Sentiment Analysis and Time-series Analysis for the COVID-19 vaccine Tweets - Gowtham Kumar Sandaka Bala Namratha Gaekwade
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Bachelor of Science in Computer Science May 2021 Sentiment Analysis and Time-series Analysis for the COVID-19 vaccine Tweets Gowtham Kumar Sandaka Bala Namratha Gaekwade Faculty of Computing, Blekinge Institute of Technology, 371 79 Karlskrona, Sweden
This thesis is submitted to the Faculty of Computing at Blekinge Institute of Technology in partial fulfilment of the requirements for the degree of Bachelor of Science in Computer Science. The thesis is equivalent to 10 weeks of full-time studies. The authors declare that they are the sole authors of this thesis and that they have not used any sources other than those listed in the bibliography and identified as references. They further declare that they have not submitted this thesis at any other institution to obtain a degree. Contact Information: Author(s): Gowtham Kumar Sandaka E-mail: gosa20@student.bth.se Bala Namratha Gaekwade E-mail: baga20@student.bth.se University advisor: Suejb Memeti Department of computer science (DIDA) Faculty of Computing Internet : www.bth.se Blekinge Institute of Technology Phone : +46 455 38 50 00 SE-371 79 Karlskrona, Sweden Fax : +46 455 38 50 57 ii
ABSTRACT Background: The implicit nature of social media information brings many advantages to realistic sentiment analysis applications. Sentiment Analysis is the process of extracting opinions and emotions from data. As a research topic, sentiment analysis of Twitter data has received much attention in recent years. In this study, we have built a model to perform sentiment analysis to classify the sentiments expressed in the Twitter dataset based on the public tweets to raise awareness of the public's concerns by training the models. Objectives: The main goal of this thesis is to develop a model to perform a sentiment analysis on the Twitter data regarding the COVID-19 vaccine and find out the sentiment’s polarity from the data to show the distribution of the sentiments as following: positive, negative, and neutral. A literature study and an experiment are set to identify a suitable approach to develop such a model. Time-series analysis is performed to obtain daily sentiments over the timeline series and daily trend analysis with events associated with the particular dates. Methods: A Systematic Literature Review is performed to identify the most suitable approach to accomplish the sentiment analysis on the COVID-19 vaccine. Then, through the literature study results, an experimental model is developed to distribute the sentiments on the analyzed data and identify the daily sentiments over the timeline series. Results: A VADER is identified from the Literature study, which is the best suitable approach to perform the sentiment analysis. The KDE distribution is determined for each sentiment as obtained by the VADER Sentiment Analyzer. Daily sentiments over the timeline series are generated to identify the trend analysis on Twitter data of the COVID-19 vaccine. Conclusions: This research aims to identify the best-suited approach for sentiment analysis on Twitter data concerning the selected dataset through the study of results. The VADER model prompts optimal results among the sentiments polarity score for the sentiment analysis of Twitter data regarding the selected dataset. The time-series analysis shows how daily sentiments are fluctuant and the daily counts. Seasonal decomposition outcomes speaks about how the world is reacting towards current COVID-19 situation and daily trend analysis elaborates on the everyday sentiments of people. Keywords: COVID-19 vaccine, Sentiment analysis, Time-based analysis, Twitter data, VADER. iii
ACKNOWLEDGEMENTS Most importantly, praise and thanks to God, the Almighty, for showering us blessings throughout our research work, allowing us to accomplish the research favorably. We want to express our heartiest gratitude to our supervisor, Suejb Memeti, for allowing us to conduct research and for providing appropriate support throughout this process. Working and studying under his supervision was a wonderful experience and honor. We are grateful for everything he has done for us. Ultimately, we would like to express our heartfelt gratitude to everyone who assisted us, directly or indirectly, in carrying out this research. iv
CONTENTS ABSTRACT ................................................................................................................................................ III ACKNOWLEDGEMENTS ....................................................................................................................... IV CONTENTS ..................................................................................................................................................V LIST OF FIGURES ...................................................................................................................................... 0 LIST OF TABLES ........................................................................................................................................ 1 LIST OF EQUATIONS ............................................................................................................................... 2 1 INTRODUCTION ............................................................................................................................... 3 1.1 AIMS AND OBJECTIVES: ................................................................................................................. 4 1.2 RESEARCH QUESTIONS: ................................................................................................................. 4 1.3 OVERVIEW:.................................................................................................................................... 4 2 BACKGROUND .................................................................................................................................. 5 2.1 NATURAL LANGUAGE PROCESSING: .............................................................................................. 5 2.1.1 Sentiment Analysis .................................................................................................................... 5 2.1.2 Lexicon-based Approach .......................................................................................................... 5 2.1.3 Machine Learning Approach .................................................................................................... 6 2.1.4 Natural Language Toolkit (NLTK): .......................................................................................... 6 2.1.5 Valence Aware Dictionary and sEntiment Reasoner (VADER): .............................................. 6 2.2 KERNEL DENSITY ESTIMATION (KDE): ......................................................................................... 6 2.3 CUMULATIVE DISTRIBUTION FUNCTION (CDF):............................................................................ 7 2.4 TIME SERIES ANALYSIS: ................................................................................................................ 7 2.4.1 Autocorrelation for Time Series Analysis ................................................................................. 7 2.4.2 Seasonal Decomposition of the Timeline series ....................................................................... 7 2.5 ETHICAL CONSIDERATIONS ........................................................................................................... 8 3 RELATED WORK .............................................................................................................................. 9 4 METHOD ........................................................................................................................................... 11 4.1 LITERATURE REVIEW .................................................................................................................. 11 4.2 EXPERIMENT................................................................................................................................ 11 4.2.1 Setting up Software Environment ........................................................................................... 11 4.2.2 Data collection ....................................................................................................................... 12 4.2.3 Data Overview ........................................................................................................................ 12 4.2.4 Pre-processing the data .......................................................................................................... 13 4.2.5 Analysing Tweet sentiment ..................................................................................................... 13 4.2.6 The KDE Distribution for Analyzed data ............................................................................... 14 4.2.7 Sentiments in Word cloud ....................................................................................................... 14 4.2.8 Distribution of Daily Sentiments over each partition of the time series analysis ................... 14 4.2.9 Autocorrelation analysis and the Decomposition of sentiments into systematic components 14 4.2.10 Daily Trend Analysis with Events Associated to that Particular Date ............................... 15 5 RESULTS AND ANALYSIS ............................................................................................................ 16 5.1 LITERATURE REVIEW RESULTS ................................................................................................... 16 5.2 DATASET COLLECTED USING TWITTER API. ................................................................................ 17 5.3 RESULTS AFTER PRE-PROCESSING THE DATA .............................................................................. 17 5.4 RESULTS USING VADER ............................................................................................................. 18 5.5 RESULTS FOR THE KDE DISTRIBUTION FOR ANALYZED DATA .................................................... 21 5.6 RESULTS FOR SENTIMENTS IN WORD CLOUD ............................................................................... 22 5.7 RESULTS FOR DISTRIBUTION OF DAILY SENTIMENTS OVER EACH PARTITION OF THE TIMELINE .. 23 5.8 RESULTS FOR AUTOCORRELATION ANALYSIS AND THE DECOMPOSITION OF SENTIMENTS INTO SYSTEMATIC COMPONENTS ................................................................................................................................ 24 v
5.9 RESULTS FOR DAILY TREND ANALYSIS WITH EVENTS ASSOCIATED TO THAT PARTICULAR DATE 25 6 DISCUSSION ..................................................................................................................................... 27 7 CONCLUSION AND FUTURE WORK ......................................................................................... 28 7.1 CONCLUSION ............................................................................................................................... 28 7.2 FUTURE WORK ............................................................................................................................. 28 8 REFERENCES .................................................................................................................................... 2 vi
LIST OF FIGURES Figure 5.1: Overall sentiments Distribution ......................................................................................... 20 Figure 5.2: Funnel-chart of Sentiment classification Distribution ....................................................... 20 Figure 5.3: Normal Distribution of Sentiments Across Our Tweets ..................................................... 21 Figure 5.4: CDF of Sentiments Across Our Tweets .............................................................................. 21 Figure 5.5: Word cloud of the top positive and the negative sentiments .............................................. 23 Figure 5.6: Distribution of Daily Sentiments Over the Timeline of Each Partition.............................. 24 Figure 5.7: Autocorrelation of positive and negative sentiments ......................................................... 24 Figure 5.8: Decomposition of sentiments into Trends, Level, Seasonality and Residuals .................... 25 Figure 5.9: Daily Trend Analysis with Events Associated to that Particular Date .............................. 26 0
LIST OF TABLES Table 5.1: Results for the Literature Review ......................................................................................... 16 Table 5.2: Dataset Overview ................................................................................................................. 17 Table 5.3: Result after pre-processing the tweets ................................................................................. 18 Table 5.4: Sentiment score of tweets using the Vader ........................................................................... 19 Table 5.5: Overall sentiment polarity for every tweet ........................................................................... 19 Table 5.6: Trigram of 15 sentences one of the top ten positive tweets .................................................. 22 Table 5.7: Trigram of 15 sentences one of the top ten negative tweets ................................................. 23 Table 5.8: Mean and the SD of the sentiments in each partition .......................................................... 23 1
LIST OF EQUATIONS Equation 4.1: probability density function .............................................................................................. 6 Equation 4.2: Gaussian kernel function .................................................................................................. 7 Equation 4.3: CDF of the standard normal distribution ......................................................................... 7 2
1 INTRODUCTION The approval of the COVID-19 vaccine, such as Pfizer-BioNTech and Moderna vaccines sent waves of excitement and relief across the world. However, according to World Health Organization (WHO) research suggests that some people remain hesitant about receiving a vaccine for COVID-19. The World Health Organization noted in 2019 that one of the greatest threats to global health was vaccine hesitancy[1]. So, most of the COVID-19 vaccine information is available online through various social media platforms and one popular social media platform in this regard is Twitter. Twitter is popular in sentiment analysis and with the vast information available in Twitter, it is effective to perform sentiment analysis and time series analysis[2]. Nowadays, social media sites such as Twitter, Facebook, and YouTube are valuable resource referred to as social data. Events that happen in everyday life are explained on media platforms, and anyone is free to discuss and give their thoughts about these events. Furthermore, social media platforms are enormous sources of information for businesses to oversee public perception and obtain poll results about the products they manufacture. Microblogging services today have become eminent and consistently used platforms. However, due to the informal language used, non-textual content, dialects and acronyms, the classification of data extracted from such microblogging websites is instead a challenging task[3]. Compared with other social media platforms, Twitter is chosen because it provides bountiful information that is majorly used in sentiment analysis and time-series analysis. Twitter is efficient to perform sentiment analysis than other social media platforms. Twitter is a well-known microblogging service that lets users share, deliver, and interpret real-time, short, and simple messages called tweets. In social media data, users type multiple punctuation marks, acronyms, and emoticons express their sentiments [4]. Twitter data enables researchers to obtain large samples of user-generated content, thereby garnering insights to inform early response strategies. Most modern studies have used sentiment analysis to obtain and classify Twitter opinions on various topics, including predictions, reviews, elections, and marketing[5]. In Twitter trends classification, tweets are classified into generic classes like Sports, Education, News, etc. Twitter tweets have unique features like #tag, Targets@, Emoticons, Special symbols, URLs, colloquial terms and so on[3], [6]. Sentiment analysis these days is considered one of the most in-demand research topics in the area of Natural Language Processing (NLP). Some interesting scientific and commercial applications of sentiment analysis include opinion mining, recommender systems and event detection. Sentiment analysis has been handled as a Natural Language Processing task at many levels of granularity[7]. Numerous applications of sentiment analysis can be found in social media, news articles, and product reviews. The results of sentiment analysis are employed in public market research and decision-making. To perform sentiment analysis, we have considered a dataset extracted from Twitter using Twitter API with a tweepy python package which is required to predict the sentiments from the data. The sentiment analysis approach has been applied to the data we have collected, and a detailed explanation is stated. Literature study propounds that many researchers are working on sentiment analysis on Twitter social media. While compared to those research works, our thesis explains performing the sentiment analysis on the Twitter data and time-based analysis on the Twitter trends over the timeline of the COVID-19 vaccine. As a whole, this thesis drives you through a systematic literature review to select best suitable way to perform sentiment analysis and then performing Twitter data sentiment analysis and time series analysis of the sentiments for the COVID-19 vaccine tweets. Sentiment analysis (SA) is an intellectual process of extricating a user's feelings and emotions. It is one of the pursued fields of Natural Language Processing (NLP). The Time-based Analysis is a sequence of observations collected in constant time intervals which means developing models to evaluate the observed time series. In our current work, the Valence Aware Dictionary and sEntiment Reasoner (VADER)[4] assess tweet polarity and classify 3
tweets using multi-class sentiment analysis. From the data available, we can view the COVID-19 vaccine outbreaks in last year. 1.1 Aims and Objectives: The thesis aims to build a model that can evaluate a set of tweets and deliver them based on their meaning into positive, neutral, and negative sentiments and show the distribution of the daily sentiments over the timeline series COVID-19 vaccine. Objectives: 1. Investigate which algorithm is used for the optimal implementation of sentiment analysis. 2. To select which algorithm is better suited for sentiment analysis classification. 3. Preparing a model that could make accurate predictions of sentiment analysis on the COVID-19 vaccine. 4. Performing the time-series analysis on the predicted sentiments. 1.2 Research Questions: RQ1: Which approach can be used to obtain optimal results for sentiment analysis classification? RQ2: How can we distribute the daily sentiments over the timeline series? 1.3 Overview: The thesis is divided into several sections. The overview explains the methods and approaches used to perform the sentiment analysis and time-series analysis in this thesis. The first section is Introduction, which introduces our thesis study, aim and objectives, and research questions. The second section includes discussing the background and various approaches used like Natural Language Processing approach, sentiment analysis and approaches, tools used to perform sentiment analysis, and time-series analysis approach. The third section includes previous surveyed work and various research done by the researchers related to this thesis. This particular section contains methods for answering research questions. It incorporates experimental work such as environment setup, data collection, how the data collected is pre-processed, analyzing tweet sentiments and time series analysis on predicted sentiments and other tools used in the experiment, and experimental setup information. In the next section, the procured results are exhibited like (1) After pre-processing and analyzing the data, the results are shown, (2) Sentiments obtained in the word cloud are exhibited, and (3) Time-series analysis outcomes are explained in detail. The discussion section contains a discussion of the research questions and a discussion on results obtained. In the last section, we sum up the conclusion of the thesis based on the outcomes and future work to improve further. 4
2 BACKGROUND The fundamental understanding of the topic related to sentiment analysis is explained in this chapter. The study includes levels of sentiment analysis as well as approaches to sentiment analysis. In this thesis, the various techniques that are used to implement sentiment analysis are explained. 2.1 Natural Language Processing: Natural Language Processing (NLP) is a set of theory suggesting computer approaches for evaluating and modelling naturally occurring texts at one or more levels of linguistic analysis to achieve human- like speech recognition for various activities and applications. It integrates statistical, machine learning, and deep learning models with computational linguistics rule-based modelling of human language. These methods, when used collectively, allow digital computers to learn the natural language as a medium of textual or speech data and 'fully comprehend' its exact implications, including the presenter or writer's intention and mood[8], [9]. 2.1.1 Sentiment Analysis Sentiment analysis is a method of forecasting people's feelings or emotions toward an entity or a subject. Sentiment analysis uses algorithms to classify various samples of related text into overall positive and negative categories. Most approaches to sentimental analysis include one of two forms: polarity-based, which organize texts as positive or negative or valence-based, considering the strength of the context. For example, in a polarity-based approach, the words excellent and good would be treated the same. In contrast, the excellent would be regarded as favorable as good in the valence-based approach. The Natural Language Processing methods and lexicons with annotated word polarities can carry out this research. The widespread availability of user-generated information on the internet most likely resulted in effective sentiment analysis research[3]. 2.1.2 Lexicon-based Approach As the name implies, the lexicon-based approach utilizes lexicon or dictionaries. In this step, to calculate the orientation for a document, semantic orientation or polarity of words or phrases are used. Unlike a machine learning approach, the lexicon-based method does not necessarily require storing a large corpus of data. It evaluates the orientation of a document using a lexicon or dictionaries. Semantic Orientation (SO) is the measure of subjectivity and opinion in the text, and it captures the polarity and strength of words or phrases. All these sentences govern the complete sentiment orientation of the document. Opinion lexicon is manually or automatically created. The manual approach for developing the opinion lexicon can be time-consuming. It must combine with other automatic methods—these details majorly into two categories of manual lexicons: common lexicon and category-specific lexicon. The advantage of using the lexicon-based approach is that the list of sentiment words and their polarity can be searched very quickly[10]. The standard lexicon comprises default sentiment words with the same sentiment value, split words, negation words, and blind negation words. A comprehensive, high-quality lexicon is often essential for fast, accurate sentiment analysis on large scales[6]. Using this dictionary gives errors that can eliminate by manually checking them, even if this would be time-consuming. One drawback of the VADER-based approach is that it is domain-independent. For example, the word "quiet" would positively describe a car but would be harmful when describing a speakerphone. 5
2.1.3 Machine Learning Approach Machine Learning is one of the common approaches for sentiment analysis, which is short compared to the lexicon-based approach. Classified training data is needed when using a machine learning approach. It will then train the algorithm on this data to structure it to predict the classification of previously unseen data. A few examples of standard algorithms used for this purpose are Naïve Bayes and Support Vector Machines. Investigating and testing all these machine learning algorithms is time-consuming and slow. For the better scope of the report, the lexicon-based approach is chosen. The machine learning approach will not be explored further[10]. 2.1.4 Natural Language Toolkit (NLTK): NLTK is a free, open-source python package that includes several tools for programming and data classification. Linguists, engineers, students, educators, researchers, and developers who work with textual data in natural language processing and text analytics will benefit from NLTK. NLTK makes it simple to access the interfaces of over 50 corpora and lexical resources. It collects text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning[4]. 2.1.5 Valence Aware Dictionary and sEntiment Reasoner (VADER): The implementation is majorly carried out with the application VADER (Valence Aware Dictionary and sEntiment Reasoner). VADER, an open-source application, is a text sentiment analysis model sensitive to both polarity (positive/negative) and intensity (strength) of emotion. This VADER gives us whether a statement is positive, negative or neutral and how much we will get positive, negative or neutral[11]. VADER includes a sentiment lexicon that has been systematically built and some syntactic rules to develop sentiment analysis. VADER is constructed especially for tweets and contains both abbreviations and emojis. Emojis are emotional tokens that are commonly used on the internet. It is an entirely free open-source tool. VADER also takes into consideration word order and degree modifiers[12]. The VADER lexicon-based approach has the advantage of quickly searching the list of sentiment words and their polarity. The dictionary might have errors, but these can be eliminated with a manual check, although this would be time-consuming. One disadvantage of the VADER-based approach is that it is domain-independent. For example, the word "quiet" would positively describe a car but would be harmful when describing a speakerphone[6]. 2.2 Kernel Density Estimation (KDE): Kernel density estimates (KDEs)[13], [14] are a technique for converting continuous data like histograms or scatter plots into a smoothed probability density function in a non-parametric manner using a smoothing parameter h, also known as the bandwidth, as in equation 4.1. Based on a random sample , =1…, a kernel density approximation of a univariate probability density function (pdf) f (Thomas H., Christoph W., 2007) is 1 ̂( ) = ℎ =1 ( − )/ℎ, Equation 2.1 : probability density function In equation 4.2, where n denotes the sample size, h represents the kernel bandwidth, and K means the kernel function. The bandwidth h determines the approximate density's smoothness. A smaller bandwidth h leads to a more variable estimated density, while a larger h leads to a more acceptable 6
estimated density. Random variable density is calculated using kernel functions. The kernel function
used here is the Gaussian kernel function[15], defined as (Che and Wang, 2014).
1 ( − )2
( ) = − 2 2
√2
Equation 2.2: Gaussian kernel function
2.3 Cumulative Distribution Function (CDF):
A normal cumulative distribution function (CDF) is a technique that returns the percentage of the normal
distribution function that is less than or equal to the random variable specified.
The Φ function denotes the CDF of the standard normal distribution:
1
Φ(x) = ( ≤ ) = − ∫ { − 2⁄2 }
√2
−∞
Equation 2.3: CDF of the standard normal distribution
2.4 Time Series Analysis:
A time series is a series of data points indexed in time. The fact that time-series data is ordered makes
it unique in the data space because it often displays serial dependence. Serial dependence occurs when
the value of a datapoint is statistically dependent on another data point at another time. However, this
attribute of time series data violates one of the fundamental assumptions of many statistical analyses
that data is statistically independent[16].
2.4.1 Autocorrelation for Time Series Analysis
Autocorrelation is a type of serial dependence. Autocorrelation occurs when a time series is linearly
related to a delayed version of itself. Correlation, on the other hand, is simply when two independent
variables are linearly related.
Furthermore, some time series forecasting methods (specifically, regression modelling) rely on the
assumption that the residuals are free of autocorrelation (the difference between the fitted model and the
data). Perhaps the most compelling aspect of autocorrelation analysis is how it can assist us in
uncovering hidden patterns in our data and selecting the appropriate forecasting methods. We can use it
specifically to identify seasonality and trend in time series data[17].
2.4.2 Seasonal Decomposition of the Timeline series
It is an essential technique for all types of time series analysis, especially for seasonal adjustment. It
seeks to construct several component series from an observed time series (reconstructing the original by
additions or multiplications). Each of these has a particular characteristic or type of behaviour[18]. For
example, time series are usually decomposed into:
• Level: The average value in the series.
• Trend: The increasing or decreasing value in the series.
• Seasonality: The repeating short-term cycle in the series.
• Noise: The random variation in the series.
72.5 Ethical Considerations On the internet, user privacy is becoming increasingly difficult to manage. Big companies like Facebook and Google have mocked in this regard. Information of a personal nature in the tweets will not be presented in this report to respect the authors' privacy, making the data anonymous. 8
3 RELATED WORK Kaur and Sharma[19] investigated the sentiments regarding coronavirus disease (COVID-19) and the sentiments of various individuals concerning this COVID-19 virus. Twitter API was used to acquire coronavirus-related tweets, which were then analyzed using machine learning processes and methods to determine positive, negative, and neutral emotion. Furthermore, the NLTK library is used for pre- processing fetched tweets. The text blob dataset has been used for tweet analysis. The exciting results in positive, negative, and neutral sentiments are displayed using various visualizations. In comparison with this research, they have used ML methods to find products for sentiment analysis. In contrast, we also use a lexical-based approach for sentiment analysis and perform the time series analysis in our study. Alhaji et al.[20] used Naive Bayes Machine Learning model to perform sentiment analysis on Arabic tweets using Python's NLTK library. The hashtags tweets were related to seven government-urged public health initiatives. In total, they examined 53,127 tweets in this study. Excluding one measure, the results have shown that negative tweets are less compared to positive tweets. According to Prabhakar Kaila et al. [14], the raw data collected, tweets related to #coronavirus, was ideal and fully deserving of being applied and studied using sentiment analysis experiments concerning the novel COVID-2019 outbreaks. They used the Latent Dirichlet Allocation (LDA) method to analyze the information gathered in the document term matrix from the datasets. During the operation, the LDA techniques discovered that the vast majority of the information about the COVID-19 infection paramedic and negative sentiments like fear and positive sentiments such as trust. Medford et al.[21], created a list of COVID-19-related hashtags to search for specific tweets over two weeks from January 14 to January 28, 2020. API extracts tweets and saves them as plain text. The correlated frequency keywords like infection prevention practices, vaccination and racial prejudice are identified and analyzed. Following that, sentiment analysis is used to determine each tweet's emotional valence (positive, negative, or neutral) and dominant emotion (anger, disgust, fear, joy, sadness, or surprise). And at last, relevant topics in tweets are studied and discussed over time using an unsupervised machine learning method. Gilbert et al.[6], generated VADER, which is a simple rule-based model for general sentiment analysis. Particularly in comparison with its efficiency to 11 typical state-of-the-art benchmarks, such as Affective Norms for English Words (ANEW), Linguistic Inquiry and Word Count (LIWC), the General Inquirer, SentiWordNet, and machine learning-oriented techniques that rely on Naive Bayes, Maximum Entropy and Support Vector Machine (SVM) algorithms. The research study has identified the formation, verification, and testing of VADER. The researcher has used qualitative and quantitative methods to process and verify a sentiment lexicon used in the social media field. To evaluate the sentiment of tweets, VADER employs a simple rule-based model. According to the findings, VADER enhanced the advantages of traditional sentiment lexicons such as LIWC. VADER distinguished itself from LIWC by being more sensitive to sentiment expressions in social media environments and generalizing more closely to other fields. Cherish Kay Pastor et al.[22], expresses the feelings of Filipinos as a result of the COVID-19 Pandemic's extreme society quarantine, especially in Luzon. The researcher also examines severe community quarantine and other Pandemic effects on current life based on the users' tweets. The Natural Language Processing methodology is often used to improve user sentiments from extracted tweets. Opinions are viewed as data to be analyzed. Also used a qualitative method to evaluate the effect of the extreme community quarantine in the Luzon area. In this study, AD Dubey, A. D et al.[23], collected and analyzed tweets from a total of twelve states. The tweets were collected between March 11 and March 31, 2020. Furthermore, all tweets are related 9
to the novel COVID-19 disease. The goal of this work is to learn how people in those countries are reacting to disease outbreaks. There is no wonder that specific measures must be taken whilst also obtaining and executing tasks such as pre-processing and removing irrelevant information from tweets. The results say that these experiments prove that most people from these societies think positively and feel good that things will get better, but it is also worth noting that there are signs of grief and pain. Nevertheless, four states, primarily from the European continent, believe they cannot trust the situation due to outbreaks and pandemics affecting huge populations. When comparing previous studies, most researchers employed Python's NLTK package and used the Twitter API to extract corona virus-related tweets. Both approaches were used to perform the sentiment analysis, i.e., machine learning approaches and VADER sentiment analysis approaches. Other methods, such as LDA, were also utilized (Latent Dirichlet Allocation). In this thesis, based on the systematic literature review, we have used a VADER sentiment analyzer to perform sentiment analysis using NLTK python’s library and Twitter API to extract the dataset from Twitter and also time-series analysis is conducted to know the sentiments of the people daily and to find out the tweet count per day. 10
4 METHOD We used two research methods in this study: a literature review and an experiment. First, we conducted a systematic literature review in which we carefully analyzed the literature and chose the approach based on the results. Next, we experimented with research question 2, in which we determined the distribution of sentiments. 4.1 Literature Review A systematic literature study was conducted to address RQ1, by following Marcus Gustafsson and Eric Gilbert's guidelines. This literature review focuses on identifying appropriate approaches for sentiment analysis. We took several steps in our research, which is as follows: 1. Identifying the keywords: We have identified the following keywords: sentiment analysis, time-based analysis, and COVID-19 vaccine. 2. Formulating the search strings: chose significant keywords from the keywords mentioned earlier to develop the search string. 3. Locating the literature: searched various digital database platforms like Diva, Google Scholar, IEEE, and ResearchGate using a search string. 4. Following the Inclusion and Exclusion criteria for selection: To limit our research, inclusion and exclusion criteria are applied to the collected literature, such as articles and conference papers. Inclusion Criteria: • Papers on approaches to sentiment analysis. • All articles must be written in English. Exclusion Criteria: • Incomplete articles. • Articles that are not written in English are not considered. 5. Evaluating and selecting the literature: After implementing the inclusion and exclusion criteria, the refining is done by carefully assessing and selecting the gathered literature. 6. Summarizing the literature: The gathered literature's overall findings outline and represent for analysis. 4.2 Experiment An experiment is set to carry out the consequences of RQ1 obtained from SLR (Systematic Literature Review), in which we identified the appropriate approach for performing sentiment analysis on Twitter data. The experiment is to develop a model for categorizing sentiments as positive, negative, or neutral and evaluating RQ2 to predict the distribution of daily sentiments over a time series. 4.2.1 Setting up Software Environment Python was used in the creation of this model. The following Python libraries are used to develop the machine learning models in this experiment: 11
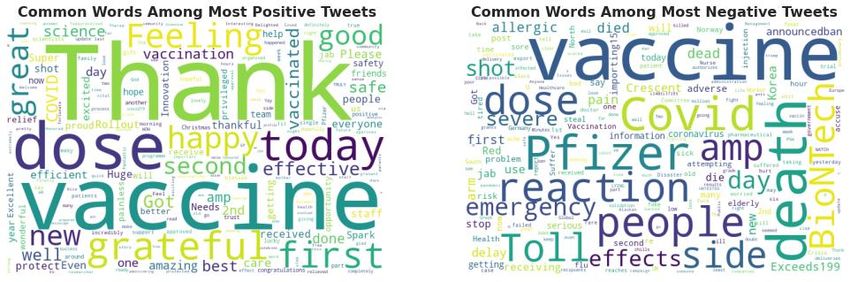
• Python V .3.9: It is a high-level scripting language that is interpreted, interactive, and object- oriented. Python is intended to be highly readable, with fewer syntactical constructions than other programming languages. • NLTK V .3.6.2: It is a Python package that works with human language data and provides a simple interface to various lexical resources such as WordNet and text processing libraries. Classification, tokenization, stemming, tagging, parsing, and semantic reasoning are all performed using these lexical resources. • Pandas V .1.0.1: A Python package that functions as a data analysis tool and works with data structures. Pandas perform the entire data analysis workflow in python, eliminating the need to switch to a more domain-specific language like R. • Tweepy V .3.10.0: It establishes a connection to the Twitter API and retrieves tweets from Twitter. This module is used to stream real-time tweets directly from Twitter. • NumPy V .1.18.1: NumPy is the basic Python computing package. It is used to extend the functionality of multi-dimensional arrays and matrices by providing an extensive collection of high-level mathematical functions. • Scikit-learn V .0.22.1: It is a simple and efficient tool for data mining and data analysis. • Matplotlib V .3.1.3: It is a python library that generates plots, histograms, power spectra, bar charts, etc. In this work, matplotlib.pyplot module is used to plot the metrics. 4.2.2 Data collection As mentioned, the social media platform that has been chosen to collect data sets is Twitter. To illustrate the entire work step by step, we have to describe each stage as follows. Firstly, the essential step is to establish the connection between Python and Twitter Microblog. Twitter makes its data available through public APIs that may access via URLs. Python includes a tweepy package that allows you to access Twitter's data via the API. Calling required libraries, such as Tweepy, is the initial step in implementation. The data we have collected from Twitter were the tweets that were alphabetic, primarily character. Still, users nowadays also include emotional signs such as laughing and sad and even emojis to express their feelings. The data collection is performed for one week, and each day's data is kept in different CSV files. The information that has been targeted was content and also the timestamps of the tweets. The main operation is when the tweets are retrieved from Twitter and sending the tweets to a method that performs the sentiment analysis using python's library. The methods used to extract Twitter data allowed real-time access to publicly available raw tweets. To gather the data, we used Twitter API. Twitter API will enable users to download tweets officially from a user account and save the tweets in a suitable file format like csv[24]. We collected a total 7,313 tweets concerning the COVID-19 vaccine, which were published on Twitter's public message board. To manage the most relevant tweets, we used keywords to retrieve tweets, such as #Pfizer & BioNTech vaccine, #corona vaccine 2020, # COVID-19 vaccine 2020[1]. 4.2.3 Data Overview The dataset that is extracted consists of various fields in it as we see in figure 5.2. The several areas that are more likely user details and activities are described here. There are 16 fields in total and & 7,783 tweets. The fields are user_id, user_name, user_location, user_description, user_created, user_followers, user_friends, user_favourites, user_verified, date, text, hashtags, source, retweets, favourites and is_retweet. The essential fields are user_id, user_name, date, text, hashtags, where these are majorly required and engaged in analyzing the data for the sentiment analysis. 12
4.2.4 Pre-processing the data
On Twitter, a tweet is a microblog message. It’s only allowed to be 140 characters long. The majority
of tweets include text as well as embedded URLs, photos, usernames, and emoticons. There are also
misspellings in them. In the model presented in this study, unstructured data on a novel coronavirus
(2019-nCoV) are extracted from Twitter and then subjected to text cleaning, so-called screening or
filtering, and finally, classification operations[25]. Hence, we carried out a series of pre-processing steps
to remove irrelevant information from the tweets. For analyzing the text, HTML characters, slang words,
stop words, punctuations, URLs etc. are needed to be removed[26]. Splitting of attached words is also
be noticed for cleansing[26]. The reason is that the cleaner the data, the more suitable they are for
mining and feature extraction, which leads to the improved accuracy of the results. The tweets were also
pre-processed to eliminate duplicate tweets and retweets from the dataset, which led to a final sample
of 7,783 tweets—processed each tweet to extract its central message. To pre-process this data, we used
Python's Natural Language Toolkit (NLTK). First, run a regular expression (Regex) in python to detect
and discard tweets special characters, such as URLs ("http://url"), retweet (RT), user mention (@), and
unwanted punctuation. Because hashtags (#) often explain the subject of the tweet and contain helpful
information related to the topic of the tweet, they are added as a part of the tweet, but the "#" symbol
was removed[5].
cleaned_tweets = []
for tweet in tweets:
# String search - remove searched substring from string
# RE for links: r'http\S+
# RE for @mentions: @[A-Za-z0-9]
cleaned_tweet = re.sub(r”http\S+|@[A-Za-z0-9]+”, ““, tweet[0])
# Store in a new list of lists with cleaned tweets
cleaned_tweets.append([cleaned_tweet, tweet[1]])
Then converted the tweets to lowercase, stop words (i.e., words that have no meaning, such as is, a, the,
he, they, etc.) were removed, tokenized the tweets into individual words or tokens, and the tweets were
stemmed using the Porter stemmer. When the pre-processing steps are complete, the dataset was ready
for sentiment classification[4].
4.2.5 Analysing Tweet sentiment
The sentiments expressed in the tweets were classified by VADER Sentiment Analyzer which is applied
to the dataset. First, we created a sentiment intensity analyzer (SIA) to categorize our dataset. Then used
the polarity scores method to determine the sentiments. Then used VADER Sentiment Analyzer to
classify the pre-processed tweets as positive, negative, neutral, or compound. The compound value is a
valuable metric for measuring the sentiment in a given tweet. The compound score is computed by
summing the valence scores of each word in the lexicon, adjusted according to the rules, and then
normalized to be between -1 and +1. The threshold values categorize tweets as either positive, negative,
or neutral[4], [6]. Typical threshold values used in this study are Refer to “(1)”:
Classification of sentiments:
Positive sentiment: compound value > 0.000001, assign score = 1
Neutral sentiment: (compound value > -0.000001) and (compound value < 0.000001), assign score =0
Negative sentiment: compound value < -0.0000001, assign score = -1
134.2.6 The KDE Distribution for Analyzed data A tweet with a compound value more significant than the threshold is classified as a positive tweet. In contrast, a tweet with a compound value less than the threshold is classified as a negative tweet throughout the current study. The tweet was deemed impartial in the remaining instances. We divide the total sentiments into three categories based on their emotional values: positive, neutral, and negative. The length of the model input is determined by the sentiment value, which is crucial for model growth. Following that, we offer a summary distribution of all sentiments. Kernel density calculations will be applied first before the distribution is shown. Using Seaborn, a Python data visualization library built on Matplotlib, provides a high-level interface for drawing KDE graphics while implementing KDE graph[13], [14]. Then, using the CDF(Cumulative Distribution Function) to observe the significant variations in the strength of positive, neutral, and negative feelings in the data are measured based on emotion values. It returns the per cent of the normal distribution function less than or equal to the specified random variable. Therefore, according to the CDF of the standard normal distribution, the overall sentiments are distributed into the positive, neutral, negative according to their sentiment values and the density. 4.2.7 Sentiments in Word cloud The most frequently occurring words are found in this analysis from the above-distributed sentiments, giving both positive and negative sentiments regarding the tweets. The comments represented in the word cloud with a set of the probability of the sentence, which aids in highlighting the most commonly cited words in the reviews. The word cloud of words having a higher likelihood in the sentence. The word cloud is created using 'Word Cloud' packages for each of the topmost positive and the negative sentiments[27]. 4.2.8 Distribution of Daily Sentiments over each partition of the time series analysis Using a time series overview of daily Twitter volume, the sample timeline is split into smaller time intervals. Time series analysis identifies the peaks in Twitter activity to explain the underlying process at work in a specific period. Using continuous data as feedback, this type of study detects shifts in situational information about a topic over time. This time series analysis describes events in real-time and has been introduced in various applications such as economics, the environment, science, and medicine. We analyzed where the changes happened and defined the times of occurrence using multiple methods, including the autocorrelation and seasonal decomposition of sentiments. To break out into separate time series, we illustrated both sudden shifts in relative volume and events. Firstly, we calculate the mean and standard deviation (SD) for the positive sentiments and the negative sentiments by dividing into three partitions periods to distribute the daily sentiments over the timeline for each partition. After partitioning these tweets, we build up a model to show the SD and mean for positive and negative sentiments. 4.2.9 Autocorrelation analysis and the Decomposition of sentiments into systematic components To remove the lags in the built-in model, we perform the autocorrelation analysis. We used the Pandas.Series.autocorr() function, which returns the value of the Pearson correlation coefficient. The Pearson correlation coefficient is a representation of two variables' linear correlation. The Pearson correlation coefficient ranges from -1 to 1, with 0 representing no linear correlation, >0 representing a positive correlation, and
indicates that two variables change in a loop, while a negative correlation coefficient indicates that the variables change in the opposite direction. We used a lag=1 (or data(t) vs. data(t-1)) and a lag=2 (or data(t) vs. data(t-2) to compare the data (t-2). Then used autocorrelation plot to measure the autocorrelation function (AFC) values against various lag sizes. We compared fewer and fewer observations as there is an increase in the lag value. A general guideline is that the total number of observations (T) should be at least 50, and the greatest lag value (k) should be less than or equal to T/k. Since we have 60 observations, we have only considered the first 20 values of the AFC[16], [17], [28]. Then we visualize the data using a time-series decomposition that allows us to decompose time series into four distinct components: trend, seasonality, residual, and noise. We use the seasonal_decompose () function that returns a result object. The result object contains arrays to access four pieces of data from the decomposition [28]. 4.2.10 Daily Trend Analysis with Events Associated to that Particular Date After performing, the seasonal decomposition and the autocorrelation analysis, the daily sentiments are predicted from the data. We broke our dataset into “usernames", “date”, “text", and "hashtags” fields and created new data which had an additional area as "count" (just a standard counter). Then we merged the data based on the date field to see daily analysis of the tweets in my data. 15
5 RESULTS AND ANALYSIS 5.1 Literature Review Results A Systematic Literature Review (SLR) is conducted to answer RQ1. Which approach can be used to obtain optimal results for sentiment analysis classification? The goal of the SLR is to identify the most suitable system that would facilitate accurate results of sentiment analysis? Title Findings VADER: A Parsimonious Rule- Sentiment scores from VADER and 11 other highly regarded based Model for Sentiment Analysis sentiment analysis tools/techniques are compared to give the of social media Text best performance in all metrics. VADER has reached its peak performance with large datasets [6]. Sentiment Analysis for Tweets in In this paper, the standard approach for sentiment analysis Swedish will be introduced shortly for comparison. When using a machine learning approach, one needs classified training data. An algorithm will then be trained on this data to shape the algorithm to predict the classification of unseen data. Investigating and testing machine learning algorithms was considered which is time-consuming for the scope of this report. Instead, the VADER sentiment analyzer was chosen[10]. We are using VADER sentiment and Though this paper belongs to a different domain, as accuracy SVM for predicting customer comparison between algorithms is performed, it has been response sentiment. considered. Machine learning algorithms and lexicon-based approaches such as Support Vector Machines (SVMs) and VADER conclude that VADER gives the highest accuracy than ML algorithms like SVM[29]. A Review of Social Media Posts In this paper, VADER was chosen for sentiment analysis from UniCredit Bank in Europe: A because it works best and provides optimal sentiment analysis Sentiment Analysis Approach on short documents like tweets (social media text)[30]. A Comprehensive Study on Lexicon This paper belongs to a different domain, as an accuracy Based Approaches for Sentiment comparison between lexicon-based approaches is performed, Analysis such as VADER, Textblob, and NLTK. All VADER approaches give high accuracy metrics precision, recall, and F1 score[31]. Hybrid approach: naive Bayes and This paper uses a hybrid approach to perform the sentiment sentiment VADER for analyzing the analysis by VADER and naive Bayes methods. Here, idea of mobile unboxing video Sentiment VADER's lexicon approach for the social media comments text has a good impact on the Naive Bayes classifier in predicting the sentiments[32]. Table 5.1: Results for the Literature Review 16
Numerous works using machine learning algorithms and lexicon-based approaches in the sentiment analysis domain were identified in the Systematic Literature Review (SLR). Most of the articles included a comparison between machine learning techniques and lexicon-based techniques as per [6], [29], [31], [32], Twitter datasets require comparison between algorithms to identify the most suitable one. The VADER is recognized as the most utilized technique to obtain optimal results for sentiment analysis classification. 5.2 Dataset collected using Twitter API. Table 5.2 shows the overview of the dataset that is collected from the Twitter API. This dataset consists of the essential fields: id, user_name, date, text, hashtags, where these are majorly required and engaged in analyzing the data for the sentiment analysis. S User_name date text Hashtags No. 1 ###### ### 20- Same folks said ['PfizerBioNTech'] 12-2020 daikon paste could treat a 06:06:4 cytokine storm 4 #PfizerBioNTech https://t.co/xeHhIMg1kF 2 ###### 12- Explain to me again ['whereareallthesickpeople' #### ###### 12-2020 why we need a vaccine , 'PfizerBioNTech'] 20:17:1 @BorisJohnson 9 @MattHancock #whereareallthesickpeopl e #PfizerBioNTech… 3 ######### 12- There have not been ['BidenHarris', # ####### 12-2020 many bright days in 2020 'Election2020'] 20:04:2 but here are some of the 9 best 1. #BidenHarris winning #Election2020… 4 #### 12- Covid vaccine; You ['CovidVaccine', 'covid19', ###### 12-2020 getting it? 'PfizerBioNTech', 'Moderna'] 20:01:1 #CovidVaccine 6 #covid19 #PfizerBioNTech #Moderna 5 ######### 12- #CovidVaccine ['CovidVaccine', ### 12-2020 'COVID19Vaccine', 'US', 19:30:3 States will start 'pakustv', 'NYC', 'Healthcare', 3 getting 'GlobalGoals'] #COVID19Vaccine Monday, #US Table 5.2: Dataset Overview 5.3 Results after Pre-processing the Data The pre-processing strategies performed on the dataset produced the results as summarized in Table 5.3. This process reduced the number of words in reviews and the number of words in vocabulary significantly. In light of this result, the pre-processing phase was essential to help the researchers clean and remove unnecessary words. 17
Text Tokenized No_stopwords Stemmed_porter Stemmed_snowball Lemmatized 0 The same [same, folks, [folks, said, [folk, said, [folk, said, daikon, [folk, said, folks said said, daikon, daikon, paste, daikon, past, past, could, daikon, daikon paste, could, could, could, treatcytokin... paste, could, paste could trea... treatcytok... treatcytokin... treatcytoki... treatcytoki... 1 while the [while, the, [world, wrong, [world, wrong, [world, wrong, side, [world, world has world, has, side, history, side, histori, year, histori, year, hope, wrong, side, been on the been, on, year, hope, bigg... bigg... history, year, wrong side the, wrong... hopefully... hopefully... of ... 2 Russian [russian, [russian, [russian, vaccin, [russian, vaccin, [russian, vaccine is vaccine, is, vaccine, creat, last, 2, 4, creat, last, 2, 4, year] vaccine, created to created, to, created, last, 2, year] created, last, last 2 4 last, 2, 4... 4, years] 2, 4, year] years 3 facts are [facts, are, [facts, [fact, immut, [fact, immut, senat, [fact, immutable immutable, immutable, senat, even, even, ethic, sturdi, immutable, senator senator, senator, even, ethic, sturdi, enou... senator, even when even, when, ethically, s... enou... even, you re n... y... ethically, st... 4 explain to [explain, to, [explain, [explain, [explain, needvaccin] [explain, me again me, again, needvaccine] needvaccin] needvaccine] why we why, we, need needvaccine] vaccine Table 5.3: Result after pre-processing the tweets 5.4 Results using VADER The results of a Twitter sentiment analysis using NLTK and VADER sentiment analysis tools are discussed in this section 4.2.5. Table 5.4 shows the sentiment score of each tweet as positive, negative, neutral, or compound as obtained by the VADER Sentiment Analyzer. 18
You can also read

















































