Alchemy: A structured task distribution for meta-reinforcement learning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Alchemy: A structured task distribution for
meta-reinforcement learning
Jane X. Wang* † 1 , Michael King* 1 , Nicolas Porcel1 , Zeb Kurth-Nelson1,2 ,
Tina Zhu1 , Charlie Deck1 , Peter Choy1 , Mary Cassin1 , Malcolm Reynolds1 ,
Francis Song1 , Gavin Buttimore1 , David P. Reichert1 , Neil Rabinowitz1 ,
Loic Matthey1 , Demis Hassabis1 , Alexander Lerchner1 , Matthew Botvinick‡1,2
arXiv:2102.02926v1 [cs.LG] 4 Feb 2021
1
DeepMind, London, UK
2
University College London, London, UK
February 8, 2021
Abstract et al., 2020) to realtime strategy (Vinyals et al., 2019; Ope-
There has been rapidly growing interest in meta- nAI, 2018) to first person 3D games (Jaderberg et al., 2019;
learning as a method for increasing the flexibil- Wydmuch et al., 2018). However, despite these successes,
ity and sample efficiency of reinforcement learn- poor sample efficiency, generalization, and transfer remain
ing. One problem in this area of research, how- widely acknowledged pitfalls. To address those challenges,
ever, has been a scarcity of adequate benchmark there has recently been growing interest in the topic of meta-
tasks. In general, the structure underlying past learning (Brown et al., 2020; Vanschoren, 2019), and how
benchmarks has either been too simple to be in- meta-learning abilities can be integrated into deep RL agents
herently interesting, or too ill-defined to support (Wang, 2020; Botvinick et al., 2019). Although a bevy of in-
principled analysis. In the present work, we in- teresting and innovative techniques for meta-reinforcement
troduce a new benchmark for meta-RL research, learning have been proposed (e.g., Finn et al., 2017; Xu et al.,
which combines structural richness with struc- 2018; Rakelly et al., 2019; Stadie et al., 2018), research in
tural transparency. Alchemy is a 3D video game, this area has been hindered by a ‘problem problem,’ that
implemented in Unity, which involves a latent is, a dearth of ideal task benchmarks. In the present work,
causal structure that is resampled procedurally we contribute toward a remedy, by introducing and pub-
from episode to episode, affording structure learn- licly releasing a new and principled benchmark for meta-RL
ing, online inference, hypothesis testing and ac- research.
tion sequencing based on abstract domain knowl-
Where deep RL requires a task, meta-RL instead requires
edge. We evaluate a pair of powerful RL agents
a task distribution, a large set of tasks with some form of
on Alchemy and present an in-depth analysis of
shared structure. Meta-RL is then defined as any process
one of these agents. Results clearly indicate a
that yields faster learning, on average, with each new draw
frank and specific failure of meta-learning, pro-
from the task distribution (Thrun & Pratt, 1998). A clas-
viding validation for Alchemy as a challenging
sic example, leveraged in numerous meta-RL studies (e.g.,
benchmark for meta-RL. Concurrent with this re-
Wang et al., 2016; Duan et al., 2016) is a distribution of
port, we are releasing Alchemy as public resource,
bandit problems, each with its own sampled set of action-
together with a suite of analysis tools and sample
contingent reward probabilities.
agent trajectories.
A straightforward way to generalize the problem setting
for meta-RL is in terms of an underspecified partially ob-
1. Introduction servable Markov decision problem (UPOMDP; Dennis
Techniques for deep reinforcement learning have matured et al., 2020). This enriches the standard POMDP tuple
rapidly over the last few years, yielding high levels of per- hS, A, Ω, T, R, Oi, respectively a set of states, actions, and
formance in tasks ranging from chess and Go (Schrittwieser observations, together with state-transition, reward and ob-
* Equal contribution servation functions (Sutton & Barto, 1998), adding a set of
†
Correspondence to: wangjane@google.com parameters Θ which govern the latter three functions. Im-
‡
Correspondence to: botvinick@google.com portantly, Θ is understood as a random variable, governed
1
by a prior distribution and resulting in a corresponding distri- and strategic action sequencing. Because Alchemy levels
bution of POMDPs. In this setting, meta-RL can be viewed are procedurally created based on a fully accessible gen-
in terms of hierarchical Bayesian inference, with a rela- erative process with a well-defined parameterization, we
tively slow process, spanning samples, gradually inferring are able to implement a Bayesian ideal observer as a gold
the structure of the parameterization Θ, and in turn sup- standard for performance.
porting a rapid process which infers the specific parameters
In addition to introducing the Alchemy environment, we
underlying each new draw from the task distribution (Ortega
evaluate it on two recently introduced, powerful deep RL
et al., 2019; Grant et al., 2018; Duff, 2003; Baxter, 1998). In
agents, demonstrating a striking failure of structure learning.
meta-RL, the latter process is an active one, involving strate-
Applying a battery of performance probes and analyses to
gic gathering of information or experimentation (Fedorov,
one agent, we provide evidence that its performance reflects
2013; Dasgupta et al., 2019).
a superficial, structure-blind heuristic strategy. Further ex-
This perspective brings into view two further desiderata periments show that this outcome is not purely due to the
for any benchmark meta-RL task distribution. First, the sensorimotor complexities of the task, nor to the demands
ground-truth parameterization of the distribution should of multi-step decision making. In sum, the limited meta-
ideally be accessible. This allows agent performance to learning performance appears to be specifically tied to the
be compared directly against an optimal baseline, which is identification of latent structure, validating the utility of
precisely a Bayesian learner, sometimes referred to as an Alchemy as an assay for this particular ability.
‘ideal observer’ (Geisler, 2003; Ortega et al., 2019). Second,
the structure of the task distribution should be interesting, in 2. The Alchemy environment
that it displays properties comparable to those involved in
Alchemy is a 3D environment created in Unity (Juliani et al.,
many challenging real-world tasks. Intuitively, in the limit,
2018; Ward et al., 2020), played in a series of ‘trials’, which
interesting structure should feature compositionality, causal
fit together into ‘episodes.’ Within each trial, the goal is to
relationships, and opportunities for conceptual abstraction
use a set of potions to transform each in a collection of visu-
(Lake et al., 2017), and result in tasks whose diagnosis and
ally distinctive stones into more valuable forms, collecting
solutions require strategic sequencing of actions.
points when the stones are dropped into a central cauldron.
Unfortunately, the environments employed in previous meta- The value of each stone is tied to its perceptual features, but
RL research have tended to satisfy one of the above desider- this relationship changes from episode to episode, as do the
ata at the expense of the other. Task distributions such as potions’ transformative effects. Together, these structural as-
bandit problems have furnished accessibility, allowing for pects of the task constitute a ‘chemistry’ that is fixed across
principled analysis and interpretation of meta-learning per- trials within an episode, but which is resampled at the start
formance (Wang et al., 2016; Duan et al., 2016; Ortega of each episode, based on a highly structured generative
et al., 2019), but have failed on the interestingness front by process (see Figure 1). The implicit challenge within each
focusing on very simple task parameterization structures. episode is thus to diagnose, within the available time, the
At the other end of the spectrum, tasks with more inter- current chemistry, leveraging this diagnosis to manufacture
esting and diverse structure (e.g., Atari games) have been the most valuable stones possible.
grouped together as task distributions, but the underlying
structure or parameterization of those distributions is not 2.1. Observations, actions, and task logic
transparent (Bellemare et al., 2013; Parisotto et al., 2015; At the beginning of each trial, the agent views a table con-
Rusu et al., 2016; Nichol et al., 2018; Cobbe et al., 2019; Yu taining a cauldron together with three stones and twelve
et al., 2020). This makes it difficult to be confident (beyond potions, as sampled from Alchemy’s generative process
human intuition) whether any sample from the task distri- (Figure 1a). Stone appearance varies along three feature
bution in fact supports transfer to further sampled tasks, let dimensions: size, color and shape. Each stone also displays
alone to construct Bayes-optimal performance baselines for a marker whose brightness signals its point value (-3, -1,
such transfer. +1 or +15). Each potion appears in one of six hues. The
In the present work, we introduce a task distribution that agent receives pixel-level (96x72 RGB) observations from
checks both boxes, offering both accessibility and inter- an egocentric perspective, together with proprioceptive in-
estingness, and thus a best-of-both-worlds benchmark for formation (acceleration, distance of and force on the hand,
meta-RL research. Alchemy is a 3D, first-person perspec- and whether the hand is grasping an object). It selects ac-
tive video game implemented in the Unity game engine tions from a nine-dimensional set (consisting of navigation,
(www.unity.com). It has a highly structured and non-trivial object manipulation actuators, and a discrete grab action).
latent causal structure which is resampled every time the When a stone comes into contact with a potion, the latter is
game is played, requiring knowledge-based experimentation completely consumed and, depending on the current chem-
istry, the stone appearance and value may change. Each trial
a) c)
Variables determining potion/stone mappings
between perceptual and latent space Placement
Potions
Graphs 12 Lighting
Stones
b) Chemistry
3
Resample stones, potions, etc.
NEpisode Ntrial
Trial 1 2 3 1 2 3
Constraint rules Reward rules Potion
Episode 1 Episode 2 color pairings
Resample chemistry Size
y e) Shape
Color
d) x
z
Figure 1. a) Visual observation for Alchemy, RGB, rendered at higher resolution than is received by the agent (96x72). b) Temporal
depiction of the generative process, indicating when chemistries and trial-specific instances (stones, potions, placement, lighting) are
resampled. c) A high-level depiction of the generative process for sampling a new task, in plate notation. Certain structures are fixed for
all episodes, such as the constraint rules governing the possible graphs, the way rewards are calculated from stone latent properties, and
the fact that potions are paired into opposites. Every episode, a graph and a set of variables determining the way potions and stones are
mapped between latent and perceptual space are sampled to form a new chemistry. Conditioned on this chemistry, for each of Ntrial = 10
trials, Ns = 3 specific stones and Np = 12 potions are sampled, as well as random position and lighting conditions, to form the perceptual
observation for the agent. See Appendix A.1 and Figure 5 for a detailed description of all elements. d) Four example chemistries, in
which the latent axes are held constant (worst stone is at the origin). e) The same four chemistries, this time with perceptual axes held
constant. Note that the edges of the causal graph need not be axis aligned with the perceptual axes.
lasts sixty seconds, simulated at 30 frames per second. A vi- tached to each appearance, and, crucially, the transformative
sual indicator in each corner of the workspace indicates time effects that potions have on stones. The specific chemistry
remaining. Each episode comprises ten trials, with the chem- for each episode is sampled from a structured generative
istry fixed across trials but stone and potion instances, spatial process, illustrated in Figure 1c-e and fully described in
positions, and lighting resampled at the onset of each trial the Appendix. For brevity, we limit ourselves here to a
(Figure 1b). See https://youtu.be/k2ziWeyMxAk high-level description.
for a video illustration of game play.
To foreground the meta-learning challenge involved in
Alchemy, it is useful to distinguish between (1) the aspects
2.2. The chemistry of the task that can change across episodes and (2) the ab-
As noted earlier, the causal structure of the task changes stract principles or regularities that span all episodes. As
across episodes. The current ‘chemistry’ determines the we have noted, the former, changeable aspects include stone
particular stone appearances that can occur, the value at-
appearances, stone values, and potion effects. Given all 2.3. Symbolic version
possible combinations of these factors, there exist a total As a complement to the canonical 3D version of Alchemy,
of 167,424 possible chemistries (taking into account that we have also created a symbolic version of the task. This in-
stone and potion instances are also sampled per trial yields volves the same underlying generative process and preserves
a total set of possible trial initializations on the order of 124 the challenge of reasoning and planning over the resulting
billion, still neglecting variability in the spatial positioning latent structure, but factors out the visuospatial and motor
of objects, lighting, etc).1 The principles that span episodes complexities of the full environment. Symbolic Alchemy
are, in a sense, more important, since identifying and ex- returns as observation a concatenated vector indicating the
ploiting these regularities is the essence of the meta-learning features of all sampled potions and stones, and entails a
problem. The invariances that characterize the generative discrete action space, specifying a stone and a container
process in Alchemy can be summarized as follows: (either potion or cauldron) in which to place it, plus a no-op
action. Full details are presented in the Appendix.
1. Within each episode, stones with the same visual fea-
tures have the same value and respond identically to
potions. Analogously, potions of the same color have 2.4. Ideal-observer reference agent
the same effects. As noted in the Introduction, when a task distribution is
fully accessible, this makes it possible to construct a Bayes-
2. Within each episode, only eight stone appearances can optimal ‘ideal observer’ benchmark agent as a gold standard
occur, and these correspond to the vertices of a cube for evaluating the meta-learning performance of any agent.
in the three-dimensional appearance space. Potion We constructed just such an agent for Alchemy, as detailed
effects run only along the edges of this cube, effectively in the Appendix (Algorithm 1). This agent maintains a
making it a causal graph. belief state over all possible chemistries given the history of
3. Each potion type (color) ‘moves’ stone appearances in observations, and performs an exhaustive search over both
only one direction in appearance space. That is, each available actions (as discretized in symbolic Alchemy) and
potion operates only along parallel edges of the cubic possible outcomes in order to maximize reward at the end
causal graph. of the current trial. The resulting policy both marks out the
highest attainable task score (in expectation) and exposes
4. Potions come in fixed pairs (red/green, yellow/orange, minimum-regret action sequences, which optimally balance
pink/turquoise) which always have opposite effects. exploration or experimentation against exploitation.3 Any
The effect of the red potion, for example, varies across agent matching the score of the ideal observer demonstrates,
episodes, but whatever its effects, the green potion will in doing so, both a thorough understanding of Alchemy’s
have the converse effects. task structure and strong action-sequencing abilities.
5. In some chemistries, edges of the causal graph may be As further tools for analysis, we devised two other reference
missing, i.e., no single potion will effect a transition agents. An oracle benchmark agent is always given privi-
between two particular stone appearances.2 However, leged access to a full description of the current chemistry,
the topology of the underlying causal graph is not ar- and performs a brute-force search over the available actions,
bitrary; it is governed by a generative grammar that seeking to maximizing reward (see Appendix, Algorithm 2).
yields a highly structured distribution of topologies A random heuristic benchmark agent chooses a stone at
(see Appendix A.1 and Figure 6). random, using potions at random until that stone reaches the
Because these conceptual aspects of the task remain in- maximum value of +15 points. It then deposits the stone into
variant across episodes, experience gathered from across a the cauldron, chooses a new stone and repeats (Appendix,
large set of episodes affords the opportunity for an agent to Algorithm 3). The resulting policy yields a score reflecting
discover them, tuning into the structure of the generative what is possible in the absence of any guiding understanding
process giving rise to each episode and trial. It is the ability of the latent structure of the Alchemy task.
to learn at this level, and to exploit what it learns, that corre- 3
Our ideal observer does not account for optimal inference over
sponds to an agent’s meta-learning performance. the entire length of the episode, which would be computationally
1
intractable to calculate. However, in general, we find that a single
Note that this corresponds to the sample space for the parame- trial is enough to narrow down the number of possible world states
ter set Θ mentioned in the Introduction. to a much smaller number, and thus searching for more than one
2
When this is the case, in order to anticipate the effect of trial does not confer significant benefits.
some potions the player must attend to conjunctions of perceptual
features. Missing edges can also create bottlenecks in the causal
graph, which make it necessary to first transform a stone to look
less similar to a goal appearance before it is feasible to attain that
goal state.
3. Experiments
Table 1. Benchmark and baseline-agent evaluation episode scores
3.1. Agent architectures and training (mean ± standard error over 1000 episodes).
As a first test of Alchemy’s utility as a meta-RL benchmark,
we tested two strong distributed deep RL agents. AGENT E PISODE SCORE
VMPO agent: As described in (Song et al., 2019) and IMPALA 140.2 ± 1.5
(Parisotto et al., 2019), this agent centered on a gated trans- VMPO 156.2 ± 1.6
former XL network. Image-frame observations were passed VMPO (S YMBOLIC ) 155.4 ± 1.6
through a residual-network encoder and fully connected I DEAL OBSERVER 284.4 ± 1.6
layer, with proprioceptive observations, previous action and O RACLE 288.5 ± 1.5
R ANDOM HEURISTIC 145.7 ± 1.5
reward then concatenated. In the symbolic task, observa-
tions were passed directly to the transformer core. Losses
were included for policy and value heads, pixel control
(Jaderberg et al., 2017b), kickstarting (Schmitt et al., 2018; tions, or to the challenge of sequencing actions in order to
Czarnecki et al., 2019) and latent state prediction (see Sec- capitalize on inferences concerning the task’s latent state. A
tion 3.3) weighted by βloss type . Where kickstarting was clear answer is provided by the scores from a VMPO agent
used (see below), the loss was KL(πstudent kπteacher ) and the trained and tested on the symbolic version of Alchemy,
weighting was set to 0 after 5e8 steps. Further details are which lifts both of these challenges while continuing to im-
presented in Appendix Table 2. pose the task’s more fundamental requirement for structure
learning and latent-state inference. As shown in Table 1,
IMPALA agent: This agent is described by (Espeholt et al., performance was no better in this setting than in the canon-
2018), and used population-based training as presented by ical version of the task, again only slightly surpassing the
(Jaderberg et al., 2017a). Pixel observations passed through score from the random heuristic policy.
a residual-network encoder and fully connected layer, and
proprioceptive observations were concatenated to the in- Informal inspection of trajectories from the symbolic ver-
put at every spatial location before each residual-network sion of the task was consistent with the conclusion that the
block. The resulting output was fed into the core of the agent, like the random heuristic policy, was dipping stones
network, an LSTM.4 Pixel control and kickstarting losses in potions essentially at random until a high point value
were used, as in the VMPO agent. See Appendix Table 3 happened to be attained. To test this impression more rigor-
for details. ously, we measured how many potions the agent consumed,
on average, during the first and last trials within an episode.
Both agents were trained for 2e10 steps (4̃.44e6 training As shown in Figure 3a, the agent used more potions dur-
episodes; 1e9 episodes for the symbolic version of the task), ing episode-initial trials than the ideal observer benchmark.
and evaluated without weight updates on 1000 test episodes. From Figure 3b, we can see that the ideal observer used a
Note that to surpass a zero score, both agents required kick- smaller number of potions in the episode-final trial than in
starting (Schmitt et al., 2018), with agents first trained on the initial trial, while the VMPO baseline agent showed no
a fixed chemistry with shaping rewards included for each such reduction (see Appendix Figure 9 for more detailed
potion use. Agents trained on the symbolic version of the results). By selecting diagnostic actions, the ideal observer
task were trained from scratch without kickstarting. progressively reduces its uncertainty over the current latent
state of the task (i.e., the set of chemistries possibly currently
3.2. Agent performance in effect, given the history of observations). This is shown
Mean episode scores for both agents are shown in Table 1. in Figure 3c-d, in units of posterior entropy, calculated as
Both fell far short of the gold-standard ideal observer bench- the log of the number of possible states. The VMPO agent’s
mark, implying a failure of meta-learning. In fact, scores for actions also effectively reveal the chemistry, as indicated
both agents fell close to that attained by the random heuristic in the figure. The fact that the agent is nonetheless scoring
reference policy. In order to better understand these results, poorly and overusing potions implies that it is failing to
we conducted a series of additional analyses, focusing on the make use of the information its actions have inadvertently
VMPO agent given its slightly higher baseline score. revealed about the task’s latent state.
A first question was whether this agent’s poor performance The behavior of the VMPO agent suggests that it has not
is due either to the difficulty of discerning task structure tuned into the consistent principles that span chemistries
through the complexity of high-dimensional pixel observa- in Alchemy, as enumerated in Section 2.2. One way of
4 probing the agent’s ‘understanding’ of individual principles
Recurrent state was set to zero at episode boundaries, but
not between trials, enabling the agents (in principle) to utilise
is to test how well its behavior is fit by synthetic models
knowledge of the chemistry accumulated over previous trials. that either do or do not leverage one relevant aspect of the
task’s structure, a technique frequently used in cognitive
a) No auxiliary tasks b) Auxiliary task Predict: Features
Input: None
Input: Belief state
Episode reward
Episode reward
Input: Ground truth
3D with symbolic 3D with symbolic
3D Symbolic 3D Symbolic
observations observations
Figure 2. Episode reward averaged over 1000 evaluation episodes, for VMPO agent, on 3D Alchemy, symbolic Alchemy, and 3D Alchemy
with additional symbolic observations, for a) no auxiliary tasks and b) feature prediction auxiliary tasks. The gray dashed line indicates
reward achieved by the ideal observer; the dotted line indicates that achieved by the random heuristic benchmark agent. Filled black
circles indicate individual replicas (5-8 per condition).
science to analyze human learning and decision making. what factors might be holding the agent back.
We applied this strategy to evaluate whether agents trained
Given the failure of the VMPO agent to show signs of identi-
on the symbolic version of Alchemy was leveraging the
fying the latent structure of the Alchemy task, one question
fact that potions come in consistent pairs with opposite ef-
of clear interest is whether the agent’s performance would
fects (see Section 2.2). Two models were devised, both
improve if the task’s latent state were rendered observable.
of which performed single-step look-ahead to predict the
In order to study this, we trained and tested on a version of
outcome (stones and potions remaining) for each currently
symbolic Alchemy which supplemented the agent’s obser-
available action, attaching to each outcome a value equal to
vations with a binary vector indicating the complete current
the sum of point-values for stones present, and selecting the
chemistry (see Appendix for details). When furnished with
subsequent action based on a soft-max over the resulting
this side information, the agent’s average score jumped dra-
state values. In both models, predictions were based on
matically, landing very near the score attained by the ideal
a posterior distribution over the current chemistry. How-
observer reference (Figure 2a ‘Symbolic’). Note that this
ever, in one model this posterior was updated in knowledge
augmentation gives the agent privileged access to an oracle-
of the potion pairings, while the other model ignored this
like indication of the current ground-truth chemistry. In a
regularity of the task. As shown in Figure 4, when the fit
less drastic augmentation, we replaced the side-information
of these two models was compared for the behavior of the
input with a vector indicating not the ground-truth chem-
ideal observer reference agent, in terms of relative likeli-
istry, but instead the set of chemistries consistent with ob-
hood, the result clearly indicated a superior fit for the model
servations made so far in the episode, corresponding to the
leveraging knowledge of the potion pairings. In contrast,
Bayesian belief state of the ideal observer reference model.
for the random heuristic reference agent, a much better fit
While the resulting scores in this setting were not quite as
was attained for the model operating in ignorance of the
high as those in the ground-truth augmentation experiment,
pairings. Applying the same analysis to the behavior of the
they were much higher than those observed without aug-
baseline VMPO agent yielded results mirroring those for the
mentation (Figure 2a ‘Symbolic’). Furthermore, the agent
random heuristic agent (see Figure 4), consistent with the
furnished with the belief state resembled the ideal observer
conclusion that the VMPO agent’s policy made no strategic
agent in showing a clear reduction in potion use between
use of the existence of consistent relationships between the
the first and last trials in an episode (Figure 3a-b).5 Model
potions’ effects.
fits also indicated the agent receiving this input made use of
the opposite-effects pairings of potions, an ability not seen
3.3. Augmentation studies
5
A standard strategy in reinforcement learning research is In contrast, when the agent was furnished with the full ground
to analyze the operation of a performant agent via a set of truth, it neither reduced its potion use over time nor so effectively
narrowed down the set of possible chemistries. This makes sense,
ablations, in order to determine what factors are causal in the
however, given that full knowledge of the current chemistry allows
agent’s success. Confronted with a poorly performing agent, the agent to be highly efficient in potion use from the start of the
we inverted this strategy, undertaking a set of augmentations episode, and relieves it from having to perform diagnostic actions
(additions to either the task or the agent) in order to identify to uncover the current latent state.
a) b) c) d)
Symbolic
Alchemy
Baseline
Input: Belief state
Input: Ground truth
Predict: Features
3D Alchemy
w/symbolic
observations
Figure 3. Behavioral metrics for different agents trained in symbolic alchemy (top) and 3D alchemy with symbolic observations (bottom).
a) Number of potions used in Trial 1. b) Difference between number of potions used in trial 10 vs trial 1. c) Posterior entropy over world
states, conditioned on agent actions, at end of trial 1. d) Posterior entropy over world states at the end of the episode. The gray dashed
line indicates the result of the Bayes ideal observer; the solid line indicates the result of the oracle benchmark. Filled black circles are
individual replicas.
in the baseline VMPO agent (Figure 4). random reference policy (Figure 2a ‘3D with symbolic ob-
servations’). However, adding either the ground-truth or
The impact of augmenting the input with an explicit rep-
belief-state input raised scores much more dramatically than
resentation of the chemistry implies that the VMPO agent,
when those inputs were included without symbolic state
while evidently unable to identify Alchemy’s latent struc-
information, elevating them to levels comparable to those
ture, can act adaptively if that latent structure is helpfully
attained in the symbolic task itself and approaching the ideal
brought to the surface. Since this observation was made in
observer model, with parallel effects on potion use (Figure
the setting of the symbolic version of Alchemy, we tested
3a-b). These results suggest that the failure of the agent to
the same question in the full 3D version of the task. Inter-
fully utilize side information about the current chemistry
estingly, the results here were somewhat different: While
was not due to challenges of action sequencing in the full 3D
appending a representation of either the ground-truth chem-
version of Alchemy, but stemmed instead from an inability
istry or belief state to the agent’s observations did increase
to effectively map such information onto internal represen-
scores, the effect was not as categorical as in the symbolic
tations of the current perceptual observation.
setting (Figure 2a ‘3D’). Two hypotheses suggest them-
selves as explanations for this result. First, the VMPO agent While augmenting the agent’s inputs is one way to impact its
might have more trouble capitalizing on the given side in- representation of current visual inputs, the recent deep RL
formation in the 3D version of Alchemy because doing so literature suggests a different method for enriching internal
requires composing much longer sequences of action than representations, which is to add auxiliary tasks to the agent’s
does the symbolic version of the task. Second, the greater training objective (see, e.g., Jaderberg et al., 2017b). As
complexity of the agent’s perceptual observations might one application of this idea, we added to the RL objective
make it harder to map the side information onto the struc- a set of supervised tasks, the objectives of which were to
ture of its current perceptual inputs. As one step toward produce outputs indicating (1) the total number of stones
adjudicating between these possibilities, we augmented the present in each of a set of perceptual categories, (2) the
inputs to the agent in the 3D task with the observations that total number of potions present of each color, and (3) the
the symbolic version of the task would provide in the same currently prevailing ground-truth chemistry (see Appendix
state. In the absence of side information about the currently B.1 for further details of this augmentation).6
prevailing chemistry, this augmentation did not change the 6
Prediction tasks (1) and (2) were always done in conjunction
agent’s behavior; the resulting score still fell close to the
and are collectively referred to as ‘Predict: Features’, while (3) is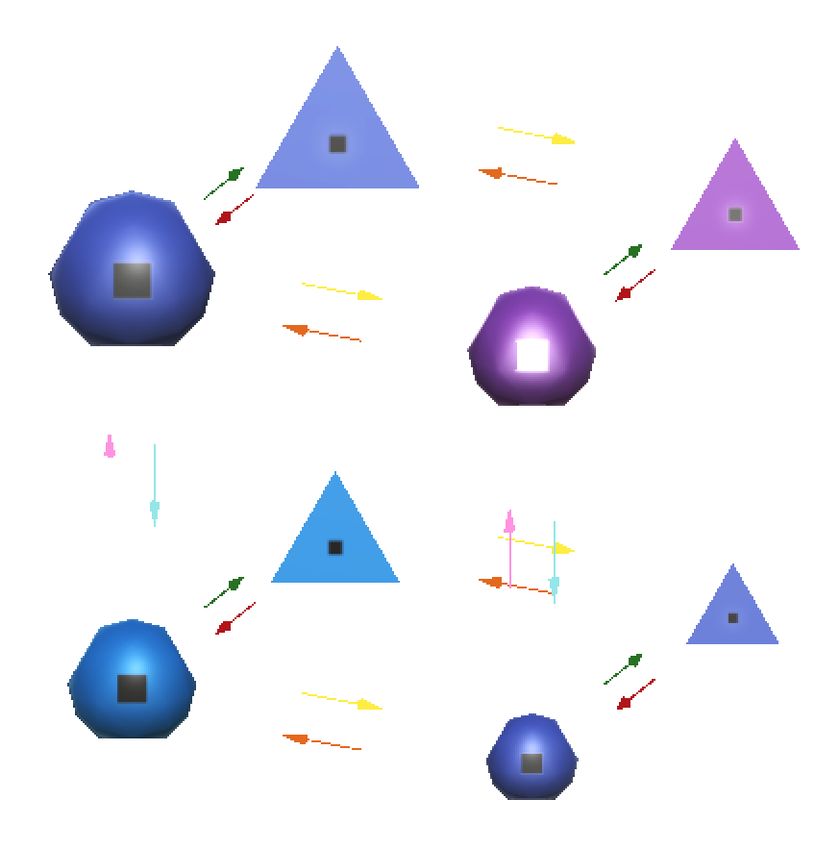
1.0 ing and latent-state inference, the core abilities at stake in
relative likelihood
meta-learning. In short, our first-step experiments provide
0.8 models
no potion pair
strong validation for Alchemy as a sensitive and specific
0.6 knowledge assay for meta-learning ability in RL.
0.4 potion pair
knowledge
0.2 4. Discussion
0.0 We have introduced Alchemy, a new benchmark task envi-
observer
baseline
heuristic
random
belief
state
ideal ronment for meta-RL research. Alchemy is novel among
existing benchmarks in bringing together two desirable fea-
tures: (1) structural interestingness, due to its abstract,
causal and compositional latent organization, which de-
Figure 4. Bayesian model comparison. Maximum likelihood was mands experimentation, structured inference and strategic
used to fit two probabilistic models to each agent or benchmark’s
action sequencing; and (2) structural accessibility, conferred
actions: (1) a model that does not assume potions come in pairs
by its explicitly defined generative process, which furnishes
with opposite effects (blue bars), and (2) a model that does make
this assumption (red bars). Comparing the goodness of fit between an interpretable prior and supports construction of a Bayes-
these models, we found that the baseline agent was better fit by optimal reference policy, alongside many other analytical
model (1), which does not know about potion pairs. Similarly, maneuvers. With the hope that Alchemy will be useful
the random heuristic benchmark was also better fit by this model. to the larger community, we are releasing, open-source,
Meanwhile, the agent which had as input the ideal observer’s belief both the full 3D and symbolic versions of the Alchemy
state, was better fit by model (2), and thus appeared to exploit the environment, along with a suite of benchmark policies, anal-
existence of potion pairs, in line with the ideal observer benchmark. ysis tools, and episode logs (https://github.com/
All agents were trained on symbolic Alchemy. deepmind/dm_alchemy).
Introducing these auxiliary tasks had a dramatic impact on As a first application and validation of Alchemy, we tested
agent performance, especially for (1) and (2) (less so for (3), two strong deep RL agents. In both cases, despite master-
see Appendix). This was true even in the absence of aug- ing the basic mechanical aspects of the task, neither agent
mentations of the agent’s observations, but it also yielded showed any appreciable signs of meta-learning. A series of
the highest scores observed so far in the full 3D version analyses, which were made possible by the task’s accessible
of Alchemy with input augmentations providing either the structure, clearly demonstrated a frank absence of struc-
ground-truth chemistry or Bayesian belief state (Figure 2b ture learning and latent-state inference. Whereas a Bayes-
‘3D’). Indeed, in the presence of the auxiliary tasks, fur- optimal reference agent pursued strategic experiments and
ther supplementing the inputs with the symbolic version leveraged the resulting observations to maximize its score,
of the perceptual observations added little to the agent’s deep RL resulted in a shallow, heuristic strategy, uninformed
performance (Figure 2b ‘3D with symbolic observations’). by the structure of the task distribution. Leveraging a sym-
Adding the auxiliary tasks to the objective for the VMPO bolic version of Alchemy, we were able to establish that
agent in symbolic Alchemy had a striking effect on scores this failure of meta-learning is not due purely to the visual
even in the absence of any other augmentation. In this case, complexity of the task or to the number of actions required
scores approached the ideal observer benchmark (Figure 2b to achieve task goals. Finally, a series of augmentation stud-
‘Symbolic’), providing the only case in the present study ies showed that deep RL agents can in fact perform well if
where the VMPO agent showed respectable meta-learning the latent structure of the task is rendered fully observable,
performance on either version of Alchemy without privi- especially if auxiliary tasks are introduced to support repre-
leged information at test.7 sentation learning. These insights may, we hope, be useful
in developing deep RL agents that are capable of solving
3.4. Conclusions from experiments Alchemy without access to privileged information.
This first set of agent experiments with Alchemy indicates
that the task is hard, and hard for the right reasons. We found It is worth stating that, in our view, the main contributions of
that two otherwise performant deep RL agents displayed lit- the present work inhere not in the specific concrete details of
tle evidence of meta-learning the latent structure of the task Alchemy itself, but rather in the overall scientific agenda and
despite extensive training. Rather than reflecting difficulties approach. Ascertaining the level of knowledge possessed
in perceptual processing or action sequencing, the agents’ by deep RL agents is a challenging task, comparable to
poor performance appears tied to a failure of structure learn- trying to ascertain the knowledge of real animals, and (as
in that latter case) requiring detailed cognitive modeling.
referred to as ‘Predict: Chemistry’. Alchemy is designed to make this kind of modeling not
7
Potion use in this setting, as well as world state uncertainty, only possible, but even central, and we propose that more
also showed a reduction over trials (see Figure 3).
meta-RL benchmark environments should strive to afford reinforcement learning. arXiv preprint arXiv:1901.08162,
the same granularity of insight into agent behavior. 2019.
As a closing remark, we note that our release of Alchemy in- Dennis, M., Jaques, N., Vinitsky, E., Bayen, A., Russell,
cludes a human-playable version. We have found that many S., Critch, A., and Levine, S. Emergent complexity and
human players find Alchemy interesting and challenging, zero-shot transfer via unsupervised environment design.
and our informal tests suggest that motivated players, with arXiv preprint arXiv:2012.02096, 2020.
sufficient training, can attain to sophisticated strategies and
high levels of performance. Based on this, we suggest that Duan, Y., Schulman, J., Chen, X., Bartlett, P. L., Sutskever,
Alchemy may also be an interesting task for research into I., and Abbeel, P. Rl$ˆ2$: Fast reinforcement learn-
human learning and decision making. ing via slow reinforcement learning. arXiv preprint
arXiv:1611.02779, 2016.
5. Acknowledgements Duff, M. O. Design for an optimal probe. In Proceedings of
We would like to thank the DeepMind Worlds team – in the 20th International Conference on Machine Learning
particular, Ricardo Barreira, Kieran Connell, Tom Ward, (ICML-03), pp. 131–138, 2003.
Manuel Sanchez, Mimi Jasarevic, and Jason Sanmiya for
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih,
help with releasing the environment and testing, and Sarah
V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning,
York for her help on testing and gathering human bench-
I., et al. Impala: Scalable distributed deep-rl with impor-
marks. We also are grateful to Sam Gershman, Murray
tance weighted actor-learner architectures. arXiv preprint
Shanahan, Irina Higgins, Christopher Summerfield, Jessica
arXiv:1802.01561, 2018.
Hamrick, David Raposo, Laurent Sartran, Razvan Pascanu,
Alex Cullum, and Victoria Langston for valuable discus- Fedorov, V. V. Theory of optimal experiments. Elsevier,
sions, feedback, and support. 2013.
Finn, C., Abbeel, P., and Levine, S. Model-agnostic meta-
References learning for fast adaptation of deep networks. arXiv
Baxter, J. Theoretical models of learning to learn. In Learn- preprint arXiv:1703.03400, 2017.
ing to learn, pp. 71–94. Springer, 1998. Geisler, W. S. Ideal observer analysis. The visual neuro-
Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. sciences, 10(7):12–12, 2003.
The arcade learning environment: An evaluation plat- Grant, E., Finn, C., Levine, S., Darrell, T., and Griffiths, T.
form for general agents. Journal of Artificial Intelligence Recasting gradient-based meta-learning as hierarchical
Research, 47:253–279, 2013. bayes. arXiv preprint arXiv:1801.08930, 2018.
Botvinick, M., Ritter, S., Wang, J. X., Kurth-Nelson, Z., Jaderberg, M., Dalibard, V., Osindero, S., Czarnecki, W. M.,
Blundell, C., and Hassabis, D. Reinforcement learning, Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning,
fast and slow. Trends in cognitive sciences, 23(5):408– I., Simonyan, K., Fernando, C., and Kavukcuoglu, K.
422, 2019. Population based training of neural networks, 2017a.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, Jaderberg, M., Mnih, V., Czarnecki, W. M., Schaul, T.,
J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Leibo, J. Z., Silver, D., and Kavukcuoglu, K. Rein-
Askell, A., et al. Language models are few-shot learners. forcement learning with unsupervised auxiliary tasks. In
arXiv preprint arXiv:2005.14165, 2020. International Conference on Learning Representations,
2017b.
Cobbe, K., Klimov, O., Hesse, C., Kim, T., and Schulman,
J. Quantifying generalization in reinforcement learning. Jaderberg, M., Czarnecki, W. M., Dunning, I., Marris, L.,
In International Conference on Machine Learning, pp. Lever, G., Castaneda, A. G., Beattie, C., Rabinowitz,
1282–1289. PMLR, 2019. N. C., Morcos, A. S., Ruderman, A., et al. Human-level
performance in 3d multiplayer games with population-
Czarnecki, W. M., Pascanu, R., Osindero, S., Jayakumar, based reinforcement learning. Science, 364(6443):859–
S. M., Swirszcz, G., and Jaderberg, M. Distilling policy 865, 2019.
distillation, 2019.
Juliani, A., Berges, V.-P., Vckay, E., Gao, Y., Henry, H.,
Dasgupta, I., Wang, J., Chiappa, S., Mitrovic, J., Ortega, Mattar, M., and Lange, D. Unity: A general platform
P., Raposo, D., Hughes, E., Battaglia, P., Botvinick, for intelligent agents. arXiv preprint arXiv:1809.02627,
M., and Kurth-Nelson, Z. Causal reasoning from meta- 2018.
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., and Gersh- Sutton, R. S. and Barto, A. G. Introduction to Reinforcement
man, S. J. Building machines that learn and think like Learning. MIT Press, 1998.
people. Behavioral and brain sciences, 40, 2017.
Thrun, S. and Pratt, L. Learning to learn. Springer Science
Nichol, A., Pfau, V., Hesse, C., Klimov, O., and Schulman, & Business Media, 1998.
J. Gotta learn fast: A new benchmark for generalization
Vanschoren, J. Meta-learning. In Automated Machine Learn-
in rl. arXiv preprint arXiv:1804.03720, 2018.
ing, pp. 35–61. Springer, Cham, 2019.
OpenAI. Openai five. https://blog.openai.com/ Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M.,
openai-five/, 2018. Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds,
Ortega, P. A., Wang, J. X., Rowland, M., Genewein, T., T., Georgiev, P., et al. Grandmaster level in starcraft ii
Kurth-Nelson, Z., Pascanu, R., Heess, N., Veness, J., using multi-agent reinforcement learning. Nature, 575
Pritzel, A., Sprechmann, P., et al. Meta-learning of se- (7782):350–354, 2019.
quential strategies. arXiv preprint arXiv:1905.03030, Wang, J. X. Meta-learning in natural and artificial intelli-
2019. gence. arXiv preprint arXiv:2011.13464, 2020.
Parisotto, E., Ba, J. L., and Salakhutdinov, R. Actor-mimic: Wang, J. X., Kurth-Nelson, Z., Tirumala, D., Soyer, H.,
Deep multitask and transfer reinforcement learning. arXiv Leibo, J. Z., Munos, R., Blundell, C., Kumaran, D., and
preprint arXiv:1511.06342, 2015. Botvinick, M. Learning to reinforcement learn. In Annual
Parisotto, E., Song, H. F., Rae, J. W., Pascanu, R., Gulcehre, Meeting of the Cognitive Science Society, 2016.
C., Jayakumar, S. M., Jaderberg, M., Kaufman, R. L., Ward, T., Bolt, A., Hemmings, N., Carter, S., Sanchez,
Clark, A., Noury, S., et al. Stabilizing transformers for M., Barreira, R., Noury, S., Anderson, K., Lemmon, J.,
reinforcement learning. In International Conference on Coe, J., Trochim, P., Handley, T., and Bolton, A. Using
Machine Learning, 2019. Unity to help solve intelligence, 2020. URL https:
//arxiv.org/abs/2011.09294.
Rakelly, K., Zhou, A., Finn, C., Levine, S., and Quillen, D.
Efficient off-policy meta-reinforcement learning via prob- Wydmuch, M., Kempka, M., and Jaśkowski, W. Vizdoom
abilistic context variables. In International conference on competitions: Playing doom from pixels. IEEE Transac-
machine learning, pp. 5331–5340. PMLR, 2019. tions on Games, 2018.
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Xu, Z., van Hasselt, H. P., and Silver, D. Meta-gradient
Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Had- reinforcement learning. Advances in neural information
sell, R. Progressive neural networks. arXiv preprint processing systems, 31:2396–2407, 2018.
arXiv:1606.04671, 2016.
Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn,
Schmitt, S., Hudson, J. J., Zidek, A., Osindero, S., Doersch, C., and Levine, S. Meta-world: A benchmark and evalua-
C., Czarnecki, W. M., Leibo, J. Z., Kuttler, H., Zisserman, tion for multi-task and meta reinforcement learning. In
A., Simonyan, K., et al. Kickstarting deep reinforcement Conference on Robot Learning, pp. 1094–1100. PMLR,
learning. arXiv preprint arXiv:1803.03835, 2018. 2020.
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K.,
Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis,
D., Graepel, T., et al. Mastering atari, go, chess and shogi
by planning with a learned model. Nature, 588(7839):
604–609, 2020.
Song, H. F., Abdolmaleki, A., Springenberg, J. T., Clark, A.,
Soyer, H., Rae, J. W., Noury, S., Ahuja, A., Liu, S., Tiru-
mala, D., et al. V-mpo: on-policy maximum a posteriori
policy optimization for discrete and continuous control.
In International Conference on Learning Representations,
2019.
Stadie, B. C., Yang, G., Houthooft, R., Chen, X., Duan, Y.,
Wu, Y., Abbeel, P., and Sutskever, I. Some considerations
on learning to explore via meta-reinforcement learning.
arXiv preprint arXiv:1803.01118, 2018.A. Alchemy mechanics table to find the color. We call this linear mapping the potion
A.1. The chemistry map P : P → P.
We consider three perceptual features along which stones
can vary: size, color, and shape. Potions are able to change
P (p) = Preflect Ppermute p (4)
stone perceptual features, but how a specific potion can af-
fect a particular stone’s appearance is determined by the
stone’s (unobserved) latent state c. Each potion determin- where Preflect is drawn from the same distribution as Sreflect
istically transforms stones according to a hidden, underly- and Ppermute is a 3x3 permutation matrix i.e. a matrix of
ing transition graph sampled from the set of all connected the form [e(π(0)) , e(π(1)) , e(π(2)) ]T , π ∼ U (Sym({0, 1, 2}))
graphs formed by the edges of a cube (see Figure 6a). The where Sym({0, 1, 2}) is the set of permutations of
corners of the cube represent different latent states, defined {0, 1, 2}.
by a 3-dimensional coordinate c ∈ {−1, 1}3 . Potion effects The directly observable potion colors are then assigned ac-
align with one axis and direction of the cube, such that one cording to:
of the coordinates c is modified from -1 to 1 or 1 to -1. In
equations:
(0) (0)
(e , −e ) → (green, red)
Pcolor = (e(1) , −e(1) ) → (yellow, orange) (5)
c = c + 2p1(c,c+2p)∈G (c) (1)
(2)
(e , −e(2) ) → (turquoise, pink)
where p ∈ P is the potion effect P :=
{e(0) , e(1) , e(2) , −e(0) , −e(1) , −e(2) } where e(i) is the Note that this implies that potion colors come in pairs so that,
ith basis vector and G is the set of edges which can be for example, the red potion always has the opposite effect to
traversed in the graph. the green potion, though that effect may be on color, size, or
shape, depending on the particular chemistry of that episode.
The latent state of the stone also determines its reward It can also have an effect on two of those three perceptual
value R ∈ {−3, −1, 1, 15}, which can be observed via features simultaneously in the case where Srotate 6= I3 . This
the brightness of the reward indicator (square light) on the color pairing of potions is consistent across all samples of
stone: the task, constituting a feature of Alchemy which can be
meta-learned over many episodes. Importantly, due to the
( P potion map P , the potion effects p in each episode must be
15, if i ci = 3
R(c) = P (2) discovered by experimentation.
i ci , else.
G is determined by sampling a graph topology (Figure 6d),
which determines which potion effects are possible. Potions
The agent only receives a reward for a stone if that stone is
only have effects if certain preconditions on the stone latent
successfully placed within the cauldron by the end of the
state are met, which constitute ‘bottlenecks’ (darker edges
trial, which removes the stone from the game.
in Figure 6d). Each graph consists of the edges of the
The latent coordinates c are mapped into the stone percep- cube which meet the graph’s set of preconditions. Each
tual feature space to determine the appearance of the stone. precondition says that an edge parallel to axis i exists only
We call this linear mapping the stone map or S and define it if its value on axis j is a where j 6= i and a ∈ {−1, 1}. The
as S : {−1, 1}3 → {−1, 0, 1}3 : more preconditions, the fewer edges the graph has.
Only sets of preconditions which generate a connected graph
S(c) = Srotate Sreflect c (3) are allowed. We denote the set of connected graphs with
preconditions of this form G. Note that this is smaller than
where Srotate denotes possible rotation around the set of all connected graphs, as a single precondition can
1 axis and rescaling. Formally: Srotate ∼ rule out 1 or 2 edges of the cube. As with the potion color
U ({I3 , Rx (45◦ ), Ry (45◦ ), Rz (45◦ )}), where I is the pairs, this structure is consistent across all samples and may
identity matrix, and Ri (θ) denotes an anti-clockwise be meta-learned.
rotation transform
√
around axis i by θ = 45◦ , followed by
2 We find that the maximum number of preconditions for any
scaling by 2 on all other axes, in order to normalize values
graph G ∈ G is 3. We define Gn := {G ∈ G|N (G) = n}
to be in {−1, 0, 1}. Sreflect denotes reflection in the x, y and
where N (G) is the number of preconditions in G. The
z axes: Sreflect = diag(s) for s ∼ U ({−1, 1}3 ).
sampling distribution is n ∼ U (0, 3), G ∼ U (Gn ). Of
The potion effect p is mapped to a potion color by first course, there is only one graph with 0 preconditions and
applying a linear mapping and then using a fixed look-up many graphs with 1, 2, or 3 preconditions so the graph with0 preconditions is the most common and is sampled 25% of B. Training and hyperparameters
the time.
A ‘chemistry’ is a random sampling of all variables {G, Table 2. Architecture and hyperparameters for VMPO.
Ppermute , Preflect , Sreflect , Srotate } (subject to the constraint
rules described above), which is held constant for an episode S ETTING VALUE
(Figure 5). Given all of the possible permutations, we cal- I MAGE RESOLUTION : 96 X 72 X 3
culate that there are 167,424 total chemistries that can be N UMBER OF ACTION REPEATS : 4
AGENT DISCOUNT: 0.99
sampled.
R ES N ET NUM CHANNELS : 64, 128, 128
T R XL MLP SIZE : 256
T R XL N UMBER OF LAYERS : 6
Ppermute Preflect Sreflect Srotate T R XL N UMBER OF HEADS : 8
Placement
Potions
T R XL K EY /VALUE SIZE : 32
η : 0.5
α : 0.001
G
12 Lighting TTARGET : 100
βπ : 1.0
Stones βV : 1.0
βPIXEL CONTROL : 0.001
βKICKSTARTING : 10.0
3
Chemistry βSTONE : 2.4
NEpisode Ntrial
βPOTION : 0.6
βCHEMISTRY : 10.0
Constraint rules R(c) Pcolor
Table 3. Architecture and hyperparameters for Impala.
Figure 5. The generative process for sampling a new task, in plate
notation. Constraint rules G, Pcolor , and R(c) are fixed for all
episodes (see Section A.1). Every episode, a set {G, Ppermute , S ETTING VALUE
Preflect , Sreflect , Srotate } is sampled to form a new chemistry. Condi- I MAGE RESOLUTION : 96 X 72 X 3
tioned on this chemistry, for each of Ntrial = 10 trials, Ns = 3 N UMBER OF ACTION REPEATS : 4
stones and Np = 12 potions are sampled, as well as random place- AGENT DISCOUNT: 0.99
ment and lighting conditions, to form the perceptual observation L EARNING RATE : 0.00033
for the agent. For clarity, the above visualization omits parameters R ES N ET NUM CHANNELS : 16, 32, 32
LSTM HIDDEN UNITS : 256
for normal or uniform distributions over variables (such as lighting
βπ : 1.0
and placement of stones/potions on the table). βV : 0.5
βENTROPY : 0.001
βPIXEL CONTROL : 0.2
βKICKSTARTING : 8.0Figure 6. a) Depiction of an example chemistry sampled from Alchemy, in which the perceptual features happen to be axis-aligned
with the latent feature coordinates (listed beside the stones). Stones transform according to a hidden transition structure, with edges
corresponding to the application of corresponding potions, as seen in b). c) For example, applying the green potion to the large purple
stone transforms it into a large blue stone, and also increases its value (indicated by the square in center of stone becoming white). d) The
possible graph topologies for stone transformation. Darker edges indicate ‘bottlenecks’, which are transitions that are only possible from
certain stone latent states. In topologies with bottlenecks, more potions are often required to reach the highest value stone. If the criteria
for stone states are not met, then the potion will have no effect (e.g. if topology (v) has been sampled, the yellow potion in the example
given in (a) will have no effect on the small purple round stone). Note that we can apply reflections and rotations on these topologies,
yielding a total of 109 configurations.
Algorithm 1 Ideal Observer Algorithm 2 Oracle
Input: stones s, potions p, belief state b Input: stones s, potions p, chemistry c
Initialise rewards = {} Initialise rewards = {}
for all si ∈ s do for all si ∈ s do
for all pj ∈ p do for all pj ∈ p do
sposs , pposs , bposs , bprobs = simulate use s0 , p0 = simulate use potion(s, p, si , pj , c)
potion(s, p, si , pj , b) rewards[si , pj ] = Oracle(s0 , p0 , c)
r=0 end for
for all s0 , p0 , b0 , prob ∈ sposs , pposs , bposs , bprobs do s0 , r = simulate use cauldron(s, si )
r = r + prob * Ideal Observer(s0 , p0 , b0 ) rewards[si , cauldron] = r + Oracle(s0 , p, c)
end for end for
rewards[si , pj ] = r return argmax(rewards)
end for
s0 , r = simulate use cauldron(s, si )
rewards[si , cauldron] = r + Ideal Observer(s0 , p, b) number of potions of each color, or 3) predicting the ground
end for truth chemistry. Auxiliary tasks contribute additional losses
return argmax(rewards) which are summed with the standard RL losses, weighted by
coefficients (βstone = 2.4, βpotion = 0.6, βchem = 10.0).
These hyperparameters were determined by roughly bal-
B.1. Auxiliary task losses ancing the gradient norms of variables which contributed
Auxiliary prediction tasks include: 1) predicting the number to all losses. All prediction tasks use an MLP head, (1)
of stones currently present that possess each possible percep- and (2) use an L2 regression loss while (3) uses a cross
tual feature (e.g. small size, blue color etc), 2) predicting the entropy loss. Prediction tasks (1) and (2) were always doneAlgorithm 3 Random heuristic C. Additional results
Input: stones s, potions p, threshold t Training curves show that VMPO agents train faster in the
si = random choice(s) symbolic version of Alchemy vs the 3D version (Figures 7
if reward(si ) > t or (reward(si ) > 0 and empty(p)) then and 8), even though agents are kickstarted in 3D.
return si , cauldron As seen in Figure 8, the auxiliary task of predicting features
end if appears much more beneficial than predicting the ground
pi = random choice(p) truth chemistry, the latter leading to slower training and
return si , pi more variability across seeds. We hypothesize that this
is because predicting the underlying chemistry is possibly
as difficult as simply performing well on the task, while
in conjunction and are collectively referred to as ‘Predict: predicting simple feature statistics is tractable, useful, and
Features’, while (3) is referred to as ‘Predict: Chemistry’ in leads to more generalizable knowledge.
the results.
The MLP for 1) has 128x128x13 units where the final layer
represents 3 predictions for each perceptual feature value e.g.
the number of small stones, medium stones, large stones and
4 predictions for the brightness of the reward indicator. The
MLP for 2) has 128x128x6 units where the final layer repre-
sents 1 prediction for the number of potions of each possible
color. 3) is predicted with an MLP with a sigmoid cross
entropy loss and has size 256x128x28 where the final layer
represents predictions of the symbolic representations of
the graph and mappings (Srotate , Sreflect , Preflect , Ppermute , G).
More precisely, Srotate is represented by a 4 dimensional
1-hot, Sreflect and Preflect are represented by 3 dimensional
vectors with a 1 in the ith element denoting reflection in axis
i, Ppermute is represented by a 6 dimensional 1-hot and G is
represented by a 12-dimensional vector for the 12 edges of
the cube with a 1 if the corresponding edge exists and a 0
otherwise.You can also read

















































