Human Perspective Scene Understanding via Multimodal Sensing - Chiori Hori Mitsubishi Electric Research Laboratories (MERL)
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Human Perspective Scene Understanding via Multimodal Sensing Chiori Hori Mitsubishi Electric Research Laboratories (MERL)

Introduction of MERL • The North American arm of the Corporate R&D organization of Mitsubishi Electric – 30 years since 1991 – 81 members (More than 50 PhDs pursue research) – Mission: Advanced application-motivated basic R&D – Intelligent properties: more than 700 patents – Target areas • Wired/wireless communications, • Signal processing, • Audio and video processing, • Spoken language interfaces, • Computer vision, • Mechatronics, • Fundamental algorithms
Target Knowledge to Talk Static Knowledge DB Dynamic Knowledge DB I’m home. How do I get to MERL? From Smartphones Kendall … Dinner is ready Smartphone Apps + cloud services Control appliances through internet
What are we talking about with machines? I can Let’s have a hear ! conversation freely. I can I can see ! walk ! I can I can dance! speak !
Human Machine Interaction: HMI It’s too high for you. Do you need help? Yes, Please!!!! Take it down.

Essential Technologies for HMI HumanMunderstanding ultip Machine understanding Livi le ng shel A ro roo v ad m w es are with ith lin pal big w ed mt 01oooo1oo1o1o1o1 res indow 0101010101010100 s s i nes 000001010101010111101010 m a ch e ith l ac e i l i ng w ith firep c w ss High g room alm tre p Livin d with a A ro • Humans understand scenes using natural language • Machines understand scenes using multimodal sensing information • To interact with humans in a natural and intuitive manner, machines need to translate the sensing information into natural language

Machines Need to Understand Context Using Natural Language Which Two robots: one? Source Signals That’s a cool Spoken Language robot. The one humanoid humanoid, or 010001100001 Multimodal Scene Understanding Multimodal sensed the and round one round one? Understanding information Video input Semantic Understanding Video Description Two robots: one humanoid, Natural Language and one round. Text ? Response Generation Response Generation representation based on scene understanding

History of AI Researches Speech Recognition & Dialog management The 1st AI Boom The 2nd AI Boom The 3rd AI Boom 1960 1970 1980 1990 2000 2010 2015 2020 Phoneme, Isolated Word Continuous Speech (CS) LVCSR Spontaneous Real Environment ・Conversational Speech Speech command, News paper reading speech Broadcast News, Call Home, Lecture Speech YouTube, Chatbot on Smartphone Sequence-to-Sequence DARPA project DNN Acoustic Model for MT (Cho, 2014) Early stages Maximum HMM Golden age Hybrid (Mohamed’09) DNN End-to-end ASR DP DP Matching Likelihood Break- (Graves’14) (Bellman’57) (Sakoe’70) (Bahl’83) Minimum WFST DNN through Spontaneous End-to-End Encoder-decoder ASR Noisy Channel Classification Error (Riley, Mohri’97) Speech Recognition (Bahdanau’15) Delta Cep Viterbi Algorithm Model (Katagiri’91) (Seide’11) (Furui ’81 ) (Viterbi’67) (Jelinek’75) LSTM Acoustic Model Transformer (Graves’13) Cepstrum (Bogert’63) Beam Search (Lowerre’76) NN Winter (Vaswani’17) NN(TDNN) ATIS ANN-HMM POMDP Handcrafted dialog based on End-to-End (Waibel’87) DARPA (Renals’94) WFST-based DM spoken language understanding Dialog system 1990 2008 Computer Vision (CV) Action Recognition Object Recognition/Image classification DARPA VSAM Semantic segmentation, Image Caption Video Surveillance Neurophysiology and Monitoring Video Caption Visual region ImageNet: Image alignment with WordNet (1998-2001) in Cerebral Cortex Hand-writing Large Scale Visual Recognition Challenge: ILSVRC CNN Cats/Monkey Hubel, Wiesel Early stages Character Recognition Neocognitron LeCun, Real-time Object Detection Paul Viola, Mike Jones (FeiFei, ’12) Task MS-COCO: Challenge: Sematic segmentation 1950s, 1960s StaticVariation MSVT/MSR-VTT Neural Network Architecture (2001) (1995) Image Caption (’15-) Video Block World (Fukushima ’79) EigenFace “Video Google: Larry Roberts@MIT DARPA Matthew Turk and Autonomous HDMDB51 A Text Retrieval Approach image Alex Pentland (MIT) (1963) to Object Matching in Videos,” Land Vehicle project (1992) Human motion recognition Video Description (’16) Extracting 3D (1980—1985) J. Sivic, A. Zisserman Summer project NIST FERET project: (Kuehne, ’11) UCF101 information about (2003) Charades Image description “Facial recognition solid objects from 2D Human action recognition Human action recognition “What it saw” ”No hands technology program” HOG (1966) photographs of line across America" ->FRVT Scale-invariant (Histogram of (Shah, ’12) (Gupta, ’16) drawings Takeo Kanade (1993) feature transform Oriented Gradients) (1985) (SIFT) Viola Jones Kinetics400,600 First face recognition David Lawe, (2005) Human action recognition Takeo Kanade@Kyoto Univ. (1999) (Zisserman, ’17-18) (1970) AlexNet,VGG16, ResNet,BN-Inception,etc.

Hand-Crafted Scenario for Tour Guide Make a list of locations Recommend locations one by one eps: Trnst(if_forloop_not_end) eps: Set_rcmdlist Determine Rqst(rcmd):eps eps: Stt(exprnc)/: Set_imprs(Experience user Stt(prcs(rcmd)) d) preferences Stt(prf (spot/general)): eps: eps: eps: eps: Good: eps: eps: eps: Accept: eps: eps: eps: eps: eps: eps: OQ(DST) eps Mk_ Expln(tgt Grt(start) Stt(next_act) Chck_ Extrct_kywd rcmdlist(kwd Set_tgt Rcmd(tgt) Set_impr Aagree ) Cnfrm(dcst Set_imprs Rspns2imprs ) ) (Decided) Prcs4imprs(tgt) forloop(rcmdlist) s (Positive) Neutral: Stt(imprs(Next/Bad) : Keep(tgt, rcmdlist) Decided: Set_imprs(Neutral/Ba Mv(tgt, rcmdlist, dcsnlist) d) eps: Negative: Stt(ro_requiremen t) : Grt(end) Set_imprs(Decided) Remove(tgt, rcmdlist) Eexperienced:Remove(tgt, rcmdlist) eps: Stt(prf(tgt)): Trnst(if_forloop_done) Set A as tgt Set_imprs(Positive) Confirm user selections Stt eps: (no_prefered_tgt eps: eps: eps: ): Grt(end) Rqst(dcsn4rcmdlist) Trnst Chck_rcmdlist eps (if_data_in_rcmdlist) “Statistical dialog management applied to WFST-based eps: dialog systems” (Hori+ICASSP’09) NICT 2007 Trnst(if_nodata_in rcmdlist)

Statistical Dialog Technologies • Statistical dialog systems have been developed to provide greater robustness and flexibility, but rely on discrete dialog state graph to determine next system response – Many states and state transitions, esp for large problems Rule-based model Statistical model Statistical model (QA for Tour Guide) (Guide action simulator) (Hotel clerk simulator) “Statistical dialog management applied to WFST-based dialog systems” (Hori+ICASSP’09) NICT 2007
How to scale up training data • Language data is available with different levels of labels Type of data & labels Data size in words Learning embeddings Unlabeled documents Knowledge graph e.g., wikipedia Conversational data e.g., callhome Dialog with rich labels e.g., Kyoto tour guide Application intention understanding Application dialog data • Strategy: – Learn word/sentence embeddings for unlabeled data – Learn embeddings on smaller data + stronger labels based on embeddings from larger data + weaker labels
Transition to Deep Learning Discrete State Graph • Spoken language understanding: DNN models with continuous state space • End-to-end dialog systems to generate system responses directly from user inputs – Learn deep network model to generate system output layer responses optional recurrent connections role gates role-dependen • without annotating intermediate symbols LSTM layers projection layer input layer
Neural Translation Models (Bahdanau+’14) Sentence-to-Sequence Models Output word sequence y1 y2 … LSTM s0 s1 s2 decoder network LSTM encoder Hidden network h1 h2 h3 h4 h5 Activation Vectors Word embedding x’1 x’2 x’3 x’4 x’5 network x1 x2 x3 x4 x5 Input word sequence
Neural Conversation Models (Vinyals+’15) • Train from OpenSubtitles A pair of two sentences were trained without context. Various movie characters are mixed in the system role.
DSTC6: Sentence-to-Sentence Generation Task (MERL 2016) Context-dependent Response Generation Evaluation: - Comparison with 10 answers by humans - Human rating
Context-Dependent System Response Generation New Phone Bathroom Renovation Bath product USER I need to buy a new phone. I love the new bath bombs! what phone are you looking AGENT we 're glad you like it ! for ? An android phone. I want to renovate my Are the new flavors available USER bathroom. yet? we are the experts in bathroom remodeling . take a AGENT what phone do you have ? yes ! look ! no obligation consult : USER x Where can I visit? you can check out our new you can check out our you can find our store locator AGENT phones here : remodeling services : here :
Milestones for Scene-aware Interaction 2015 2016 2017 2018 2019 2020 2021 2022 HMI: Scene understanding based navigation “ Follow silver car turning right ” thor is Context based response generator Customer service on Twitter 1. Neural Text Dialog Input: dialog history + user input * Data-driven + Annotation free Attentional multimodal fusion 2. Video Description YouTube video, Input: visual + audio feature 3. Audio Visual Joint Student-Teacher learning Question answering system for action videos Scene-aware Input: dialog history+ user input Dialog + audiovisual features Scene-aware Interaction Future Car navigation
Scene-Aware Interaction Car Navigation Use Case
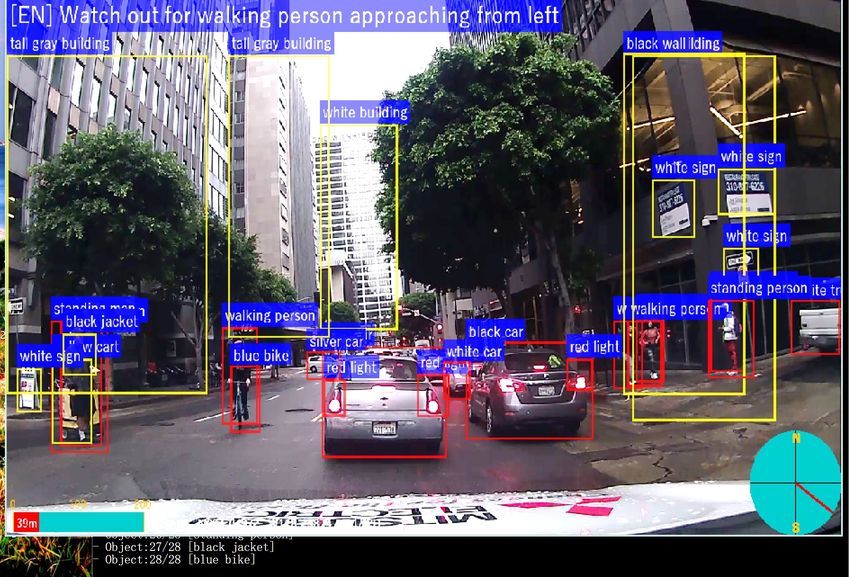
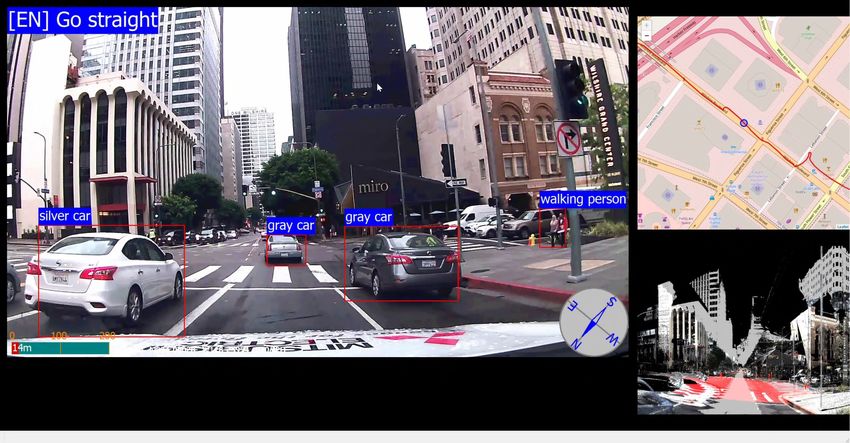
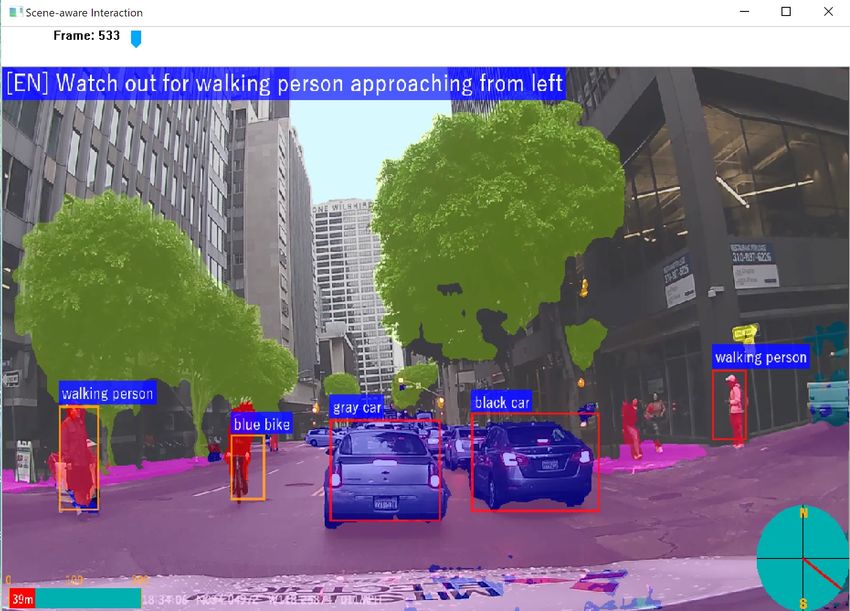
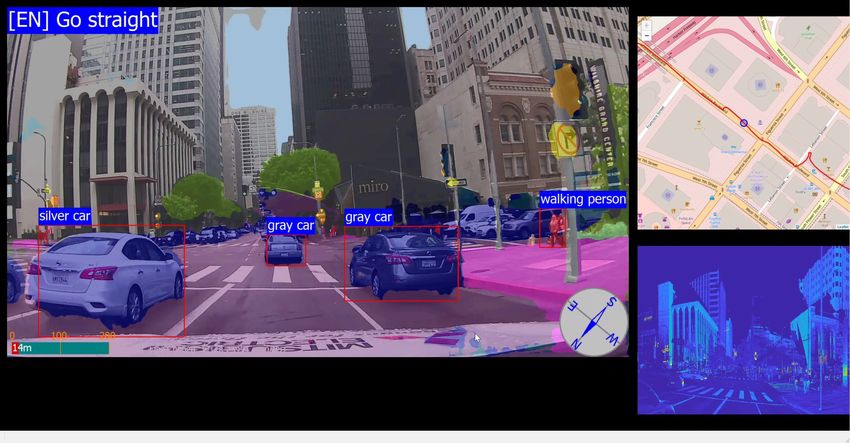
Scene-aware Interaction for Car Navigation Annotation 1: Bounding-box based Object recognition 2D Map+ GPS Point Cloud View Annotation 2: Sematic region segmentation 2D Map+ GPS Point Cloud View
Scene-Aware Interaction https://www.youtube.com/watch?v=t0izXoT_Aoc Future Car Navigation Landmark-based Navigation Turn right at the corner? Yes! After passing the gas station. Tracking-based Voice Warning 3D Point Cloud Camera View Top-Down Map
Multimodal Feature Extraction 1 Original Video Feature Extraction 1: Bounding-box based object recognition
Multimodal Feature Extraction 2 Original Video Feature Extraction 2 Sematic region segmentation
Multimodal Feature Extraction 3 Original Video Feature Extraction 3: Bounding-box Tracking
Multimodal Feature Extraction 4 Prerecorded data of Mobile Mapping System (MMS) provides object location in a view of streets. (http://www.mitsubishielectric.com/bu/mms/) Landmark Localization Original Video Point Cloud View Top Down map
Object recognition results are changed Feature Extraction 1: Bounding-box based object recognition
Scene-aware Interaction for Daily Life Monitoring Surveillance Camera Systems Ask seeking target: “Find a small girl wearing a pink T-shirt” Narrowing down by systems: Suspicious “Is she wearing a hat?” actions near the Answer by users to add more information: station “Yes, she is wearing a straw hat.” CNN: After Boston: The pros and cons of surveillance cameras Scene understanding using video description • Visual features: Object and event recognition • Audio features: Audio event recognition • Scene-understanding: Video description • Dialog history: Context-based future prediction • Response generation: Sequence-to-sequence generation https://www.merl.com/demos/video-description
Sequence-to-sequence models • Neural networks that can learn a mapping function between given input and output sequences in an end-to-end manner – LSTM encoder-decoder: Conversation+MT [Vinyals+’15] – Attention-based encoder decoder: MT [Bahdanau+’14] – Transformer: MT [Vaswani+’17] • Widely used for various sequence-to-sequence tasks Task Input Output Speech recognition Speech signal Sentence text Machine translation Source language text Target language text Language understanding Sentence text Semantic label sequence Dialog generation User utterance System response Video description Image sequence Sentence text
LSTM encoder decoder [Vinyals+’15] Output y1 y2 y3 Encoder Decoder LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM x1 x2 x3 x4 y1 y2 y3 Input LSTM: Long Short-Term Memory Pros: Simple recurrent architecture with LSTM cells, which can memorize relatively long contextual information compared to vanilla RNNs losing contextual information exponentially. Cons: Information of long input sequences may be lost by summarizing the sequence into a fixed dimensional vector in the last state.
Attention-based encoder decoder [Bahdanau+’14] y1 y2 y3 Decoder LSTM LSTM LSTM LSTM Pros • BLSTM encoder captures bidirectional LSTM LSTM LSTM LSTM dependency within input sequence • Attention mechanism allows the decoder to access full encoder y1 y2 y3 outputs Cons Encoder Attention mechanism • BLSTM (or LSTM) can utilize only adjacent state information, which may BLSTM BLSTM BLSTM BLSTM be insufficient to capture long context dependency over the input (or output) BLSTM BLSTM BLSTM BLSTM sequence x1 x2 x3 x4
Transformer [Vaswani+’17] y1 y2 y3 Decoder " × Pros • Feed-forward network with residual Self-attention connections enables to learn very deep architecture, which significantly y1 y2 y3 improves the accuracy • Self-attention mechanism allows to Source attention utilize full-sequence context in Encoder the encoder and the decoder • The most successful model at the moment for many tasks ! × Self-attention x1 x2 x3 x4
Large-scale pretrained language models (LMs) for various sequence-to-sequence tasks in NLP • BERT: Transformer LM that predicts randomly masked words and next sentence or not [Devlin+’19] NSP y1 y2 y3 y'1 y'2 y'3 • Feed sentence pairs with symbol (e.g. QA pairs) × Self-attention • Need task-specific labeled data for fine-tuning • Achieve state-of-the-art y1 y3 y'1 y'2 performance on various NLP tasks • GPT-3: Transformer LM that simply predicts next words [Brown+'20] y1 y2 y3 • Can be applied to various NLP tasks without fine-tuning • Achieve state-of-the-art performance on several tasks by just providing a task specifying sentence and a few input/output examples in inference time × Self-attention • The largest GPT-3 has 175 billion parameters!! ~= 500x larger than the largest BERT model y1 y2 y3 • Still difficult to generate natural long documents
Progress of AI platforms • Hardware – GPU (Nvidia, AMD, …), TPU, FPGA, … #cores, clocks, and memory are increasing (e.g. New Nvidia A40 has 10752 cores, 48GB memory, ...) • GPU libraries – CUDA, CUDAToolkit, OpenCL, …, useful and efficient • Deep learning Toolkits – Caffe, Theano, Torch, CNTK, Chainer, MXNet, ... TensorFlow, PyTorch – Easy implementation of complicated network architecture and training/testing procedure by Python scripting • Build computational graphs in advance (TensorFlow) • Define-by-run (PyTorch, originally from Chainer) • Publicly available code (e.g. GitHub) and models (e.g. Model zoo) • Nice ideas (+ computational resources and data) are important!
6/21/21 Semantic Representation using Audio, Video and Text Features Text features input layer projection hidden output layer layer layer Video Video features Description Text Text features Audio Text Understanding Audio features Video Audio features Speech Recognition Video features
Encoder-decoder LSTM for Video Description 1University of Texas at Austin 2University of California, Berkeley 3University of Massachusetts, Lowell 4 International Computer Science Institute, Berkeley 2015
Multimodal Scene Understanding Objects and events in scenes are recognized using multimodal information 2. Spatiotemporal features: Motion and Action 1. Image and Sound localization features: Airplane Objects and 3. Audio Features: 1. Image and their relations Girl “A girl is jumping.” Sounds and features localization Speech Girl Hill “A girl is standing “A “A girlgirl is looking is looking sitting on the hill.“ on a hill.” at an at an airplane airplane flying flying overhead.” overhead.”
Multimodal Fusion Longstanding area of research: “How to combine information from multiple modalities for machine perception?” – Bayesian adaptation approaches J. R. Movellan and P. Mineiro. “Robust sensor fusion: Analysis and application to audio visual speech recognition. Machine Learning,“ 1998 – Stream weights G. Gravier, et al. “Maximum entropy and mce based hmm stream weight estimation for audio- visual asr,” ICASSP, 2002 The first to fuse multimodal information using attention between modalities in a neural network
Naïve Fusion Attention-Based of Modalities Multimodal Fusion yi-1 yi yi+1 yi-1 yi yi+1 gi gi si-1 si si-1 si Naïve fusion NEW ! b1,i b2,i di Attention to WC1 WC2 Modalities d1,i d2,i Temporal c1,i attention c2,i WC1 Temporal WC2 c1,i attention c2,i a1,i,1 a2,i,1 a1,i,1 a2,i,1 a1,i,L a2,i,L’ a1,i,L a2,i,L’ a1,i,2 a2,i,2 a1,i,2 a2,i,2 x’11 x’12 x’1L x’21 x’22 x’2L’ x’11 x’12 x’1L x’21 x’22 x’2L’ x11 x12 x1L x21 x22 x2L’ x11 x12 x1L x21 x22 x2L’ Modality 1 Modality 2 Modality 1 Modality 2 Context vector: weighted sum of frame features Attention weights for Each modality projected into a common space each input modality and input time Selectively attends to specific modalities
Sample Videos with Automatic Description Image: VGG, Motion: C3D, Audio: MFCC 1. This video shows improvements due to 2. Our use of audio features enable our multimodal attention mechanism identification of peeling action. 3. Audio features make the description 4. Our multimodal attention mechanism and worse due to overdubbed music. audio features are complementary. Unimodal < Naïve Multimodal Fusion < Attentional Multimodal Fusion
Table 4. A list of words with strong average attention weights for each modality, obtained on the the MSR-VTT Subset using our Words “Attentional with Fusion strong (AV)” average multimodal attentionattention method. weights for each modality Image Motion Audio (VGG-16) (C3D) (MFCC) bowl 0.9701 track 0.9887 talking 0.3435 pan 0.9426 motorcycle 0.9564 shown 0.3072 recipe 0.9209 baseball 0.9378 playing 0.2599 piece 0.9136 football 0.9275 singing 0.2465 paper 0.9098 horse 0.9212 driving 0.2284 kitchen 0.8827 soccer 0.9099 working 0.2004 toy 0.8758 basketball 0.9096 walking 0.1999 folding attention Our multimodal 0.8423enables tennis 0.8958 us to see which wordsriding 0.1900 rely most on each modality. makeup Image Features0.8326 player 0.8720 showing 0.1836 Words guitardescribing generic two 0.7723 object type 0.8345 dancing 0.1832 Motion Features: applying 0.7691 video 0.8237 wrestling 0.1735 Words describing scenes involving motion, such as sports and vehicles food Features: Audio 0.7547 men 0.8198 running 0.1689 making Action 0.7470 running verbs associated with sound, such0.7680 applying as talking, singing, and0.1664 driving
Audio Visual Scene-aware Dialog Huda Alamri Jue Wang Vincent Cartillier Gordon Winchern Raphael G. Lopes Takaaki Hori Abhishek Das Anoop Cherian Irfan Essa Tim K. Marks Dhruv Batra Chiori Hori Devi Parikh
VQA to Visual Dialog Devi Parikh, and Dhruv Batra VQA: Visual Dialog: Answering a question Dialog discussing an about an image image
Visual Dialog to Audio Visual Scene-Aware Dialog Audio Visual Scene-Aware Dialog (AVSD) Visual Dialog: AVSD: Dialog discussing an Dialog discussing a image video
http://www.video-dialog.com/ Audio Visual Scene-aware Dialog A dataset with different modalities: Video Audio Dialog history New question → Ground truth answer
AVSD data set
Sentence Selection or Sentence Generation • Sentence selection: - Information Retrieval framework - Difficulty depends on how to prepare multiple candidates • Sentence generation: - Speech recognition/Machine translation framework - Answers generation depends on language models
N-gram Distribution for Questions and Answers AVSD AVSD AVSD Questions Answers sentence lengths
Multimodal Dialog
Open Research Platform 2018 2019 Special Issue on the "7th Dialog System Technology Special Issue on ”Eighth Dialog System Technology Challenge 2019" in Computer Speech and Language Challenge” in IEEE/ACM TASLP
DSTC8 Best System
“Bridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-
Aware Dialog” by Zekang Li et al.
● Considering the similarity between the summary and the video caption, summary
and caption are concatenated to be one sequence. U = {Q1, R1, Q2, R2, . . . QN ,
RN , } to denote the N turns of dialogue,
● Qn: n question, Rn: n response n containing m words.
● Probability to generate the response Rn for the given question Qn considering
video V, audio A, dialogue history UMultimodal Dialog
Essential Video Captioning Power ● Manual captions/summary is not available for real application. ● Answer generation models need video captioning power Joint Student-Teacher Learning for Audio-Visual Scene-Aware Answer Answer yi-1 yi yi+1 y’i-1 y’i y’i+1 Mimic output distributions si-1 si s’i-1 s’i gi-1 gi g’i-1 g’i Mimic context vectors βQ,i β1,i β2,i βH,i β’Q,i β’1,i β’2,i β’H,i Multimodal encoder Multimodal encoder Question Video Dialog Description Video Dialog context +Question context Student network Teacher network
AVSD@DSTC10 3rd Edition of Audio Visual Scene-Aware Dialog Challenge https://github.com/dialogtekgeek/AVSD-DSTC10_Official Task 1: Video QA dialog Goal: Answer generation without using manual descriptions for inference You can train models using manual descriptions but CANNOT use them for testing. Video description capability needs to be embedded within the answer generation models. Task 2: Grounding Video QA dialog Goal: Answer reasoning temporal Localization To support answers, evidence is required to be shown without using manual descriptions.
Video Content Video Player 2.00 10.00 20.00 25.00 27.00 30.00 40.00 Press the buttons to play and stop or slide the bar to find the begin and end timing for reasoning events. A boy is writing looking at a holding it drinking a glass of glass orange juice If the given answer is Turn 1: incorrect, please check “False” and write a Question (Q): What actions are taken by the boy? correct answer with Answer (A): the boy is writing while singing and then drinks a glass of orange juice. timestamp. Please select visual or audio Press the “Begin” and evidence. “End” buttons to extract 2.00 20.00 the current time from the Explain reasons to extract The boy is writing in the notebook. video player. the event to justify why the answer is correct. 30.00 40.00 The boy is drinking from the glass. Press the "+" button to Find as much evidence add more evidence slots 10.00 27.00 as possible you can. or press the "-" button to remove the last evidence. The boy singing Rock music.
AVSD@DSTC Challenge Schedule June 14th, 2021: Answer generation data release June 30th, 2021: Answer reasoning temporal localization data and baseline release Sep. 13th, 2021: Test Data release Sep. 21st, 2021: Test Submission due Join us!!! Nov. 1st, 2021: Challenge paper submission due Jan. or Feb., 2022: Workshop
You can also read

















































