4] Shimada K, Bando Y, Mimura M, Itoyama K, Yoshii K and
could achieve a CA above 86%. Further investigation Kawahara T 2019 Unsupervised speech enhancement based
on multichannel NMF-informed beamforming for
demonstrated that the CAs increased rapidly and then noise-robust automatic speech recognition IEEE/ACM Trans.
became saturated when the optimal channel num- Audio, Speech, Language Process. 27 960–71
ber increased from 1. Statistical results showed that [5] Sainath T N, Weiss R J, Wilson K W, Li B, Narayanan A,
the optimally selected electrodes were mainly distrib- Variani E, Bacchiani M, Shafran I, Senior A and Chin K 2017
Multichannel signal processing with deep neural networks
uted on the neck instead of the face region, and more for automatic speech recognition IEEE/ACM Trans. Audio,
electrodes were required for English recognition to Speech, Language Process. 25 965–79
achieve the same accuracy. The finding of this study [6] Saksamudre S K, Shrishrimal P and Deshmukh R 2015 A
might provide useful information about the electrode review on different approaches for speech recognition
system Int. J. Comput. Appl. 115 23–28
placement when using sEMG signals for SSR, which [7] Enarvi S, Smit P, Virpioja S and Kurimo M 2017 Automatic
is of great importance in developing reliable speech speech recognition with very large conversational finnish
recognition systems in clinical applications. and estonian vocabularies IEEE/ACM Trans. Audio, Speech,
Language Process. 25 2085–97
[8] Yoshioka T, Sehr A, Delcroix M, Kinoshita K, Maas R,
Acknowledgments Nakatani T and Kellermann W 2012 Making machines
understand us in reverberant rooms: robustness against
reverberation for automatic speech recognition IEEE Signal
We would thank all the members in our research Process. Mag. 29 114–26
laboratory at the Research Center for Neural Engin- [9] Yu J, Markov K and Matsui T 2019 Articulatory and
eering, Institute of Advanced Integration Techno- spectrum information fusion based on deep recurrent neural
networks IEEE/ACM Trans. Audio, Speech, Language Process.
logy, Shenzhen Institutes of Advanced Technology,
27 742–52
for their supports and assistance in conducting the [10] Muhammad G 2015 Automatic speech recognition using
experiments and signal processing. The work also was interlaced derivative pattern for cloud based healthcare
supported by Shenzhen Institute of Artificial Intelli- system Cluster Comput. 18 795–802
[11] Ganapathy S 2017 Multivariate autoregressive spectrogram
gence and Robotics for Society.
modeling for noisy speech recognition IEEE Signal Process.
Lett. 24 1373–7
[12] Joy N M and Umesh S 2018 Improving acoustic models in
Funding torgo dysarthric speech database IEEE Trans. Neural Syst.
Rehabil. Eng. 26 637–45
This work was supported in part by the National [13] Janke M and Diener L 2017 EMG-to-speech: direct
Natural Science Foundation of China (Grant generation of speech from facial electromyographic signals
IEEE/ACM Trans. Audio, Speech, Language Process.
Nos. 61771462, 61901464, and 81927804), Shen- 25 2375–85
zhen Governmental Basic Research (Grant No. [14] Khan M and Jahan M 2018 Classification of myoelectric
JCYJ20180507182241622), Science and Technology signal for sub-vocal Hindi phoneme speech recognition
Planning Project of Shenzhen (Grant No. J. Intell. Fuzzy Syst. 35 5585–92
[15] Chau G and Kemper G 2015 One channel subvocal speech
GJHZ20190821160003734), Shenzhen Science phrases recognition using cumulative residual entropy and
and Technology Development Fund (Grant No. support vector machines IEEE Lat. Am. Trans. 13 2135–43
JCYJ20170818163505850), Science and Technology [16] Kubo T, Yoshida M, Hattori T and Ikeda K 2014 Towards
Program of Guangzhou (Grant No. 201803010093), excluding redundancy in electrode grid for automatic speech
recognition based on surface EMG Neurocomputing 134
Science and Technology Planning Project of Guang- 15–19
dong Province (Grant No. 2019A050510033). [17] Smith N R, Rivera L A, Dietrich M, Shyu C-R, Page M P and
DeSouza G N 2015 Detection of simulated vocal
ORCID iDs dysfunctions using complex sEMG patterns IEEE J. Biomed.
Health Inform. 20 787–801
[18] Yu S, Lee T and Ng M L 2016 Surface electromyographic
Mingxing Zhu https://orcid.org/0000-0002-1204- activity of extrinsic laryngeal muscles in Cantonese tone
118X production J. Signal Process. Syst. 82 287–94
13J. Neural Eng. 18 (2021) 016005 M Zhu et al
[19] Stepp C E, Heaton J T, Braden M N, Jetté M E, [36] Cerone G L, Botter A and Gazzoni M 2019 A modular,
Stadelman-Cohen T K and Hillman R E 2011 Comparison of smart, and wearable system for high density sEMG detection
neck tension palpation rating systems with surface IEEE Trans. Biomed. Eng. 66 3371–80
electromyographic and acoustic measures in vocal [37] Huang C, Chen X, Cao S and Zhang X 2016 Muscle-tendon
hyperfunction J. Voice 25 67–75 units localization and activation level analysis based on
[20] Stepp C E, Hillman R E and Heaton J T 2010 Use of neck high-density surface EMG array and NMF algorithm
strap muscle intermuscular coherence as an indicator of J. Neural. Eng. 13 066001
vocal hyperfunction IEEE Trans. Neural Syst. Rehabil. Eng. [38] Afsharipour B, Ullah K and Merletti R 2015 Amplitude
18 329–35 indicators and spatial aliasing in high density surface
[21] Sugie N and Tsunoda K 1985 A speech prosthesis employing electromyography recordings Biomed. Signal Process. Control
a speech synthesizer-vowel discrimination from perioral 22 170–9
muscle activities and vowel production IEEE Trans. Biomed. [39] Naik G R, Baker K G and Nguyen H T 2014 Dependence
Eng. 7 485–90 independence measure for posterior and anterior EMG
[22] Khan M and Jahan M 2016 Sub-vocal speech pattern sensors used in simple and complex finger flexion
recognition of Hindi alphabet with surface movements: evaluation using SDICA IEEE J. Biomed. Health
electromyography signal Perspect. Sci. 8 558–60 Inform. 19 1689–96
[23] Meltzner G S, Heaton J T, Deng Y, De Luca G, Roy S H and [40] Wang D, Zhang X, Gao X, Chen X and Zhou P 2016 Wavelet
Kline J C 2017 Silent speech recognition as an alternative packet feature assessment for high-density myoelectric
communication device for persons with laryngectomy pattern recognition and channel selection toward stroke
IEEE/ACM Trans. Audio, Speech, Language Process. rehabilitation Front. Neurol. 7 197–206
25 2386–98 [41] Bai D, Chen S and Yang J 2019 Upper arm motion
[24] Meltzner G S, Heaton J T, Deng Y, De Luca G, Roy S H and high-density sEMG recognition optimization based on
Kline J C 2018 Development of sEMG sensors and spatial and time-frequency domain features J. Healthc. Eng.
algorithms for silent speech recognition J. Neural. Eng. 2019 1–17
15 046031 [42] Zhu M, Samuel O W, Yang Z, Lin W, Huang Z, Fang P, Tan J,
[25] Jong N S and Phukpattaranont P 2019 A speech recognition Li P, Tong M C and Leung K K 2018 Using muscle synergy to
system based on electromyography for the rehabilitation of evaluate the neck muscular activities during normal
dysarthric patients: a Thai syllable study Biocybern. Biomed. swallowing 40th EMBC (Hawaii, USA) pp 2454–7
Eng. 39 234–45 [43] Zhu M, Yu B, Yang W, Jiang Y, Lu L, Huang Z, Chen S and
[26] Dewan K, Vahabzadeh-Hagh A, Soofer D and Chhetri D K Li G 2017 Evaluation of normal swallowing functions by
2017 Neuromuscular compensation mechanisms in vocal using dynamic high-density surface electromyography maps
fold paralysis and paresis Laryngoscope 127 1633–8 Biomed. Eng. Online 16 133–50
[27] Yin J and Zhang Z 2014 Interaction between the [44] Zhu M, Liang F, Samuel O W, Chen S, Yang W, Lu L, Zou H,
thyroarytenoid and lateral cricoarytenoid muscles in the Li P and Li G 2017 A pilot study on the evaluation of normal
control of vocal fold adduction and eigenfrequencies phonating function based on high-density sEMG
J. Biomech. Eng. 136 111006 topographic maps 39th EMBC (Jeju Island Korea) pp 1030–3
[28] Chhetri D K and Neubauer J 2015 Differential roles for the [45] Zhu M, Lu L, Yang Z, Wang X, Liu Z, Wei W, Chen F, Li P,
thyroarytenoid and lateral cricoarytenoid muscles in Chen S and Li G 2018 Contraction patterns of neck muscles
phonation Laryngoscope 125 2772–7 during phonating by high-density surface electromyography
[29] Hua J, Li G, Jiang D, Zhao H and Qi J 2019 An optimized 2018 IEEE CBS (Shenzhen China) pp 572–5
selection method of channel numbers and electrode layouts [46] Srisuwan N, Phukpattaranont P and Limsakul C 2018
for hand motions recognition Int. J. Hum. Resour. Manag. Comparison of feature evaluation criteria for speech
16 1941006 recognition based on electromyography Med. Biol. Eng.
[30] Naik G R, Al-Timemy A H and Nguyen H T 2015 Comput. 56 1041–51
Transradial amputee gesture classification using an [47] Phinyomark A, Phukpattaranont P and Limsakul C 2012
optimal number of sEMG sensors: an approach using ICA Feature reduction and selection for EMG signal classification
clustering IEEE Trans. Neural Syst. Rehabil. Eng. Expert Syst. Appl. 39 7420–31
24 837–46 [48] Samuel O W, Zhou H, Li X, Wang H, Zhang H, Sangaiah A K
[31] Wang Z, Fang Y, Li G and Liu H 2019 Facilitate sEMG-based and Li G 2018 Pattern recognition of electromyography
human-machine interaction through channel optimization signals based on novel time domain features for amputees’
Int. J. Hum. Resour. Manag. 16 1941001 limb motion classification Comput. Electr. Eng. 67 646–55
[32] Clancy E A, Martinez-Luna C, Wartenberg M, Dai C and [49] Geng Y, Zhang X, Zhang Y and Li G 2014 A novel channel
Farrell T R 2017 Two degrees of freedom quasi-static selection method for multiple motion classification using
EMG-force at the wrist using a minimum number of high-density electromyography Biomed. Eng. Online
electrodes J. Electromyogr. Kinesiol. 34 24–36 13 102
[33] Xu W, Li G, Ju Z and Liu H 2019 Surface EMG electrode [50] Li X, Samuel O W, Zhang X, Wang H, Fang P and Li G 2017
distribution for thumb motion classification based on A motion-classification strategy based on sEMG-EEG signal
wireless communication equipment Int. J. Wirel. Mob. combination for upper-limb amputees J. Neuroeng. Rehabil.
Comput. 16 166–71 14 1–13
[34] Kim M, Gu G, Cha K J, Kim D S and Chung W K 2018 [51] Wand M, Janke M and Schultz T 2014 Tackling speaking
Wireless semg system with a microneedle-based high-density mode varieties in EMG-based speech recognition IEEE
electrode array on a flexible substrate Sensors Trans. Biomed. Eng. 61 2515–26
18 92–93 [52] Cheng Q, Zhou H and Cheng J 2010 The fisher-markov
[35] Ison M, Vujaklija I, Whitsell B, Farina D and Artemiadis P selector: fast selecting maximally separable feature subset for
2015 High-density electromyography and motor skill multiclass classification with applications to
learning for robust long-term control of a 7-DoF robot arm high-dimensional data IEEE Trans. Pattern Anal. Mach.
IEEE Trans. Neural Syst. Rehabil. Eng. 24 424–33 Intell. 33 1217–33
14You can also read

















































