GAIA at SM-KBP 2020 - A Dockerized Multi-media Multi-lingual Knowledge Extraction, Clustering, Temporal Tracking and Hypothesis Generation System ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
GAIA at SM-KBP 2020 - A Dockerized Multi-media Multi-lingual
Knowledge Extraction, Clustering, Temporal Tracking and Hypothesis
Generation System
Manling Li1 , Ying Lin1 , Tuan Manh Lai1 , Xiaoman Pan1 , Haoyang Wen1 , Sha Li1
Zhenhailong Wang1 , Pengfei Yu1 , Lifu Huang1 , Di Lu1 , Qingyun Wang1
Haoran Zhang1 , Qi Zeng1 , Chi Han1 , Zixuan Zhang1 , Yujia Qin1
Xiaodan Hu1 , Nikolaus Parulian1 , Daniel Campos1 , Heng Ji1
1
University of Illinois at Urbana-Champaign hengji@illinois.edu
Brian Chen2 , Xudong Lin2 , Alireza Zareian2 , Amith Ananthram2 , Emily Allaway2
Shih-Fu Chang2 , Kathleen McKeown2
2
Columbia University sc250@columbia.edu, kathy@cs.columbia.edu
Yixiang Yao3 , Michael Spector3 , Mitchell DeHaven3 ,
Daniel Napierski3 , Marjorie Freedman3 , Pedro Szekely3
3
Information Sciences Institute, University of Southern California mrf@isi.edu
Haidong Zhu4 , Ram Nevatia4
4
University of Southern California nevatia@usc.edu
Yang Bai , Yifan Wang5 , Ali Sadeghian5 , Haodi Ma5 , Daisy Zhe Wang5
5
5
University of Florida daisyw@ufl.edu
1 Introduction and cross-instance interactions. As O NE IE
does not use any language-specific feature,
We participated in the SM-KBP 2020 evaluation we prove it can be easily applied to new lan-
using our dockerized GAIA system, an end-to- guages or trained in a multilingual manner.
end knowledge extraction, grounding, inference,
clustering, temporal tracking and hypothesis gen- • Document-Level Event Argument Role
eration system, as shown in Figure 1. Our TA1 Labeling: Event extraction has long been
system achieves top performance at both intrinsic treated as a sentence-level task in the Infor-
evaluation and extrinsic evaluation through TA2 mation Extraction community. We argue that
and TA3. In the past year, we integrate the fol- this setting does not match human informa-
lowing innovations: tive seeking behavior and leads to incomplete
and uninformative extraction results. We pro-
• Multilingual Joint Information Extraction pose a document-level neural event argument
with Global Knowledge: We propose an extraction model by formulating the task as
end-to-end neural model O NE IE to extract conditional generation following event tem-
entities, relations and events jointly in a lan- plates.
guage independent fashion. Existing joint
neural models for Information Extraction • Symbolic Semantics Enhanced Event
(IE) use local task-specific classifiers to pre- Coreference Resolution: We propose a
dict labels for individual instances (e.g., trig- novel context-dependent gated module to
ger, relation) regardless of their interactions. incorporate a wide range of symbolic fea-
For example, a VICTIM of a DIE event is tures (e.g., event types and attributes) into
likely to be a VICTIM of an ATTACK event event coreference resolution. Simply con-
in the same sentence. Our model can cap- catenating symbolic features with contextual
ture such cross-subtask and cross-instance embeddings is not optimal, since the features
inter-dependencies, we extract the globally can be noisy and contain errors. Also,
optimal information network by consider- depending on the context, some features can
ing the inter-dependency among nodes and be more informative than others. Therefore,
edges. At the decoding stage, we incorporate the gated module extracts information from
global features to capture the cross-subtask the symbolic features selectively. Combined
Multimedia News Visual Entity Extraction Visual Entity Linking Visual Entity Coreference
Faster R-CNN ClassActivation Flag Generic Face
FaceNet
ensemble Map Model Recognition Features Features
MTCNN Face Fusion and Landmark Matching DBSCAN Heuristics
Images and Video Key Frames Detector Pruning Clustering Rules
English Russian Ukrainian
Multi-lingual Text Content Background KB Visual KB
Text End-to-End Joint IE Text Entity Coreference Text Event Coreference Cross-Media Fusion
Joint Entity, Relation, Event Collective Entity Linking Symbolic Semantics Enhanced Visual Grounding
Extraction with Global Features and NIL Clustering Event Coreference
Cross-modal Entity Linking
Document-Level Symbolic Semantics Enhanced Graph based
Argument Extraction Nominal Coreference Coreference Resolution
Cross-Media Event
Visual Event Extraction
Text Fine-grained Typing Temporal Attribute Extraction
Cross-modal Event Linking
Entity Fine-grained Typing Graph Attention Networks based
Attention-based External Knowledge Guided Extraction and Propagation
Fine-grained Typing Fine-grained Typing
Multimedia KB
Relation Fine-grained Typing Event Fine-grained Typing Explicit/Implicit Relation
Dependency based FrameNet &Rule
Dependency
based based Explicit / Implicit Scoring
Fine-Grained Event Typing Fine-Grained
Fine-GrainedEvent
EventTyping
Typing Event Source Identification Textual KB
Figure 1: The architecture of GAIA multimedia knowledge extraction system.
with a simple regularization method that tion types whose expression is both explicit
randomly adds noise to the features during and implicit (like blame). In addition to these
training, our best event coreference models challenging relation types, this component
achieve state-of-the-art results on public also identifies source information for every
benchmark datasets such as ACE 2005 and event, enabling better perspective clustering
KBP 2016. during TA3 hypothesis generation.
• Event Temporal Attribute Extraction and • Cross-media Structured Common Seman-
Propagation via Graph Attention Net- tic Space for Multimedia Event Extrac-
works: We propose a graph attention net- tion: We propose and develop a new multi-
works based approach to propagate tempo- media Event Extraction (M2E2) task that in-
ral information over document-level event volves jointly extracting events and argu-
graphs constructed by shared entity argu- ments from text and image. We propose a
ments and temporal relations. To better eval- weakly supervised framework which learns
uate our approach, we have developed a chal- to encode structures extracted from text and
lenging new benchmark, where more than images into a common semantic embedding
78% of events do not have time spans men- space. This structured common space en-
tioned explicitly in their local contexts. The ables us to share and transfer resources across
proposed approach yields an absolute gain of data modalities for event extraction and argu-
7.0% in match rate over contextualized em- ment role labeling.
bedding approaches, and 16.3% higher match
rate compared to sentence-level manual event • Video Multimedia Event Extraction and
time argument annotation. argument labeling We extend the multi-
media Event Extraction (M2E2) task to ex-
• Implicit/Explicit Relation Extraction and tracts events and arguments from videos and
Source Identification: We extend our infor- article pairs. We propose a self-supervised
mation extraction capabilities with an ensem- multimodal transformer that learns the multi-
ble of neural zero-shot and few-shot tech- modal context from each modality by utiliz-
niques designed to identify a subset of rela- ing the self-attention mechanism and learning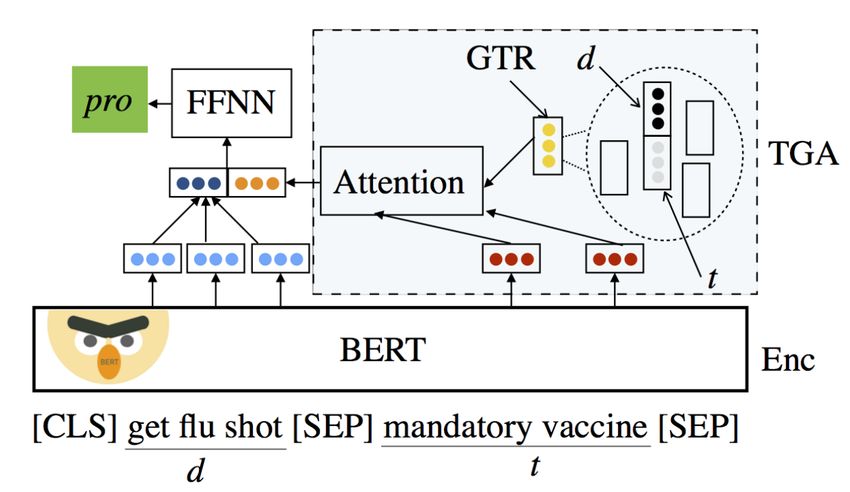
Elliott testified that on April 15, McVeigh came into the body
to predict the event types and argument roles shop and reserved the truck, to be picked up at
4pm two days later.
from both modalities in a sequential decoder. Document
Elliott said that McVeigh gave him the $280.32 in exact
This proposed architecture allows us to fully change after declining to pay an additional amount for
insurance.
learn the interaction between event and argu- Prosecutors say he drove the truck to Geary Lake in Kansas,
ment information from both modalities and that 4,000 pounds of ammonium nitrate laced with
nitromethane were loaded into the truck there, and that it was
jointly extract events and argument roles. driven to Oklahoma City and detonated.
bought, sold, or traded to in exchange
Template
for for the benefit of at place
2 TA1 Text Knowledge Extraction
Elliott bought, sold or traded truck to McVeigh in exchange for
Output
2.1 Approach Overview $280.32 for the benefit of at body shop place
We dockerize an end-to-end fine-grained knowl- Arg 1 Arg 4 Arg 3
Giver: PaymentBarter: AcquiredEntity:
edge extraction system for 179 entity types, 149 Elliot $280.32 truck
event types, and 50 event types defined in AIDA Arg 2 Recipient: Arg 6 Place:
ontology. As shown in Figure 1, it supports the McVeigh body shop
joint extraction of entities, relations and events
Figure 2: An example of document-level argument ex-
from multilingual corpus (English, Russian and traction formulated as text generation.
Spanish), and performs coreference resolution
over entities and events. We will present the de-
tails of each component in the following sections. The generated output is a filled template where
placeholders are replaced by concrete arguments.
2.2 Joint Entity, Relation and Event Mention Note that one template is used for all event in-
Extraction stances within the same type and such templates
We use a sentence-level joint neural model (Lin are already part of the AIDA ontology.
et al., 2020) to extract entities, relations, and Our base model is an encoder-decoder language
events from text. For English, we train two sep- model BART (Lewis et al., 2020). The gener-
arate IE models. The first model is trained on ation process models the conditional probability
ACE and ERE English data that are mapped to the of selecting a new token given the previous to-
AIDA ontology. Another model is trained on doc- kens and the input to the encoder. To utilize
uments we annotate for new AIDA types. Sim- the encoder-decoder LM for argument extraction,
ilarly, we trained two IE models for Spanish on we construct an input sequence of hsi template
ERE data and our own annotations respectively. hsih/sidocument h/si. All argument names (arg1,
We further enhance the Spanish model with trans- arg2 etc.) in the template are replaced by a single
fer learning by adding English training data with a special placeholder token hargi.
lower sampling rate (0.1 in our experiments). For The generation probability is computed by tak-
Russian, we only train a single model on our Rus- ing the dot product between the decoder output
sian and English annotations in a multilingual way and the embeddings of tokens from the input. To
because it is not included in ACE or ERE. We use prevent the model from hallucinating arguments,
RoBERTa (Liu et al., 2019) for English and XLM- we restrict the vocabulary of words to Vc : the set
RoBERTa (Conneau et al., 2019) for Spanish and of tokens in the input.
Russian to obtain contextualized word representa-
Softmax hTi Emb(w)
w ∈ Vc
p(xi = w|x
multiple arguments, we add the keyword “add” be- from Wikipedia (Ji et al., 2009) to translate each
tween the arguments. For example in ACE 2005 mention into English first.
we have this sentence: “Afterwards Shalom was
2.6.2 Entity Coreference Resolution
to fly on to London for talks with British Prime
Minister Tony Blair and Foreign Secretary Jack For Russian entity coreference resolution, we fol-
Straw.”. The input template is “hargi met with low the approach of Li et al. (2019). For English
hargi at hargi place” and the generation output is and Spanish, we implement neural models simi-
“Shalom met with Tony Blair and Jack Straw at lar to the bert-coref model (Joshi et al., 2019).
London place”. However, there are several important differences.
To align the predictions of the model back to the First, we remove the higher-order inference (HOI)
text for downstream modules, we adopt the simple layer (Lee et al., 2018) from the original architec-
heuristic of matching the closest occurrence of the ture. Our preliminary results suggest that HOI typ-
predicted argument to the trigger. ically does not improve the coreference resolution
performance while incurring additional computa-
2.4 Informative Justification Extraction tional complexity. This observation agrees with
a recent analysis of Xu and Choi (2020). Sec-
For named entities, we generate informative jus-
ond, we also apply a simple heuristic rule based
tification using the longest name mention. For
on the entity linking results to refine the predic-
nominal entities, we apply a syntactic tree parser1
tions of the neural models. We prevent two entity
and select the sub-tree whose syntactic head word
mentions from being merged together if they are
matches the nominal entity mention. For events,
linked to different entities with high confidence.
we use the first substring covering the trigger word
For English, we use SpanBERT (large) (Joshi
and arguments as informative justification.
et al., 2020) as the Transformer encoder and train
2.5 Fine-grained Typing the system on ACE 2005 (Walker et al., 2006),
EDL 20162 , EDL 20173 , and OntoNotes (English)
We follow (Li et al., 2019) to detect fine-grained
(Pradhan et al., 2012). For Spanish, we use XLM-
types for entities, relations and events. For event
Roberta (large) (Conneau et al., 2020) and train the
fine-grained typing, we annotate the newly added
system on OntoNotes (Spanish) (Pradhan et al.,
ten event types and train an extractor for these new
2012), DCEP (Dias, 2016), and SemEval 2010
types.
(Recasens et al., 2010).
As aforementioned in Section 2.2, we train sep-
arate IE models on different datasets and combine 2.7 Event Coreference Resolution
their outputs. Although ACE and ERE datasets
For Russian event coreference resolution, we fol-
contain much more training instances with higher
low the approach of Li et al. (2019). For English
annotation quality, they only cover an incomplete
and Spanish, we implement a single cross-lingual
set of event types in the AIDA ontology. By con-
model that incorporates a wide range of symbolic
trast, our new datasets are smaller but have a more
features into event coreference resolution. Given
complete coverage of the new types. Therefore,
an input document D consisting of n tokens, our
we prioritize results predicted by models trained
model first forms a contextualized representation
on ACE and ERE data when resolving conflicts in
for each input token, using the multilingual
the process of merging IE results. For example,
XLM-RoBERTa (XLM-R) Transformer model
if the first model predicts “Brooklyn Bridge” as a
(Conneau et al., 2020). Let X = (x1 , ..., xn ) be the
FAC entity, while the second model predicts it as a
output of the Transformer encoder, where xi ∈ Rd .
LOC , we keep the FAC label in this case.
2.6 Entity Linking and Coreference Single-Mention Encoder For each (predicted)
Resolution event mention mi , its trigger’s representation ti is
2.6.1 Entity Linking defined as the average of its token embeddings:
ei
We follow (Li et al., 2019) to link entities to back- X xj
ti = (3)
ground KB and Freebase for English and Russian. ei − si + 1
j=si
For Spanish, we use translation dictionaries mined
2
LDC2017E03
1 3
https://spacy.io/ LDC2017E52We assume that each mi has K different sym- optimal mixture, gij is used to control the compo-
bolic features associated with it (e.g., its predicted sition. The decomposition unit is defined as:
event type and attributes). Using K trainable em-
(u)
bedding matrices, we convert the symbolic fea- (u) hij · tij
(1) (2) (K) Parallel pij = tij
tures of mi into K vectors {hi , hi , . . . , hi }, tij · tij (8)
(u)
where hi ∈ Rl . Orthogonal
(u)
oij =
(u)
hij −
(u)
pij
Mention-Pair Encoder Given two event men- where · denotes dot product. The parallel compo-
tions mi and mj , we define their trigger-based pair (u) (u)
nent pij is the projection of hij on tij . It can be
representation as:
viewed as containing information that is already
(u)
part of tij . oij is orthogonal to tij , and so it can
tij = FFNNt ti , tj , ti ◦ tj (4)
be viewed as containing new information.
where FFNNt is a feedforward network mapping
from R3×d → Rp , and ◦ is element-wise multipli- Mention-Pair Scorer After using CDGMs to
cation. Similarly, we compute their feature-based distill symbolic features, the final pair representa-
(1) (2) (K) tion fij of mi and mj can be computed as follows:
pair representations {hij , hij , . . . , hij } as fol-
lows: (1) (2) (K)
fij = [tij , hij , hij , . . . , hij ] (9)
(u) (u) (u) (u) (u)
hij = FFNNu hi , hj , hi ◦ hj (5) And the coreference score s(i, j) of mi and mj is:
where u ∈ {1, 2, . . . , K}, and FFNNu is a feed-
s(i, j) = FFNNa (fij ) (10)
forward network mapping from R3×l → Rp .
where FFNNa is a mapping from R(K+1)×p → R.
Symbolic Features Incorporation In our dock-
erized GAIA system, we predict the symbolic fea- Noisy Training We use the same loss function
tures using simple predictors. As a result, the as in (Lee et al., 2017). We also notice that
symbolic features can be noisy and contain errors. the training accuracy of a feature predictor is
Also, depending on the specific context, some fea- typically near perfect. Therefore, if we simply
tures can be more useful than others. Inspired train our model without any regularization, our
by previous studies on gating mechanisms (Lin CDGMs will rarely come across noisy symbolic
et al., 2019; Lai et al., 2019), we propose Context- features during training. Therefore, to encourage
Dependent Gated Module (CDGM), which uses our CDGMs to actually learn to distill reliable sig-
a gating mechanism to extract information from nals, we also propose a simple but effective noisy
the input symbolic features selectively. Given two training method. Before passing a training data
mentions mi and mj , we use their trigger feature batch to the model, we randomly add noise to
vector tij as the main controlling context to com- the predicted features. More specifically, for each
(u) document D in the batch, we go through every
pute the filtered representation hij :
symbolic feature of every event mention in D and
(u)
hij = CDGM(u) tij , hij
(u)
(6) consider sampling a new value for the feature.
Training Datasets For English, we train the sys-
where u ∈ {1, 2, . . . , K}. More specifically:
tem on ACE 2005 (Walker et al., 2006) and KBP
(u) (u) (u) 2016 (Mitamura et al., 2016). For Spanish, we
gij = σ FFNNg tij , hij
train the system on ERE-ES (Song et al., 2015).
(u) (u) (u)
oij , pij = DECOMPOSE tij , hij (7)
2.8 Temporal Attribute Extraction
(u) (u) (u) (u) (u)
hij = gij ◦ oij + 1 − gij ◦ pij For English documents, we first use Stanford
(u) CoreNLP (Manning et al., 2014) to perform time
where σ denotes sigmoid function. FFNNg is a expression extraction and normalization for all
(u)
mapping from R2×p → Rp . At a high level, hij documents. Then we perform sentence-level time
is decomposed into an orthogonal component and argument extraction. Specifically, we fine-tuned
(u)
a parallel component, and hij is simply the fu- BERT on ACE 2005 event time argument annota-
sion of these two components. In order to find the tions. We use the representation of the first tokenof an event span and a time span to perform pair- start-of-the-art, “Matching the Blanks” (MTB)
wise classification. (Soares et al., 2019) which extends Harris’ dis-
We further propagate local event time tributional hypothesis (Harris, 1954) to relations.
to document-level using graph attention Soares et al. assume that the informational redun-
networks (Velickovic et al., 2018). We dancy of very large text corpora (e.g., Wikipedia)
construct document-level event graphs as results in sentences that contain the same pair
G = {(ei , vj , ri,j )}, where each bi-directed edge of entities generally expressing the same relation.
ri,j represents the argument role between an event Thus, an encoder trained to collocate such sen-
ei and an entity or time expression vj . We first tences can be used to identify the relation between
obtain token representation from BERT for all entities in any sentence s by finding the labeled
sentences in a document. Then we use the average relation example whose embedding is closest to s.
representation for event triggers, entities and time While MTB is very successful, it relies on a
expressions that contains multiple tokens. To huge amount of data, making it difficult to retrain
propagate information from connected nodes, in English or any other language with standard
we use a two-layer graph attention networks computational resources. To address this chal-
that will update the representations for events, lenge, we assume that sections of news corpora
entities and time expressions. We use a two-layer exhibit even more informational redundancy than
feed-forward networks to estimate the probability Wikipedia. Specifically, news in the days follow-
to fill time expression tj in event ei ’s 4-tuple ing an event (e.g., the 2006 World Cup) frequently
time elements. To resolve conflict, we use a re-summarizes the event before adding new de-
greedy approach that choose 4-tuple element tails. As a result, news exhibits a strong form of
candidates based on the descending order of their local consistency over short rolling time windows
probabilities, and fill in the time if there is no where otherwise fluid relations between entities
conflict, otherwise we drop the candidate. remain fixed. For example, the relation between
For English relations, Spanish and Russian Italy and France as expressed in a random piece of
events and relations, we use the document creation text is dynamic and context-dependent, spanning a
time as the latest start time and earliest end time. wide range of possibilities that include “enemies”,
“neighbors” and “allies”. But, in the news cover-
3 TA1 Explicit/Implicit Relation age following the 2006 World Cup, it is static –
Extraction they are sporting competitors. Therefore, by con-
We employ a separate component to handle the ex- sidering only sentences around specific events, we
traction of relations in the AIDA ontology whose extract groups of statements that express the same
expression is more diverse than standard onto- relation and are relatively free of noise.
logical relations like f ather − of . These rela- Using this method, we extract a distantly su-
tions are sponsorship, blame, deliberateness, le- pervised training corpus in English, Spanish and
gitimacy, hoax-fraud, and sentiment. Extracting Russian from the Reuters RCV1 and RCV2
these types is extremely challenging as 1) they are newswire corpora (Lewis et al., 2004) guided by
data scarce (there are few, if any, gold label ex- date-marked event descriptions from Wikipedia.
amples) and 2) they can be expressed both explic- We use this corpus to train multilingual BERT
itly, using identifiable trigger words, and implic- (Devlin et al., 2018) to produce high quality
itly. For example, the blame relation is clear in general-purpose relation representations from re-
both “Maduro blamed the protestors for the attack lation statements. We adopt the common defini-
and “Maduro had the protestors arrested for the at- tion of a relation statement in the literature: a triple
tack” but in the latter it must be inferred. As such, r = (x, s1 , s2 ) where x = [x0 ... xn ] is a sequence
we deploy an ensemble of few-shot techniques for of tokens and s1 = (i, j) and s2 = (k, l) are the in-
explicit and implicit information extraction. dices of special start and end identifier tokens that
demarcate the two entity mentions in x. mBERT
3.1 Explicit Relation Scoring maps this relation statement to a fixed-length vec-
To extract explicit relations, we incorporate tor h ∈ Rd . The vector h represents the relation
our work on few-shot neural relation extraction between the entity mentions identified by s1 and
(Ananthram et al., 2020). It builds on the current s2 as expressed in x. The cosine similarity be-tween f (r) and f (rO ) should be close to 1 if and
only if r and rO express the same relation. That
is to say, mBERT should collocate sentences that
exhibit similar relations.
To incorporate this work into the AIDA
pipeline, we rely on the entity and event extrac-
tions from earlier components to produce candi-
date relation statements for the AIDA corpus. We
compare each candidate to the gold labeled exem-
plars for each relation provided by LDC, produc-
ing similarity scores for each candidate / relation Figure 3: Architecture of TGA Net. Enc indicates
exemplar pair between 0 and 1. These scores are contextual conditional encoding, GTR indicates Gen-
eralized Topics Representation, TGA indicates Topic-
then considered by our final aggregation step when
grouped Attention
deciding whether or not to accept a particular can-
didate relation statement.
tering of sentences and topics from our training
3.2 Implicit Relation Scoring data and treat its centroid as our generalized topic
To identify implicit relations, we augment rela- representation r. Using r, we compute the simi-
tion candidates with stance (pro, con and neutral) larity between t and all topics seen during training
scores meant to capture the valence towards a par- via learned scaled dot-product attention (Vaswani
ticular entity or event whose expression may be et al., 2017) and use these similarity scores to pro-
subtle. This information provides useful signal duce a weighted average of our topic tokens c
for the identification of relations that have intrin- that captures the relationship between t and related
sic positive or negative connotations. For example, topics and documents. Finally, we concatenate our
sentences that blame an individual for an event of- embeddings of s and t with c and pass it through
ten take a negative position towards that individual several feed-forward layers to produce a probabil-
that can only be inferred implicitly (e.g., “Maduro ity distribution over our three stance labels: pro,
blamed outside agitators for the attack”). con and neutral.
To incorporate this work into the AIDA
To produce these scores, we incorporate our
pipeline, we augment every relation candidate
work on zero-shot stance detection (Allaway and
with the stance score towards each entity or event
McKeown, 2020). In that work, we present a new
in the relation statement. As with our explicit rela-
dataset for the challenging task of generalizable
tion scores, these scores are considered by our fi-
stance detection on unseen topics. This corpus
nal aggregation step when deciding whether or not
captures a wider range of topics and lexical varia-
to accept a particular candidate relation statement.
tion than in previous datasets. Using this dataset,
we design and train a new model for stance de-
3.3 Aggregating Scores
tection that captures relationships between topics
without supervision and beats the state-of-the-art In addition to our new explicit and implicit re-
on a number of challenging linguistic phenomena. lation scoring components, we augment our can-
This new model, Topic-Grouped Attention didate relation statements with trigger-based and
(TGA) Net, consists of 1) a BERT-based contex- sentiment-based scores from our existing system,
tual conditional encoding layer, 2) topic-grouped presented as part of (Li et al., 2019). We use
attention using generalized topics representations highly regularized decision trees trained on dozens
and 3) a feed-forward neural network (see Figure of examples from AIDA practice corpora which
3). Given a sentence s and a topic t, the contextual we manually annotated to make the ultimate ac-
conditional encoding layer first embeds the pair ceptance decision based on these scores.
using BERT (Devlin et al., 2018), resulting in se-
3.4 Event Source Information
quences of token embeddings for the sentence s
and for the topic t. We use a concatenation of tf- Finally, to enable better perspective clustering dur-
idf weighted averages of the embeddings of s and ing TA3 hypothesis generation, we adapt our ex-
t to find the closest cluster in a hierarchical clus- plicit relation extraction system to identify thesource of all event information along with a con- images and entities from the text) and is used to
fidence score. For example, in the sentence discover event-level information.
“Maduro says the protests seeking to oust him We followed our previous visual grounding sys-
are backed by the United States.”, we identify tem (Zhang et al., 2018) which extracts a multi-
“Maduro” as the source of extracted Protest event. level visual feature map for each image in a doc-
ument. For each word (or phrase, entity mention,
4 TA1 Visual Knowledge Extraction etc.), we compute an attention map to every fea-
ture map location to localize the query by com-
We first review our Visual Knowledge Extraction
puting the similarity between the word and region.
(VKE) system (Li et al., 2019) last year and intro-
On the other hand, our network takes each sen-
duce our new component from our current system.
tence of the document and represents each word
Our system further combines information from
using a language model. We calculate the sentence
multimodal sources at the entity level (grounding)
to image similarity score using all pairs in the doc-
and at the event level (event-type, argument roles),
ument to find potential co-referenced events across
which serves multimodal information from differ-
modality. Details will be described in the later sec-
ent modalities as complementary to each other.
tion.
4.1 Entity Detection 4.4 Event and argument role extraction
The object detection system contains four different Besides extracting entity information from images
systems: three Faster R-CNN (Ren et al., 2015) and videos, we also extract visual events and their
models and a weakly supervised CAM model argument roles from visual data. To train our
(Zhou et al., 2016). We followed the same pro- system, we have collected a dataset called video
cess (Li et al., 2019) to aggregate the results from M2E2, which contains 4.5K video-article pairs
a different model and created a new mapping for from YouTube news channels. We start from 20
the classes to the new m36 ontology. For face de- event types defined in AIDA ontology, which is vi-
tection, we use an MTCNN model (Zhang et al., sually detectable and search on news channels. In
2016). For the overlapped detection between the the end, we annotated 1.2K video article pairs for
general object model and face model, we create a training and evaluation. Given the annotation, we
cluster using the object detection result with the have developed several models on top of this data.
largest bounding box as the prototype to represent First, we have trained an image-based model using
the detected result. Joint Situation Localizer (JSL (Pratt et al., 2020)).
We combine the annotation of video M2E2 and the
4.2 Entity Recognition
Swig (Pratt et al., 2020) data and map the event
The entity recognition pipeline is done by face types and argument roles to the AIDA ontology.
recognition models FaceNet (Schroff et al., 2015) In this setting, the model can detect argument roles
where we recognize predefined name list recog- that were not defined in the Swig data, such as vi-
nized by the text named-entity recognition model. sual display in the protest event.
We covered around 500 names in our current sys-
tem. 4.5 Multimodal event coreference
We further extended this model to find event coref-
4.3 Cross-Modal Entity Coreference erence between image and text events. For the im-
The entity coreference pipeline aims to build ages with detected events, we apply our previous
a knowledge graph by linking detected entities grounding model to find sentences within the same
by our entity detection component. Our entity root document with high image-sentence similar-
coreference model has two components: single- ity, representing the sentence content similar to the
modality and cross-modality. The single-modality image content. Also, we find the event mention
component finds entities that co-occur in multi- in the sentence extracted by the text event extrac-
ple images within the same root document. The tion tool. We apply a rule-based approach to deter-
cross-modality component links the entity ex- mine if the image event and the event mention in
tracted from the text model to the entities in the the sentence have a coreference relation. (1) The
images. This year, the cross-modal coreference event type of the event mention in the sentence
model links entity-level information (object from has the same event type extracted in the image.(2) The image and sentence have a high similar- and TA2. Briefly speaking, HypoGator decom-
ity score. (3) No contradiction in the entity types poses a complex graph query into subqueries of
for the same argument role across different modal- simple subgraph patterns. For each subquery its
ities. If all three criteria are valid, we determine entry points are matched into the inferred input
that the two events from different modalities have knowledge graph and their local context gener-
a coreference relation. This pipeline allows us to ates candidate answers. Candidates are scored
find 36% of visual events contain additional argu- and ranked using multiple features that are indica-
ments not mentioned in the text, with 98 additional tive of coherence and relevance. A join algorithm
arguments detected. For the event detection per- combines the answers from each atomic query and
formance, visual events had a precision of 60%, re-scores the final set of answers using features
and visual events with coreference had a precision that encourage answer cohesion. Finally, a newly
of 82%. So the step of co-referencing with text developed hypotheses clustering algorithm is ap-
events serves as a useful filtering step to further plied to select out the alternative hypotheses based
enhance visual event detection accuracy. on both structural and semantic features. Figure 4.
Details of the core components are covered in the
5 TA2 Cross-Document Coreference following subsections.
Our TA2 focuses on generating high precision
6.1 Query Processing
clusters of entities across documents since the in-
coming data includes noisy extractions and has A statement of information need(SIN) is a sub-
missing information. For the named entity, each graph pattern with event/relation types and en-
entity contains limited labels and pre-linked ex- tities as nodes, event/relation argument roles as
ternal knowledge base identifiers with confidence. edges and a set of grounded entities known as
The simple but effective clustering algorithm maps entry points. We classify an SIN as simple if
all entities with identifiers to Wikidata and ini- each entry points is used as the argument of
tializes clusters with knowledge base identifiers. only one event/relation. In contrast, a complex
The labels of these clusters get enriched from SIN has entry points that are shared by multiple
Wikidata’s multilingual label, aliases and descrip- events/relations developing into a star-like struc-
tions. Each cluster then computes several trusted ture. HypoGator’s query processing module first
labels for attracting other entities without knowl- scan an SIN and decomposes a complex SIN into
edge base identifiers and these newly merged en- multiple simple SINs that we refer to as atomic.
tities must have compatible types with the cluster The decomposition algorithm first finds all con-
type. For the rest of the entities, they form single- nected components in the SIN and for each com-
ton clusters and get merged based on the similarity ponent, the algorithm visits the neighbors of its en-
of labels. Finally, a prototype is elected from all try points and traverse each of them until a differ-
entities within each cluster to represent the whole ent entry point or a terminal node is found. The
cluster based on its extraction confidence and label resulting subgraphs are added to the atomic query
prevalence in the cluster. To deal with the large in- list. Figure 5 shows an example SIN with entry
put triples in AIDA Interchangeable Format, we points Odessa (a.k.a. Odesa) and Trade Unions
uses KGTK 4 which is a flexible and low-resource House (a.k.a. Trade Unions Building) in the cen-
required python library for knowledge graph ma- ter and atomic queries derived from it using the
nipulation in TSV intermediate format. decomposition algorithm round it.
After query decomposition, HypoGator
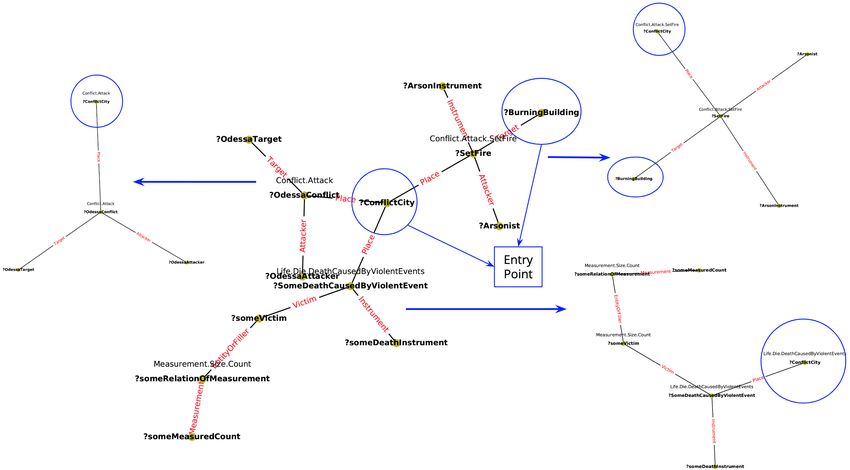
6 HypoGator: Alternative Hypotheses matches entry points into the inferred knowledge
Generation and Ranking graph. Since it is common to see that the informa-
HypoGator is the hypothesis Generation system tion of entities in the given KG are incomplete,
developed by the University of Florida. With a HypoGator will try to use all the available entry
search-rank-cluster approach, it finds alternative point information given by the SIN for matching
perspectives to complex topics(queries) over the separately, including the background KB id,
automatically extracted knowledge graph by TA1 the provenance offset and the strings of all the
names/alias of an entry point. When doing string
4
https://github.com/usc-isi-i2/kgtk matching, common string similarity metrics andFigure 4: HypoGator System Architecture
an adaptive threshold strategy are used. By any hypothesis and an overall boost in recall for
dropping the duplicated entity mention nodes, we other queries.
get the final seed entity set of the KG. with using single document lineage compared
with multi-document lineage on different datasets.
6.2 Query-driven Knowledge Graph The result is a trade off of completeness and coher-
inference ence: in M18 data single lineage generate more
Planned Objective: The goal is to enrich the TA2 coherent hypotheses, in M36 preliminary results,
KG in a targeted and computationally efficient single lineage generate very small and incom-
manner to support coherence of a generated hy- plete hypotheses. We experimented with docu-
pothesis. ment clustering to identify documents with sim-
Current Status: General inference approaches ilar perspectives - this generates negative results.
over larger knowledge graphs require heavy com- We also worked with GAIA TA1 team to extract
putational cost, this The cost is two-folds: 1) source of information at the document level and at
when performing inference over the whole KG, the event extraction level. Currently, we are able to
and 2) an after effect where the reset of the sys- leverage the lineage of the source to cluster docu-
tem needs to process the even larger KG+inferred ment, however, we are not able to leverage source
edges. Thus we propose using the query for tar- at the extraction level due to two reasons: 1) it
geted inference on only relevant subgraphs. We was not included in the M36 eval TA2; 2) it is not
experimented with both relation based and event- clear not to generate composite hypotheses using
role based inference. In relation based infer- lineage at extraction level in TA3 pipeline. We will
ence, we limit to the relations that appear in the look into these challenges when we have the data
query (statement of information need) and fil- ready from TA2.
ter candidate entities/fillers based on constraints
6.3 Candidate Hypothesis Generation
in the query, e.g., entity type, entity string, etc.
To enrich the TA2 KG with new relations, we HypoGator uses a novel two-level graph search
employ a simple entity-partitioning and relation- method to generate relevant atomic hypothesis for
scoring algorithm based on the character offsets an atomic query. Firstly, it explores the one-hop
and query constraints. To enrich event-role argu- neighborhood of the seed entities at the mention
ments, we filter TA1 subgraphs (documents) that level in the knowledge graph, searching for event
include the entry points and find missing roles for nodes which are coherent with the given event type
every event by cross-checking the ontology. Fi- in the corresponding atomic query. In the mean-
nally we use event-type based handcrafted features while, all the argument nodes around each visited
(e.g., char-offset, is-entry-point, is-same-type-as- coherent event node will also be included. Ev-
missing, string-similarity, etc.) to infer missing ery coherent event node and its argument nodes
roles. Initial results show a significant improve- including the seed entity serve as the backbone
ment in recall over queries that we couldn’t mine structure for a candidate atomic hypothesis. ThenFigure 5: Query Decomposition
based on those mention level event-centric sub- fidence. For example we use an ensemble of graph
graphs, we continue searching for coherent rela- distance functions to measure the query relevance
tions starting from each entity around the event or use a set of predefined logical rules to detect
at the cluster level. Figure 6 gives an example logical inconsistency. The overall score for each
of atomic hypothesis generated after the two-level hypothesis is computed as a linear combination
graph search and context enrichment which will of the individual scores from each of the features.
be introduced later. We use the LDC labeled data to learn appropriate
The entity cluster information provided by TA2 weights for each feature or use reasonable hand-
increases the connectivity of the mention level crafted weights for each feature.
graph extracted by the TA1, hence, it make us able While we have multiple features and each of
to find more coherent information through graph them scores the hypothesis for some important
searching. consistency or coherence property, we need a con-
dense score that can be used to give full quantita-
6.4 Ranking and Selection tive significance to a hypothesis and therefore use
Our candidate generation module ensures that the it for ranking candidates. We use a simple ap-
generated candidate hypothesis include the entry proach to aggregate different scores, a weighted
points. However, this does not guarantee them to sum of the feature values. We manually select the
be fully relevant to the query at hand. Moreover, weights with what we believe are more salient fea-
the candidates need to be pruned if they are not tures of a hypothesis. We look forward to include
logically or semantically coherent. Another im- a learned version of the weights.
portant factor determining the quality of a candi-
date hypothesis is the validity confidence of each 6.5 Hypotheses Clustering
of its knowledge elements, whether they are from Due to the nature of AIDA’s data e.g. multiple
the document sources (extraction confidence) or documents about the same hypothesis, it is possi-
inferred (inference confidence) or TA2 clustering. ble to generate many candidate hypotheses repre-
We use a variety of features to measure each hy- senting the same perspective with different level of
pothesis’s semantic coherence, logical coherence, details to a given SIN. Our system uses subgraph
and degree of relevance to the query. We use clustering to mining out the salient alternative per-
an aggregation method to obtain an overall con- spectives from the huge number of candidate hy-
fidence score from each knowledge elements con- potheses in which full of duplication and conflicts.Figure 6: Example Atomic Hypothesis: the triangles in the above graph refers to event/relation nodes, the circles
are entity nodes. All the purple and light blue nodes are mention level nodes, the grey circle is a entity cluster node
which refers to a bunch of entity mentions(of ’PER.Fan.SportsFan’ in this case) across multiple documents.
Table 1: Evaluation result of hypotheses clustering al- Acknowledgments
gorithms
This work was supported by the U.S. DARPA
M ETRICS /M OTHEDS OLD - M 18 GED- BASED (N EW )
AIDA Program No. FA8750-18-2-0014. The
H OMOGENEITY 0.725 0.916 (26.3(%))
C OMPLETENESS 0.729 0.847 (16.2(%)
views and conclusions contained in this docu-
V m easure 0.727 0.880 (21(%)) ment are those of the authors and should not be
SILHOUETTE 0.509 0.580 (14(%)) interpreted as representing the official policies,
F1( REPRESENTATIVES ) 0.6 0.75 (25(%))
either expressed or implied, of the U.S. Gov-
ernment. The U.S. Government is authorized
to reproduce and distribute reprints for Govern-
ment purposes notwithstanding any copyright no-
We designed and tested five new spectral clus- tation here on. We thank all the annotators who
tering based subgraph clustering algorithms with have contributed to the annotations of our train-
different similarity functions which is used to ing data for the joint IE component and key-
compute a similarity score for each pair of gener- word lists for rule-based component (in alphabet-
ated hypothesis subgraphs. To compare and eval- ical order): Daniel Campos, Yunmo Chen, An-
uate these different algorithms, we manually la- thony Cuff, Yi R. Fung, Xiaodan Hu, Emma Bon-
beled our own dataset using the subgraphs ex- nette Hamel, Samual Kriman, Meha Goyal Ku-
tracted from the LDC knowledge graph in which mar, Manling Li, Tongfei Chen, Tuan M. Lai, Ying
contains 54 automatically generated candidate hy- Lin, Chandler May, Sarah Moeller, Kenton Mur-
pothesis subgraphs and 20 manually labels clus- ray, Ashley Nobi, Xiaoman Pan, Nikolaus Paru-
ters. Among all these new developed methods, the lian, Adams Pollins, Kyle Rawlins, Rachel Ros-
customized graph edit distance(GED) based one set, Haoyu Wang, Qingyun Wang, Zhenhailong
performs the best. Table 1 shows the improve- Wang, Aaron Steven White, Spencer Whitehead,
ment of the new GED-based method comparing to Patrick Xia, Lucia Yao, Pengfei Yu, Qi Zeng, Hao-
the old sting-similarity based method. ran Zhang, Hongming Zhang, Zixuan Zhang.References 2019 Conference on Empirical Methods in Natu-
ral Language Processing and the 9th International
Emily Allaway and Kathleen McKeown. 2020. Zero- Joint Conference on Natural Language Processing
shot stance detection: A dataset and model using (EMNLP-IJCNLP), pages 5953–5959, Hong Kong,
generalized topic representations. arXiv preprint China. Association for Computational Linguistics.
arXiv:2010.03640.
Kenton Lee, Luheng He, Mike Lewis, and Luke Zettle-
Amith Ananthram, Emily Allaway, and Kathleen moyer. 2017. End-to-end neural coreference reso-
McKeown. 2020. Event guided denoising for lution. In Proceedings of the 2017 Conference on
multilingual relation learning. arXiv preprint Empirical Methods in Natural Language Process-
arXiv:2012.02721. ing, pages 188–197, Copenhagen, Denmark. Asso-
ciation for Computational Linguistics.
Alexis Conneau, Kartikay Khandelwal, Naman Goyal,
Vishrav Chaudhary, Guillaume Wenzek, Francisco Kenton Lee, Luheng He, and Luke Zettlemoyer. 2018.
Guzmán, Edouard Grave, Myle Ott, Luke Zettle- Higher-order coreference resolution with coarse-to-
moyer, and Veselin Stoyanov. 2019. Unsupervised fine inference. In Proceedings of the 2018 Confer-
cross-lingual representation learning at scale. arXiv ence of the North American Chapter of the Associ-
preprint arXiv:1911.02116. ation for Computational Linguistics: Human Lan-
guage Technologies, Volume 2 (Short Papers), pages
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, 687–692, New Orleans, Louisiana. Association for
Vishrav Chaudhary, Guillaume Wenzek, Francisco Computational Linguistics.
Guzmán, Edouard Grave, Myle Ott, Luke Zettle-
moyer, and Veselin Stoyanov. 2020. Unsupervised David D Lewis, Yiming Yang, Tony G Rose, and Fan
cross-lingual representation learning at scale. In Li. 2004. Rcv1: A new benchmark collection for
Proceedings of the 58th Annual Meeting of the Asso- text categorization research. Journal of machine
ciation for Computational Linguistics, pages 8440– learning research, 5(Apr):361–397.
8451, Online. Association for Computational Lin-
guistics. Mike Lewis, Yinhan Liu, Naman Goyal, Mar-
jan Ghazvininejad, Abdelrahman Mohamed, Omer
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Levy, Veselin Stoyanov, and Luke Zettlemoyer.
Kristina Toutanova. 2018. Bert: Pre-training of deep 2020. BART: Denoising sequence-to-sequence pre-
bidirectional transformers for language understand- training for natural language generation, translation,
ing. arXiv preprint arXiv:1810.04805. and comprehension. In Proceedings of the 58th An-
nual Meeting of the Association for Computational
Francisco Dias. 2016. Multilingual Automated Text Linguistics, pages 7871–7880, Online. Association
Anonymization. Msc dissertation, Instituto Superior for Computational Linguistics.
Técnico, Lisbon, Portugal, May.
Manling Li, Ying Lin, Ananya Subburathinam,
Zellig S Harris. 1954. Distributional structure. Word, Spencer Whitehead, Xiaoman Pan, Di Lu, Qingyun
10(2-3):146–162. Wang, Tongtao Zhang, L. Huang, Huai zhong Ji,
Alireza Zareian, H. Akbari, Brian. Chen, Bo Wu,
Heng Ji, Ralph Grishman, Dayne Freitag, Matthias Emily Allaway, Shih-Fu Chang, K. McKeown,
Blume, John Wang, Shahram Khadivi, Richard Y. Yao, J. Chen, Eric J Berquist, Kexuan Sun, Xujun
Zens, and Hermann Ney. 2009. Name extraction Peng, R. Gabbard, M. Freedman, Pedro A. Szekely,
and translation for distillation. Handbook of Natu- T. K. Kumar, Arka Sadhu, R. Nevatia, M. Ro-
ral Language Processing and Machine Translation: driguez, Yifan Wang, Yang Bai, A. Sadeghian, and
DARPA Global Autonomous Language Exploitation. D. Wang. 2019. Gaia at sm-kbp 2019-a multi-media
multi-lingual knowledge extraction and hypothesis
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, generation system.
Luke Zettlemoyer, and Omer Levy. 2020. Spanbert:
Improving pre-training by representing and predict- Ying Lin, Heng Ji, Fei Huang, and Lingfei Wu. 2020.
ing spans. Transactions of the Association for Com- A joint neural model for information extraction with
putational Linguistics, 8:64–77. global features. In Proceedings of the 58th Annual
Meeting of the Association for Computational Lin-
Mandar Joshi, Omer Levy, Luke Zettlemoyer, and guistics, pages 7999–8009, Online. Association for
Daniel Weld. 2019. BERT for coreference reso- Computational Linguistics.
lution: Baselines and analysis. In Proceedings of
the 2019 Conference on Empirical Methods in Nat- Ying Lin, Liyuan Liu, Heng Ji, Dong Yu, and Jiawei
ural Language Processing and the 9th International Han. 2019. Reliability-aware dynamic feature com-
Joint Conference on Natural Language Processing position for name tagging. In Proceedings of the
(EMNLP-IJCNLP), pages 5803–5808, Hong Kong, 57th Annual Meeting of the Association for Compu-
China. Association for Computational Linguistics. tational Linguistics, pages 165–174, Florence, Italy.
Association for Computational Linguistics.
Tuan Lai, Quan Hung Tran, Trung Bui, and Daisuke
Kihara. 2019. A gated self-attention memory net- Y. Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar
work for answer selection. In Proceedings of the Joshi, Danqi Chen, Omer Levy, M. Lewis, LukeZettlemoyer, and Veselin Stoyanov. 2019. Roberta: rich ere: annotation of entities, relations, and events.
A robustly optimized bert pretraining approach. In Proceedings of the the 3rd Workshop on EVENTS:
ArXiv, abs/1907.11692. Definition, Detection, Coreference, and Representa-
tion, pages 89–98.
Christopher Manning, Mihai Surdeanu, John Bauer,
Jenny Finkel, Steven Bethard, and David McClosky. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
2014. The Stanford CoreNLP natural language pro- Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz
cessing toolkit. In Proceedings of 52nd Annual Kaiser, and Illia Polosukhin. 2017. Attention is all
Meeting of the Association for Computational Lin- you need. arXiv preprint arXiv:1706.03762.
guistics: System Demonstrations, pages 55–60, Bal-
timore, Maryland. Association for Computational Petar Velickovic, Guillem Cucurull, Arantxa Casanova,
Linguistics. Adriana Romero, Pietro Liò, and Yoshua Bengio.
2018. Graph attention networks. In 6th Inter-
Teruko Mitamura, Zhengzhong Liu, and Eduard H. national Conference on Learning Representations,
Hovy. 2016. Overview of TAC-KBP 2016 event ICLR 2018, Vancouver, BC, Canada, April 30 - May
nugget track. In Proceedings of the 2016 Text Analy- 3, 2018, Conference Track Proceedings. OpenRe-
sis Conference, TAC 2016, Gaithersburg, Maryland, view.net.
USA, November 14-15, 2016. NIST.
Christopher Walker, Stephanie Strassel, Julie Medero,
Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, and Kazuaki Maeda. 2006. Ace 2005 multilin-
Olga Uryupina, and Yuchen Zhang. 2012. Conll- gual training corpus. Linguistic Data Consortium,
2012 shared task: Modeling multilingual unre- Philadelphia, 57.
stricted coreference in ontonotes. In Joint Con-
ference on Empirical Methods in Natural Lan- Liyan Xu and Jinho D. Choi. 2020. Revealing the
guage Processing and Computational Natural Lan- myth of higher-order inference in coreference reso-
guage Learning - Proceedings of the Shared Task: lution. In Proceedings of the 2020 Conference on
Modeling Multilingual Unrestricted Coreference in Empirical Methods in Natural Language Process-
OntoNotes, EMNLP-CoNLL 2012, July 13, 2012, ing (EMNLP), pages 8527–8533, Online. Associa-
Jeju Island, Korea, pages 1–40. ACL. tion for Computational Linguistics.
Sarah Pratt, Mark Yatskar, Luca Weihs, Ali Farhadi, Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, and
and Aniruddha Kembhavi. 2020. Grounded situa- Yu Qiao. 2016. Joint face detection and alignment
tion recognition. In European Conference on Com- using multitask cascaded convolutional networks.
puter Vision, pages 314–332. Springer. IEEE Signal Processing Letters, 23(10):1499–1503.
Tongtao Zhang, Ananya Subburathinam, Ge Shi, Lifu
Marta Recasens, Lluı́s Màrquez, Emili Sapena,
Huang, Di Lu, Xiaoman Pan, Manling Li, Boliang
M. Antònia Martı́, Mariona Taulé, Véronique
Zhang, Qingyun Wang, Spencer Whitehead, et al.
Hoste, Massimo Poesio, and Yannick Versley. 2010.
2018. Gaia-a multi-media multi-lingual knowl-
Semeval-2010 task 1: Coreference resolution in
edge extraction and hypothesis generation system.
multiple languages. In Proceedings of the 5th In-
In Proceedings of TAC KBP 2018, the 25th Inter-
ternational Workshop on Semantic Evaluation, Se-
national Conference on Computational Linguistics:
mEval@ACL 2010, Uppsala University, Uppsala,
Technical Papers.
Sweden, July 15-16, 2010, pages 1–8. The Associ-
ation for Computer Linguistics. Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude
Oliva, and Antonio Torralba. 2016. Learning deep
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian
features for discriminative localization. In Proceed-
Sun. 2015. Faster r-cnn: Towards real-time ob-
ings of the IEEE conference on computer vision and
ject detection with region proposal networks. In
pattern recognition, pages 2921–2929.
Advances in neural information processing systems,
pages 91–99.
Florian Schroff, Dmitry Kalenichenko, and James
Philbin. 2015. Facenet: A unified embedding for
face recognition and clustering. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 815–823.
Livio Baldini Soares, Nicholas FitzGerald, Jeffrey
Ling, and Tom Kwiatkowski. 2019. Matching the
blanks: Distributional similarity for relation learn-
ing. arXiv preprint arXiv:1906.03158.
Zhiyi Song, Ann Bies, Stephanie Strassel, Tom Riese,
Justin Mott, Joe Ellis, Jonathan Wright, Seth Kulick,
Neville Ryant, and Xiaoyi Ma. 2015. From light toYou can also read

















































