GAN-argcPredNet v1.0: a generative adversarial model for radar echo extrapolation based on convolutional recurrent units
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Geosci. Model Dev., 15, 1467–1475, 2022
https://doi.org/10.5194/gmd-15-1467-2022
© Author(s) 2022. This work is distributed under
the Creative Commons Attribution 4.0 License.
GAN–argcPredNet v1.0: a generative adversarial model for radar
echo extrapolation based on convolutional recurrent units
Kun Zheng1 , Yan Liu1 , Jinbiao Zhang2 , Cong Luo3 , Siyu Tang3 , Huihua Ruan2 , Qiya Tan1 , Yunlei Yi4 , and
Xiutao Ran4
1 Schoolof Geography and Information Engineering, China University of Geosciences, Wuhan 430074, China
2 Guangdong Meteorological Observation Data center, Guangzhou 510080, China
3 Guangdong Meteorological Observatory, Guangdong 510080, China
4 Wuhan Zhaotu Technology Co. Ltd., Wuhan 430074, China
Correspondence: Kun Zheng (zhengk@cug.edu.cn) and Yan Liu (liuyan_@cug.edu.cn)
Received: 24 May 2021 – Discussion started: 6 July 2021
Revised: 25 December 2021 – Accepted: 13 January 2022 – Published: 18 February 2022
Abstract. Precipitation nowcasting plays a vital role in pre- of the result graph and the evaluation index. The recursive
venting meteorological disasters, and Doppler radar data act prediction method will produce the phenomenon that the pre-
as an important input for nowcasting models. When using the diction result will gradually deviate from the true value over
traditional extrapolation method it is difficult to model highly time. In addition, the accuracy of high-intensity echo extrap-
nonlinear echo movements. The key challenge of the now- olation is relatively low. This is a question worthy of further
casting mission lies in achieving high-precision radar echo investigation. In the future, we will continue to conduct re-
extrapolation. In recent years, machine learning has made search from these two directions.
great progress in the extrapolation of weather radar echoes.
However, most of models neglect the multi-modal character-
istics of radar echo data, resulting in blurred and unrealis-
tic prediction images. This paper aims to solve this problem 1 Introduction
by utilizing the features of a generative adversarial network
(GAN), which can enhance multi-modal distribution mod- Precipitation nowcasting refers to the prediction and analysis
eling, and design the radar echo extrapolation model GAN– of rainfall in the target area over a short period of time (0–6 h)
argcPredNet v1.0. The model is composed of an argcPredNet (Bihlo, 2019; Luo et al., 2020). The important data needed
generator and a convolutional neural network discriminator. for this work come from Doppler weather radar with high
In the generator, a gate controlling the memory and output is temporal and spatial resolution (Wang et al., 2007). Relevant
designed in the rgcLSTM component, thereby reducing the departments can issue early warning information through ac-
loss of spatiotemporal information. In the discriminator, the curate nowcasting to avoid loss of life and destruction of
model uses a dual-channel input method, which enables it infrastructure (Luo et al., 2021). However, this task is ex-
to strictly score according to the true echo distribution, and tremely challenging due to its very low tolerance for time
it thus has a more powerful discrimination ability. Through and position errors (Sun et al., 2014).
experiments on a radar dataset from Shenzhen, China, the The existing nowcasting systems mainly include two
results show that the radar echo hit rate (probability of de- types, numerical weather prediction (NWP) and radar echo
tection; POD) and critical success index (CSI) have an av- extrapolation (Chen et al., 2020). The widely used optical
erage increase of 21.4 % and 19 %, respectively, compared flow method several problems, such as its poor capture qual-
with rgcPredNet under different intensity rainfall thresholds, ity in fast echo change regions, the high complexity of the al-
and the false alarm rate (FAR) has decreased by an average gorithm and its low efficiency (Shangzan et al., 2017). Since
of 17.9 %. We also found a problem during the comparison echo extrapolation can be considered a time series image-
prediction problem, these shortcomings of the optical flow
Published by Copernicus Publications on behalf of the European Geosciences Union.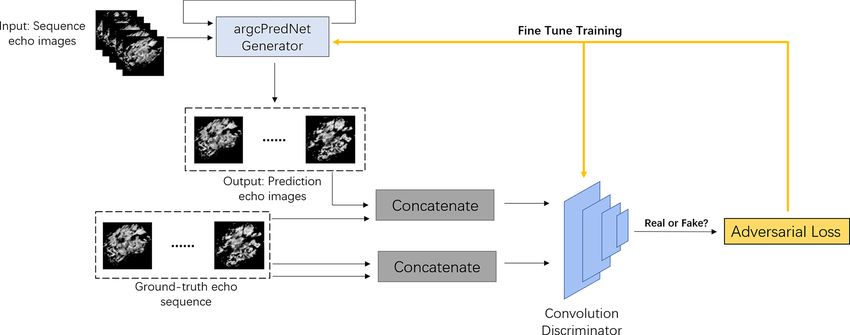
1468 K. Zheng et al.: GAN–argcPredNet v1.0
method are expected to be solved by using a recurrent neural movement and evolution of radar echo based on the U-NET
network (RNN) (Giles et al., 1994). convolutional network for extrapolation prediction (Ayzel et
With the continuous development of deep learning, more al., 2020). PredNet is based on a deep coding framework and
and more neural networks have been applied to the field adds error units to each network layer that can transmit error
of nowcasting. Forecast models such as ConvLSTM and signals like the human brain structure (Lotter et al., 2016).
EBGAN-Forecaster show that this new method’s extrapo- In order to increase the depth of the network and the connec-
lation effect is better than that of optical flow method (Shi tions between modules, Skip-PredNet further introduces skip
et al., 2015; Chen et al., 2019). However, these models still connections and uses ConvGRU as the core prediction unit.
have the problem of blurred and unrealistic prediction im- Experiments show that its effect is better than the TrajGRU
ages (Tian et al., 2020; Xie et al., 2020; Jing et al., 2019). benchmark (Sato et al., 2018). Although these networks can
One of the main reasons is that radar echo maps are typically achieve echo prediction, they have problems with both blur-
multi-modal data acquired by multiple sensors and different ring and producing unrealistic extrapolated images.
stations; some algorithms ignore this feature of radar echo
maps, using the mean square error and mean absolute error 2.2 GAN-based radar echo extrapolation
as the loss function, which is better suited to a unimodal dis-
tribution. The generative adversarial network (GAN) consists of two
The paper proposes a generative adversarial network- parts: a generator and a discriminator (Goodfellow et al.,
argcPredNet (GAN–argcPredNet) network model, which 2014). GAN can be an effective model for generating images.
aims to solve this problem through GAN’s ability to Using an additional GAN loss, a model can better achieve
strengthen the characteristics of multi-modal data model- multi-modal data modeling and each of its outputs will be
ing. The generator adopts the same deep coding–decoding clearer and more realistic (Lotter et al., 2016). Multiple com-
method as PredNet to establish a prediction model, and uses plementary learning strategies show that generative adversar-
a new structure of convolutional long short-term memory ial training can maintain the sharpness of future frames and
(LSTM) as a predictive neuron, which can effectively re- solve the problem of lack of clarity in prediction (Michael et
duce the loss of spatiotemporal information compared with al., 2015). In this regard, the extrapolators built a generative
rgcLSTM. The deep convolutional network is used as the dis- adversarial network to solve the problem of extrapolated im-
criminator to classify the distribution, and the dual-channel age blur by trying to use this adversarial training to extrapo-
input mechanism is used to strictly judge the distribution of late more detailed radar echo maps (Singh et al., 2017). Sim-
real radar echo images. Finally, based on the weather radar ilarly, an adversarial network with ConvGRU as the core was
echo dataset, the generator and the discriminator are alter- proposed, mainly to solve the problem of ConvGRU’s inabil-
nately trained to make the extrapolated radar echo map more ity to achieve multi-modal data modeling (Tian et al., 2020).
real and precise. There are also researchers working on the idea of a four-
level pyramid convolution structure that propose four pairs
of models to generate an adversarial network for radar echo
prediction (Chen et al., 2019). It should be noted that the tra-
2 Related work
ditional GAN network has the problem that it uses unstable
2.1 Sequence prediction networks training, which will cause the model unable to learn. There-
fore, the design of the nowcasting model should be based on
The essence of radar echo image extrapolation is the prob- a stable and optimized GAN network.
lem of sequence image prediction, which can be solved by
implementing an end-to-end sequence learning method (Shi
3 Model
et al., 2015; Sutskever et al., 2014). ConvLSTM introduces
a convolution operation into the conversion of the internal In this section, we describe the model both overall and in de-
data state of the LSTM, effectively utilizing the spatial in- tail. Section 3.1 introduces the overall structure and training
formation of the radar echo data (Shi et al., 2015). However, process of the model. In Sect. 3.2, we describe the structure
the trajectory gated recurrent unit (TraijGRU) has also been of the argcPredNet generator and focus on the argcLSTM
proposed as a solution (Shi et al. 2017) since the location- neuron. In Sect. 3.3, we introduce the design of the discrimi-
invariant nature of the convolutional recursive structure is in- nator and the loss function of the model.
consistent with the natural change motion. A GRU (gated re-
current unit), as a kind of recurrent neural network, performs 3.1 GAN–argcPredNet model overview
a similar function to LSTM but is computationally cheaper
(Group, 2017). Similarly, ConvGRU introduces convolution Radar echo extrapolation refers to the prediction of the dis-
operations inside the GRU to enhance the sparse connectivity sipation and distribution of future echoes based on the exist-
of the model unit and is used to learn video spatiotemporal ing radar echo sequence diagram. If the problem is formu-
features (Ballas et al., 2015). The RainNet network learns the lated, then each echo map can be regarded as a tensor, i.e.,
Geosci. Model Dev., 15, 1467–1475, 2022 https://doi.org/10.5194/gmd-15-1467-2022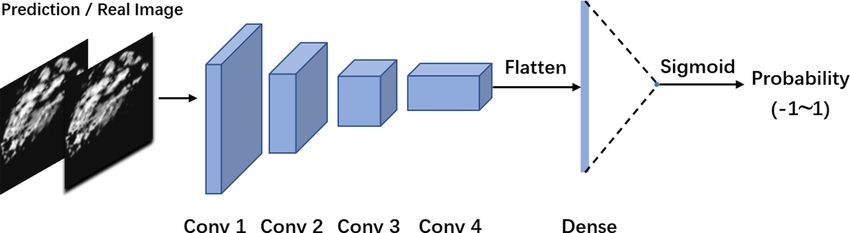
K. Zheng et al.: GAN–argcPredNet v1.0 1469
x ∈ R W×H×C , where W, H and C represent the width, height In Eqs. (2)–(6), ∗ represents convolution operation; ◦ rep-
and number of channels, respectively, and R represents the resents the Hadamard product; σ represents sigmoid nonlin-
feature area. If M represents a given sequence of echo maps ear activation function’ f (t) and g (t) represent the forget gate
and N is used to predict the most likely changes in the fu- and update gate, respectively; and x (t) , h(t) , and C (t) repre-
ture, this problem can be expressed as Eq. (1). This paper sent the input, hidden state, and unit state at time t, respec-
sets the input sequence M and output sequence N to 5 and 7, tively.
respectively.
3.2.2 argcPredNet
t+1 t+N argmax
x̂ , . . ., x̂ = t+1
x , . . ., x t+N The argcPredNet generator has the same structure as Pred-
t+1 t+N t−M+1 t Net, which is composed of a series of repeatedly stacked
p(x , . . ., x |x , . . ., x ) (1)
modules, with a total of three layers. The difference is
Unlike other forecasting models, GAN–argcPredNet uses that argcPredNet uses argcLSTM as the prediction unit. As
WGAN-gp (Wasserstein generative adversarial network with shown in Fig. 3, each layer of the module contains the follow-
gradient penalty) as a predictive framework. The model ing four units: the input convolutional layer (Al ), the recur-
solves the problem of training instability through gradient rent representation layer (Rl ), the prediction convolutional
penalty measures (Gulrajani et al., 2017). Our model mainly layer (Âl ) and the error representation layer (El ).
includes two parts: generator and discriminator. As shown The recursive prediction layer uses the argcLSTM loop
in Fig. 1, the generator is composed of argcPredNet, which unit, which is used to generate the prediction of the next
is responsible for learning the potential features of the data frame and the input of Âl and Al+1 . The network uses error
and simulating the data distribution to generate prediction calculation, where El will output an error representation, and
samples. Following this, the predicted samples and the real the error representation is passed forward through the convo-
samples are input into the discriminator to make a judgment, lutional layer to become the input of the next layer Al+1 . The
where the real data are judged to be true, and thus the pre- hidden state of the recurrent unit Rlt is updated according to
dicted data are judged to be false. Finally, we use the Adam the output of Elt−1 , Rlt−1 and the up-sampled Rl+1 t . For A ,
l
optimizer for training the adversarial loss and then update the input of the lowest target, namely A0 , is set to the actual
the parameters of the discriminator, optimize the loss func- sequence itself. When l > 0, the input of Al is the lower er-
tion of the generator once every five updates and complete ror signal El−1 , which results from convolution calculation,
the update of the generator parameters. The algorithm flow linear rectification function (RELU) activation and the max-
is shown in Table 1 (Gulrajani et al., 2017). imum pooling layer. The complete update rules are shown in
Eqs. (7) to (10). The specific parameter settings of the gener-
3.2 argcPredNet generator ator are shown in Table 2. The numbers 1, 128, 128 and 256
represent the number of filters used from the first layer to the
3.2.1 argcLSTM fourth layer.
The internal structure of the argcLSTM neuron used in the t xt
Al = t
model is shown in Fig. 2. In order to provide better feature- MAXPOOL RELU CONV El−1
extraction capabilities, the structure contains two trainable if l = 0
gating units: the forget gate f (t) and the input gate g (t) . The (7)
0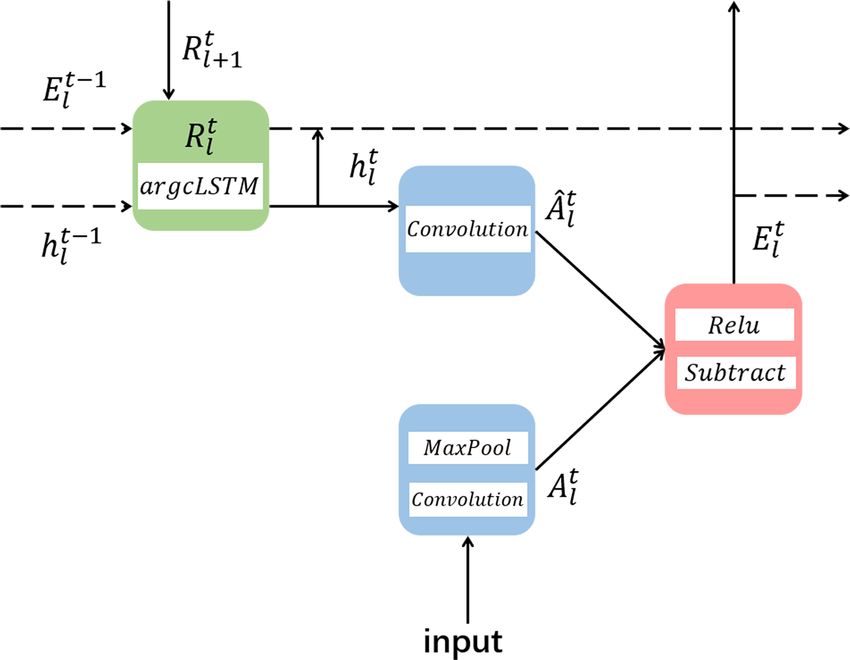
1470 K. Zheng et al.: GAN–argcPredNet v1.0
Figure 1. The schematic of the GAN–argcPredNet architecture.
Table 1. GAN–argcPredNet training algorithm flow.
Algorithm Model uses default values of λ = 10, ncritic = 5, α = 0.0001, β1 = 0.5, β2 = 0.9.
Parameters: The gradient penalty coefficient λ, the number of critic iterations per generator iteration ncritic , the batch
size m, Adam hyperparameters α, β1 , β2 , initial critic parameters ω0 , initial generator parameters θ0 .
1. for i = 1, · · ·epoch do
2. for t = 1· · ·ncritic do
3. for j = 1· · ·m do
4. Sample real data x ∼ Pr , latent variable z ∼ pz , a random number ∼ ∪ [0, 1]
5. x̃ ← Gθ (z)
6. x̂ ← x + (1 − ) x̃
2
L(j ) = Dω (x̃) − Dω (x) + λ ∇x̂ Dω x̂ 2 − 1
7.
8. end for
m
9. ω ← Adam(∇ω m 1 P L(j ) , ωαβ β )
1 2
j =1
10. end for n om
11. Sample a batch of latent variables zj ∼ Pz s
j =1
m
12. 1
θ ← Adam(∇θ m
P
−Dω (Gθ (z)), θαβ1 β2 )
j =1
13. end for
Table 2. Generator parameter settings.
Components Name Filter size No. of filters
Module A Convolution layer 3×3 (1, 128, 128, 256)
Max pool 3×3 /
Unit Âtl Convolution layer 3×3 (1, 128, 128, 256)
Module R Up-sampled 3×3 /
argcLSTM 3×3 (1, 128, 128, 256)
argcPredNet model, a double-channel convolutional neural
network (DC-CNN) network is designed for discrimination.
The process is shown in Fig. 4. It is a four-layer convolution
Figure 2. The internal structure of argcLSTM. model with a dual-channel input method.
The DC-CNN network extracts a pair of images from the
three pairs of images, inputs them to the fully connected layer
Geosci. Model Dev., 15, 1467–1475, 2022 https://doi.org/10.5194/gmd-15-1467-2022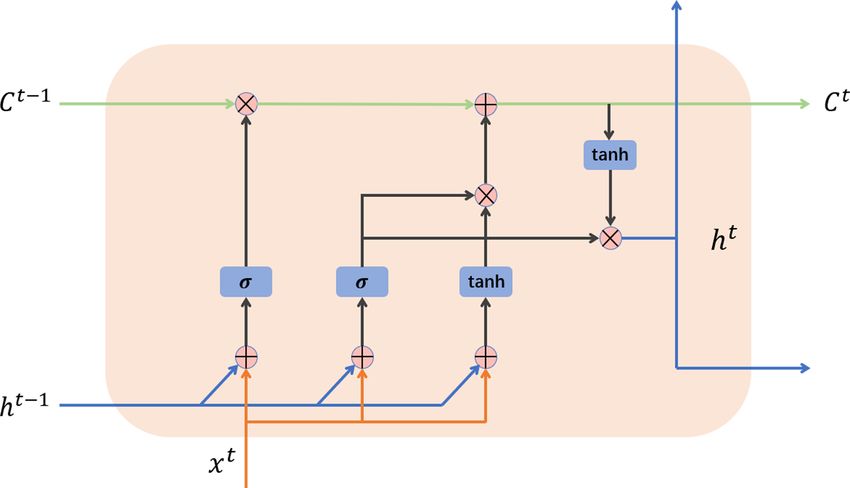
K. Zheng et al.: GAN–argcPredNet v1.0 1471
Table 3. Discriminator parameter settings.
Name Filter size Stride No. of filters Output size
Convolution_1 3×3 2×2 32 48 × 48
Convolution_2 3×3 2×2 64 24 × 24
Convolution_3 3×3 2×2 128 12 × 12
Convolution_4 3×3 2×2 256 6×6
The model has the following maximum–minimum loss func-
tion (Eq. 13):
min max
V (D, G) = Ex̃∼Pg D (x̃) − Ex∼Pr [D (x)]
G D
2
+ λEx̂∼Px̂ ∇x̂ D x̂ 2 − 1 , (13)
where x̃ represents the distribution of generated samples, Pg
Figure 3. Module expansion diagram of layer l at time t. represents the set of generated sample distributions, x repre-
sents the distribution of real samples and Pr represents the
set of real sample distributions. The third term is the penalty
item of the gradient penalty mechanism. In the penalty term,
x̂ represents the actual data and generation of a new sample
formed by random sampling between data. Px̂ represents a
set of randomly sampled samples. λ is a hyperparameter that
represents the coefficient of the penalty term, and the value
in the model is set to 10.
Figure 4. The DC-CNN structure.
4 Experiments
In order to verify the effectiveness of the model, the pa-
through a four-layer convolution transformation and finally per uses the radar echo data from January to July 2020
generates a probability output through the Sigmoid function, in Shenzhen, China, to conduct experiments on the four
indicating the possibility that the input image is from a real models of ConvGRU, rgcPredNet, argcPredNet, and GAN–
image. When the input is a real image, the discriminator will argcPredNet. All experiments are implemented in Python
maximize the probability, and thus the value will approach and based on the Keras deep-learning library with Tensor-
1. If the input is a generator-synthesized image, the discrim- Flow as the back end for model training and testing.
inator will minimize the probability, and thus the value will
approach −1. The specific parameter settings of the discrim- 4.1 Dataset description
inator are shown in Table 3.
This experiment uses the radar echo data of Shenzhen, China.
The dataset is made up of rain images after quality control.
3.3.2 Loss function
The reflectivity range is 0–80 dBZ, the amplitude limit is be-
tween 0 and 255, and the data are collected every 6 min, with
The generative adversarial network relies on the distribution a total of one layer. The height above sea level is 3 km. A to-
of simulated data to generate images. It can retain more echo tal of 600 000 echo images were collected, of which 550 000
details, thereby realizing the modeling of multi-modal data. were used as the training set and 50 000 were used as the test
A gradient penalty term is added to GAN–argcPredNet, and set. Each set of data contained 12 consecutive images. The
the loss function of the discriminator is shown in Eq. (11). horizontal resolution of the radar echo maps is 0.01◦ (about
1 km), the number of grids is 501×501 (i.e., an area of about
2 500 km × 500 km) and the image resolution is 96×96 pixels.
LD = D (x̃) − D (x) + λ ∇x̂ D x̂ 2
−1 (11)
4.2 Evaluation metrics
The generator has the following loss function (Eq. 12):
In order to evaluate the accuracy of the model for precipita-
tion nowcasting, the experiment uses three evaluation indica-
LG = Ex̃∼Pg D (x̃) − Ex∼Pr [D (x)] . (12) tors to evaluate the prediction precision of the model, critical
https://doi.org/10.5194/gmd-15-1467-2022 Geosci. Model Dev., 15, 1467–1475, 20221472 K. Zheng et al.: GAN–argcPredNet v1.0
Figure 5. CSI index score. Figure 7. FAR index score.
Table 4. Rain level
Rain rate (mm h−1 ) Rainfall level
0 ≤ R < 0.5 None or hardly noticeable
0.5 ≤ R < 2 Light
2≤ RK. Zheng et al.: GAN–argcPredNet v1.0 1473
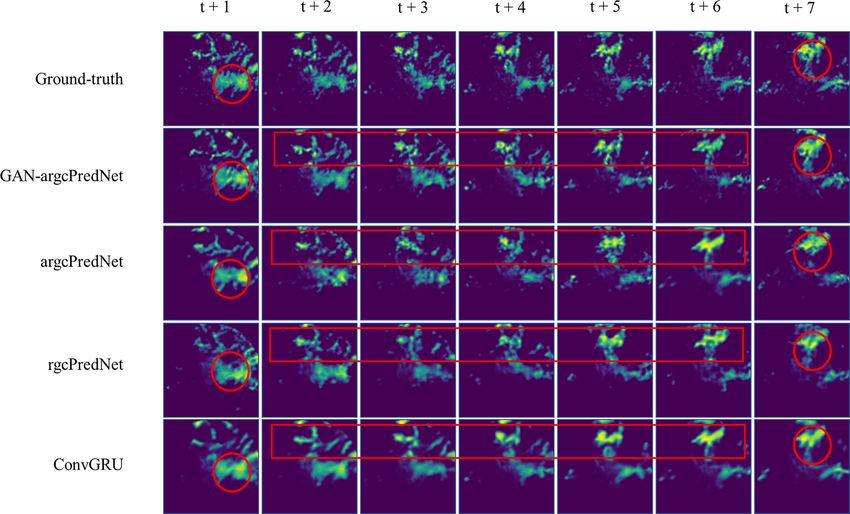
Figure 8. Four prediction examples for the precipitation nowcasting problem. From top to bottom: ground truth frames, prediction by GAN–
argcPredNet, prediction by argcPredNet, prediction by rgcPredNet, prediction by ConvGRU.
rainfall level is 30 ≤ R, its leading advantage is the weak- Table 5. MSE and MSSIM index scores of each model.
est. ArgcPredNet only leads rgcPredNet by a slight mar-
gin, and its performance with rgcPredNet is not as good as Name MSE × 102 ↓ MSSIM ↑
ConvGRU in the range of 2–5 mm h−1 . For POD indicators, ConvGRU 0.950 0.705
GAN–argcPredNet performs best, and its leading advantage rgcPredNet 0.496 0.724
is more prominent. The performance of argcPredNet is not argcPredNet 0.476 0.790
so outstanding as it is almost the same as argcPredNet, but GAN–argcPredNet 0.451 0.833
the index of the two is always better than ConvGRU. For
the FAR score, the performance of GAN–argcPredNet is still
the best, while argcPredNet and rgcPredNet are worse than In order to compare the prediction results more specif-
ConvGRU in the range of 2–5 mm h−1 , and the score for the ically, the experiment uses mean square error (MSE) and
rain rate 0.5–10 mm h−1 interval is slightly lower than that of mean structural similarity (MSSIM) to evaluate the quality
GAN–argcPredNet. of the generated images (Wang et al., 2004). The MSE and
To compare the three methods more intuitively, Fig. 8 MSSIM index scores of the images generated by each model
shows the image prediction results of the three models on are shown in Table 5. ConvGRU has the lowest two indexes.
the same piece of test data. Although the MSE index of rgcPredNet is slightly lower than
Compared with the other three models, GAN–argcPredNet that of the argcPredNet and GAN–argcPredNet models, the
generates better image clarity and shows more detailed fea- MSSIM index of the argcPredNet and GAN–argcPredNet
tures on a small scale. The contrast between the areas models is 0.066 and 0.109 higher than that of the rgcPred-
marked by the red circle in Fig. 8 is more obvious. GAN– Net network model, respectively.
argcPredNet made the best prediction of the shape and in-
tensity of the echo. The area selected by the rectangle mainly
shows the echo changes in the northern region within 30 min. 5 Conclusions
Both models correctly predict the movement of the echo to
a certain extent, and the prediction process shown by GAN– This study demonstrated a radar echo extrapolation model.
argcPredNet is the most complete. In some mixed intensity The main innovations are summarized as follows. First, the
and edge areas, our model clearly predicts the echo intensity argcPredNet generator is established based on the time and
information, which clearly shows the effect of the confronta- space characteristics of radar data. The argcPredNet genera-
tion training. tor can predict future echo changes based on historical echo
observations. Second, our model uses adversarial training
methods to try to solve the problem of blurry predictions.
https://doi.org/10.5194/gmd-15-1467-2022 Geosci. Model Dev., 15, 1467–1475, 20221474 K. Zheng et al.: GAN–argcPredNet v1.0
Based on the evaluation indicators and qualitative analy- References
sis results, GAN–argcPredNet has achieved excellent results.
Our model can reduce the prediction loss in a small-scale Ayzel, G., Scheffer, T., and Heistermann, M.: RainNet v1.0:
space so that the prediction results have more detailed fea- a convolutional neural network for radar-based precipi-
tation nowcasting, Geosci. Model Dev., 13, 2631–2644,
tures. However, the recursive extrapolation method causes
https://doi.org/10.5194/gmd-13-2631-2020, 2020.
the error to accumulate as time goes by, and the prediction re- Ballas, N., Yao, L., Pal, C., and Courville, A.: Delving Deeper into
sult deviates more and more from the true value. In addition, Convolutional Networks for Learning Video Representations,
when the amount of high-intensity echo data is small, the pre- Computer Science, arXiv [preprint], arXiv:1511.06432, 2015.
diction of high-risk and strong convective weather through Bihlo, A.: Precipitation nowcasting using a stochastic variational
machine learning is also a problem that we are very con- frame predictor with learned prior distribution, Computer Sci-
cerned about because it is more realistic. Therefore, we will ence, arXiv [preprint], arXiv:1905.05037, 2019.
carry out research into these two issues in the future. Chen, L., Cao, Y., Ma L., and Jun, Z.: A Deep Learning based
Methodology for Precipitation Nowcasting With Radar, Earth
Space Sci., 7, https://doi.org/10.1029/2019EA000812, 2020.
Code and data availability. The GAN–argcPredNet and Chen, Y. Z., Lin, L. X., Wang, R., Lan, H. P., Ye, Y. M., and Chen, X.
argcPredNet models are free and open source. The cur- L.: A study on the artificial intelligence nowcasting based on gen-
rent version number is GAN–argcPredNet v1.0, and the erative adversarial networks, T. Atmos. Sci., 42, 311–320, 2019.
source code is provided through a GitHub repository Giles, C. L., Kuhn, G. M., and Williams, R. J.: Dynamic recurrent
https://github.com/LukaDoncic0/GAN-argcPredNet (last ac- neural networks: Theory and applications, IEEE T. Neural Net.,
cess: 14 February 2022) and can be accessed through a Zenodo 5, 153–156, 1994.
repository https://doi.org/10.5281/zenodo.5035201 (Zheng and Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-
Liu, 2021a). The pretrained GAN–argcPredNet and argcPredNet Farley, D., Sherjil, O., Aaron, C., and Yoshua, B.: Generative Ad-
weights are available at https://doi.org/10.5281/zenodo.4765575 versarial Networks, in: Advances in neural information process-
(Zheng and Liu, 2021b). The radar data used in the article come ing systems, edited by: Ghahramani, Z., Welling, M., Cortes, C.,
from the Guangdong Meteorological Department. Due to the Lawrence, N., and Weinberger, K. Q., arXiv:1406.2661 2672–
institutional confidentiality policy, the data will not be disclosed 2680, 2014.
to the public. If you need access to the data, please contact Kun Group, N. L. C.: R-NET: Machine Reading Comprehen-
Zheng (zhengk@cug.edu.cn) and Yan Liu (liuyan_@cug.edu.cn). sion with Self-matching Networks, https://www.microsoft.com/
en-us/research/wp-content/uploads/2017/05/r-net.pdf (last ac-
cess: 14 February 2022), 2017.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville
Author contributions. KZ was responsible for developing the mod-
A.: Improved Training of Wasserstein GANs, Computer Science,
els and writing the manuscript. YL and QT conducted the model
arXiv [preprint], arXiv:1704.00028, 2017.
experiments and co-authored the manuscript. JZ, CL, ST, HR, YY
Jing, J., Li, Q., and Peng, X.: MLC-LSTM: Exploiting the Spa-
and XR were responsible for data screening and preprocessing.
tiotemporal Correlation between Multi-Level Weather Radar
Echoes for Echo Sequence Extrapolation, Sensors, 19, 3988,
https://doi.org/10.3390/s19183988, 2019.
Competing interests. The contact author has declared that neither Lotter, W., Kreiman, G., and Cox, D.: Deep predictive coding net-
they nor their co-authors have any competing interests. works for video prediction and unsupervised learning, Computer
Science, arXiv [preprint], arXiv:1605.08104v5, 2016.
Luo, C., Li, X., Ye, Y., Wen, Y., and Zhang, X.: A
Disclaimer. Publisher’s note: Copernicus Publications remains Novel LSTM Model with Interaction Dual Attention
neutral with regard to jurisdictional claims in published maps and for Radar Echo Extrapolation, Remote Sensing, 13, 164,
institutional affiliations. https://doi.org/10.3390/rs13020164, 2020.
Luo, C., Li, X., and Ye, Y.: PFST-LSTM: A Spatio Tempo-
ral LSTM Model With Pseudoflow Prediction for Precipi-
Acknowledgements. This research was funded by Science and tation Nowcasting, IEEE J. Sel. Top. Appl., 14, 843–857,
Technology Planning Project of Guangdong Province, China (grant https://doi.org/10.1109/JSTARS.2020.3040648, 2021.
no. 2018B020207012). Michael, M., Camille, C., and Yann, L.: Deep multi-scale video
prediction beyond mean square error, Computer Science arXiv
[preprint], arXiv:1712.09867v3, 2015.
Financial support. This research has been supported by the Sci- Sato, R., Kashima, H., and Yamamoto, T.: Short-term precip-
ence and Technology Planning Project of Guangdong Province itation prediction with skip-connected prednet, in: Interna-
(grant no. 2018B020207012). tional Conference on Artificial Neural Networks, 373–382,
https://doi.org/10.1007/978-3-030-01424-7_37, 2018.
Shangzan, G., Da, X., and Xingyuan, Y.: Short-Term Rainfall Pre-
Review statement. This paper was edited by David Topping and re- diction Method Based on Neural Networks and Model Ensemble,
viewed by one anonymous referee. Advances in Meteorological Science and Technology, 7, 107–
113, 2017.
Geosci. Model Dev., 15, 1467–1475, 2022 https://doi.org/10.5194/gmd-15-1467-2022K. Zheng et al.: GAN–argcPredNet v1.0 1475
Shi, X., Chen, Z., Wang, H., Dit-Yan, Y., Wai-Kin, W., and Wang- Sutskever, I., Vinyals, O., and Le, Q. V.: Sequence to Sequence
chun, W.: Convolutional LSTM network: A machine learning ap- Learning with Neural Networks, in: Advances in Neural Infor-
proach for precipitation nowcasting, in: Advances in neural infor- mation Processing Systems, edited by: Ghahramani, Z., Welling,
mation processing systems, edited by: Cortes, C., Lawrence, N. M., Cortes, C., Lawrence, N. D., and Weinberger, K. Q., 3014–
D., Lee, D. D., Sugiyama, M., and Garnett, R., 802–810, 2015. 3112, https://doi.org/10.5555/2969033.2969173, 2014.
Shi, X., Gao, Z., Lausen, L., Wang, H., Dit-Yan, Y., Wai-Kin, W., Tian, L., Xutao, L., Yunming, Y., Pengfei, X., and Yan, L.: A Gener-
and Wang-chun, W.: Deep learning for precipitation nowcasting: ative Adversarial Gated Recurrent Unit Model for Precipitation
A benchmark and a new model, in: Advances in neural informa- Nowcasting, IEEE Geosci. Remote S., 17, 601–605, 2020.
tion processing systems, edited by: Guyon, I., Luxburg, U. V., Wang, G., Liu, L., and Ruan, Z.: Application of Doppler Radar Data
Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Gar- to Nowcasting of Heavy Rainfall, J. Appl. Meteorol. Sci., 388,
nett, R., 5617–5627, arXiv:1706.03458, 2017. 395–417, 2007.
Singh, S., Sarkar, S., and Mitra, P.: A deep learning based approach Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.: Image
with adversarial regularization for Doppler weather radar echo quality assessment: from error visibility to structural similarity,
prediction, 2017 IEEE International Geoscience and Remote IEEE T. Image Process., 13, 600–612, 2004.
Sensing Symposium (IGARSS), 5205–5208, https://ieeexplore. Xie, P., Li, X., Ji, X., Chen, X., Chen, Y., Jia, L., and Ye, Y.: An
ieee.org/document/8128174 (last access: 14 February 2022), Energy-Based Generative Adversarial Forecaster for Radar Echo
2017. Map Extrapolation, IEEE Geosci. Remote S., 99, 1–5, 2020.
Sun, J., Xue, M., Wilson, J. W., ISztar, Z., Sue, P., Jeanette O., Zheng, K. and Liu, Y.: GAN-argcPredNetv1.0
Paul, J., Dale, M., Ping-Wah, L., Brian, G., Mei, X., and James, and argcPredNet models (v1.0), Zenodo [code],
P.: Use of NWP for nowcasting convective precipitation: Recent https://doi.org/10.5281/zenodo.5035201, 2021a.
progress and challenges, B. Am. Meteorol. Soc., 95, 409–426, Zheng, K. and Liu, Y.: Pretrained weights of GAN-
https://doi.org/10.1175/BAMS-D-11-00263.1, 2014. argcPredNet and argcPredNet models (v1.0), Zenodo [code],
https://doi.org/10.5281/zenodo.4765575, 2021b.
https://doi.org/10.5194/gmd-15-1467-2022 Geosci. Model Dev., 15, 1467–1475, 2022You can also read

















































