A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
A Benchmark for Generalizable and Interpretable Temporal Question
Answering over Knowledge Bases
Sumit Neelam, Udit Sharma, Hima Karanam, Shajith Ikbal, Pavan Kapanipathi
Ibrahim Abdelaziz, Nandana Mihindukulasooriya, Young-Suk Lee, Santosh Srivastava
Cezar Pendus, Saswati Dana, Dinesh Garg, Achille Fokoue, G P Shrivatsa Bhargav
Dinesh Khandelwal, Srinivas Ravishankar, Sairam Gurajada, Maria Chang,
Rosario Uceda-Sosa, Salim Roukos, Alexander Gray, Guilherme Lima
Ryan Riegel, Francois Luus, L Venkata Subramaniam
IBM Research
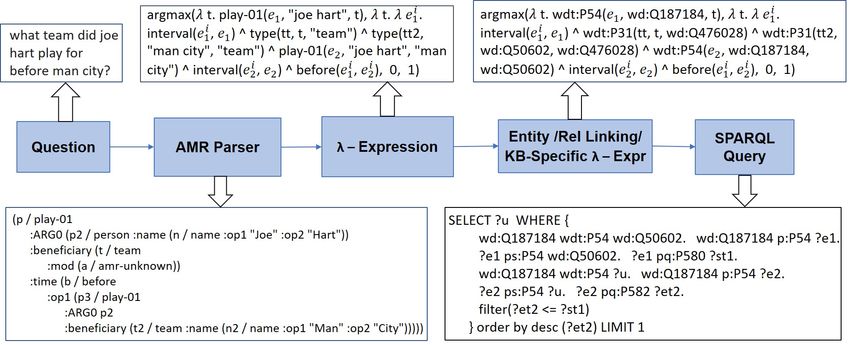
Abstract to answer the question What team did Joe Hart play
for before Man City?, the system must retrieve or
Knowledge Base Question Answering infer when Joe Hart played for Man City, when Joe
(KBQA) tasks that involve complex reason-
Hart played for other teams, and which of the latter
ing are emerging as an important research
arXiv:2201.05793v1 [cs.CL] 15 Jan 2022
direction. However, most existing KBQA intervals occurred before the former.
datasets focus primarily on generic multi-hop
reasoning over explicit facts, largely ignoring Category Example
other reasoning types such as temporal, Who directed Titanic Movie?
spatial, and taxonomic reasoning. In this Single-Hop SPARQL: select distinct ?a where {
paper, we present a benchmark dataset wd:Q44578 wdt:P57 ?a}
for temporal reasoning, TempQA-WD, to Which movie is directed by James Cameron
encourage research in extending the present starring Leonardo DiCaprio?
Multi-hop SPARQL: select distinct ?a where {
approaches to target a more challenging set ?a wdt:P57 wd:Q42574.
of complex reasoning tasks. Specifically, our ?a wdt:P161 wd:Q38111. }
benchmark is a temporal question answer- What team did joe hart play for before man city?
ing dataset with the following advantages: SPARQL: select distinct ?u where {
(a) it is based on Wikidata, which is the wd:Q187184 p:P54 ?e1. ?e1 ps:P54 wd:Q50602.
Temporal wd:Q187184 p:P54 ?e2. ?e2 ps:P54 ?u.
most frequently curated, openly available ?e1 pq:P580 ?st1. ?e2 pq:P582 ?et2.
knowledge base, (b) it includes intermediate filter (?et2and was officially discontinued in 2014 (Freebase). and DBpedia (Azmy et al., 2018) based versions
Our aim in this paper is to fill the above men- of SimpleQuestions, as well as the Wikidata subset
tioned gaps by adapting the TempQuestions dataset of WebQSP (Sorokin and Gurevych, 2018); (b)
to Wikidata and by enhancing it with additional reasoning types that are emphasized in the dataset;
SPARQL query annotations. Having SPARQL (c) availability of SPARQL queries, entities, and
queries for temporal dataset is crucial to refresh relationships for intermediate evaluation; and (d)
ground truth answers as the KB evolves. We choose the use of question templates, which can often gen-
Wikidata for this dataset because it is well struc- erate noisy, unnatural questions. As Table 2 shows,
tured, fast evolving, and the most up-to-date KB, our dataset is distinguished from prior work in its
making it a suitable candidate for temporal KBQA. emphasis on temporal reasoning, its application to
Our resulting dataset thus contains parallel annota- both Freebase and Wikidata, and its annotation of
tions (on both Wikidata and Freebase). This will intermediate representations and SPARQL queries.
help drive research towards development of gener- The most relevant KBQA dataset to our work is
alizable approaches, i.e., those that could be easily TempQuestions (Jia et al., 2018a), upon which we
be adaptable to multiple KBs. In order to encour- base TempQA-WD, as described in Section 3. Cron-
age development of interpretable, semantic parsing- Questions (Saxena et al., 2021) is another dataset
based approaches, we (1) annotate the questions where emphasis is on temporal reasoning. How-
with SPARQL queries and answers over Wikidata, ever, this dataset also provides a custom KB derived
and (2) annotate a subset of this dataset with inter- from Wikidata which acts as a source of truth for
mediate representations for the entities, relations, answering the questions provided as part of the
λ-expression along with SPARQL needed to an- dataset.
swer the question.
The main contributions of this work are as fol- 3 Dataset
lows:
TempQuestions (Jia et al., 2018a) was the first
• A benchmark dataset, called TempQA-WD, KBQA dataset intended to focus specifically on
for building temporal-aware KBQA systems temporal reasoning. It consists of temporal ques-
on Wikidata with parallel annotations on Free- tions from three different KBQA datasets with
base, thus encouraging the development of answers from Freebase: Free917 (Cai and Yates,
approaches for temporal KBQA that general- 2013), WebQuestions (Berant et al., 2013) and Com-
ize across KBs. plexQuestions (Bao et al., 2016). We adapt Tem-
pQuestions to Wikidata to create a temporal QA
• SPARQL queries for all questions in our dataset that has three desirable properties. First,
benchmark, with a subset of the data also an- in identifying answers in Wikidata, we create a
notated with expected outputs from intermedi- generalizable benchmark that has parallel annota-
ate stages of the question answering process, tions on two KBs. Second, we take advantage of
i.e. entity and relation linking gold outputs. Wikidata’s evolving, up-to-date knowledge. Lastly,
The goal here is to encourage interpretable we enhance TempQuestions with SPARQL, entity,
approaches that can generate intermediate out- and relation annotations so that we may evaluate
puts matching those fine-grained annotations. intermediate outputs of KBQA systems.
Two previous attempts at transferring
2 Related Work
Freebase-QA questions to Wikidata are
Over the years, many question answering datasets WebQSP-WD (Sorokin and Gurevych, 2018) and
have been developed for KBQA, such as SimpleQuestions-WD(SWQ-WD) (Diefenbach
Free917 (Cai and Yates, 2013), SimpleQues- et al., 2017a). SWQ-WD is single triple questions
tions (Bordes et al., 2015b), WebQuestions (Berant and in WebQSP-WD only answers are directly
et al., 2013), QALD-9 (Usbeck et al., 2017), LC- mapped to corresponding entities in Wikidata.
QuAD 1.0 (Trivedi et al., 2017), and LC-QuAD However, as stated (Sorokin and Gurevych, 2018),
2.0 (Dubey et al., 2019). In Table 2, we compare one challenge is that not all Freebase answers can
each of these datasets across the following features: be directly mapped to entities in Wikidata. For
(a) underlying KB, including subsequent exten- example, the Freebase answer annotation for the
sions, e.g. Wikidata (Diefenbach et al., 2017b) question "When did Moscow burn?" is “1812 FireDatasets Knowledge Base Emphasis SPARQL Intermediate Templates
Evaluation
QALD-9 DBpedia Multi-hop 3 3 7
LC-QuAD 1.0 DBpedia Multi-hop 3 3 3
LC-QuAD 2 DBpedia, Wikidata Multi-hop 3 3 3
Simple Questions Freebase, DBpedia, Wikidata Single-hop 3 3 7
Web Questions Freebase Multi-hop 7 7 7
Web Question-SP Freebase, Wikidata Multi-hop 3 3 7
Complex Web Questions Freebase Multi-hop 7 7 7
TempQuestions Freebase Temporal 7 7 7
CronQuestions Wikidata subset Temporal 7 7 3
TimeQuestions Wikidata Temporal 7 7 7
TempQA-WD Freebase, Wikidata Temporal 3 3 7
Table 2: This table compares most of the KBQA datasets based on features relevant to the work presented in this
paper. References: QALD-9 (Usbeck et al., 2017), LC-QuAD 1.0 (Trivedi et al., 2017), LC-QuAD 2.0 (Dubey
et al., 2019), Simple Questions (Bordes et al., 2015b), Web Questions (Berant et al., 2013), Web Questions-SP (Cai
and Yates, 2013), Complex Web Questions (Talmor and Berant, 2018), TempQuestions (Jia et al., 2018a)
wd:Q187184 wd:Q50602
of Mosco”, despite the year being entangled with (Joe Hart ) (Manchester City F.C.)
the event itself. In contrast, Wikidata explicitly wdt:P54 (member of sports team)
represents the year of this event, with an entity
p:P54 ps:P54
for “Fire in Moscow” and an associated year of
“1812". Thus, a direct mapping between the two
pq:P1350 pq:P1351
answers is not possible, as it would amount to a pq:P580 pq:P582 (number of (number
(start time) (end time) matches played) of points)
false equivalence between “1812 Fire of Mosco”
and “1812”.
In order to address such issues, we enlisted a 2006 August 2018 266 0
team of annotators to manually create and ver-
ify SPARQL queries, ensuring not only that the Figure 1: An illustration of Wikidata Reification.
SPARQL formulation was correct, but that the an-
swers accurately reflected the required answer type
supports reification of statements (triples) to add
(as in the “Fire in Moscow” example above) and the
additional metadata with qualifiers such as start
evolving knowledge in Wikidata (as the Freebase
date, end date, point in time, location etc. Figure 1
answers from the original dataset may be outdated).
shows an example of reified temporal information
Having SPARQL queries also facilitates intermedi-
assocaited to entities Joe Hart and Manchester City.
ate evaluation of the approaches that use semantic
With such representation and the availability of
parsing to directly generate the query or the query
up-to-date information, Wikidata makes it a good
graph, increasing interpretability and performance
choice to build benchmark datasets to test different
in some cases (Sorokin and Gurevych, 2018).
kinds of reasoning including temporal reasoning.
Next, we give a brief overview of how Wikidata
is organized, as some of its representational con- 3.2 Dataset Details
ventions impact our dataset creation process.
Table 3 gives details of our new benchmark dataset.
3.1 Wikidata We took all the questions from TempQuestions
dataset (of size 1271) and chose a subset for which
Wikidata1 is a free knowledge base that is actively
we could find Wikidata answers. This subset
updated and maintained. It has 93.65 million data
has 839 questions that constitute our new dataset,
items as of May, 2021 and continuously growing
TempQA-WD. We annotated this set with their cor-
each day with permission for volunteers to edit and
responding Wikidata SPARQL queries and the de-
add new data items. We chose Wikidata as our
rived answers. We also retained the Freebase an-
knowledge base as it has many temporal facts with
swers from the original TempQuestions dataset ef-
appropriate knowledge representation encoded. It
fectively creating parallel answers from two dis-
1
https://www.wikidata.org/ tinct KBs. Additionally, we added question com-Figure 2: Additional annotations example
Dataset Size Answer Add’l gathering large amount of training data to build end-
Details
to-end systems. In fact, we use SYGMA(Neelam
TempQuestions 1271 Freebase Set-A
(Freebase) Answers et al., 2021) as our baseline system to evaluate
Wikidata 839 Wikidata Set-A + this benchmark dataset. Such approaches stack
Benchmark Answers Set-B together, in a pipeline, various modules built else-
A Subset 175 Wikidata Set-A +
of Wikidata Answers Set-B + where with minimal adaptation. In such a setup,
Benchmark Set-C it is important to evaluate outputs at intermedi-
ate stages of the pipeline. Additional annotations
Table 3: Benchmark dataset details. TempQuestions de- include, ground truths for intermediate meaning
note original dataset with Freebase answers (Jia et al., representations such as AMR, λ-expression of
2018a). The remaining two, i.e., testset and devset, are
part of the benchmark dataset we created with Wiki-
the question and KB-specific λ-expressions, and
Data answers. In column titled Add’l Details: Set- mention-of/KB-specific entities and relations.
A denote additional annotations that came along with
3.2.1 Question Complexity Categorization
the original TempQuestions dataset, {temporal signal,
question type, data source}. Set-B denote {Wikidata
SPARQL query, question complexity category}. Set- Category
Example
(dev/Test)
C denote ground truths of {AMR, λ-expression, Wiki-
data entities, Wikidata relation, Wikidata-specific λ- When was Titanic movie released?
Simple
expression} SELECT ?a WHERE {
(92/471)
wd:Q44578 wdt:P577 ?a }
who was the US president during
cold war?
plexity label to each question, according to ques- SELECT DISTINCT ?a WHERE {
tion complexity categorization described in Sec- ?a wdt:P39 wd:Q11696. ?a p:P39 ?e1.
Medium
?e1 ps:P39 wd:Q11696.
tion 3.2.1. (71/154)
?e1 pq:P580 ?st1. ?e1 pq:P582 ?et1.
Within this dataset, we also chose a smaller sub- wd:Q8683 wdt:P580 ?st2.
wd:Q8683 wdt:P582 ?et2.
set (of size 175) for more detailed annotations. De- FILTER (?st1For evaluations in Section 4, we divided events. teenager gets teenager age interval for a
dataset TempQA-WD of size 839 into two parts, person, and year return year of a date.
TempQA-WD-test of size 664 and TempQA-WD-
dev of size 175. In fact, TempQA-WD-dev is that 4 Evaluation
part of the dataset with fine-grained annotations. In
this dataset, we also labeled questions with com- 4.1 Evaluation Setup
plexity category based on the complexity of the
question in terms of temporal reasoning required We use SYGMA(Neelam et al., 2021) to the gener-
to answer. Table 4 shows the examples for each ate the baseline results for TempQA-WD dataset.
category of complexity defined below. The baseline system is tuned with dev set of
1) Simple: Questions that involve one temporal TempQA-WD , and evaluated on the test dataset.
event and need no temporal reasoning to derive the
answer. For example, questions involving simple 4.2 Metrics
retrieval of a temporal fact or simple retrieval of
We use GERBIL (Usbeck et al., 2019) to com-
other answer types using a temporal fact.
pute performance metrics from the pairs of gold
2) Medium: Questions that involve two tempo-
answers and system generated answers from the
ral events and need temporal reasoning (such as
pipeline. We use standard performance metrics
overlap/before/after) using time intervals of those
typically used for KBQA systems, namely macro
events. We also include those questions that in-
precision, macro recall and F1.
volve single temporal event but need additional
non-temporal reasoning.
3) Complex: Questions that involve two or more 4.3 Results & Discussion
temporal events, need one temporal reasoning and Table 5 shows performance of SYGMA along
also need an additional temporal or non-temporal with the performance of TEQUILLA (Jia et al.,
reasoning like teenager or spatial or class hierarchy. 2018b) (that uses Freebase as its underlying KB)
3.3 Lambda Calculus on TempQA-WD test set. The accuracy numbers
show that there is room for improvement and good
In this section, we give a brief description of λ- scope for research on temporal QA (and complex
calculus, since we use λ-expressions to logically QA in general) on Wikidata. Table 6 gives detailed
represent the semantics of questions. λ-calculus, report of performance for different categories of
by definition, is considered the smallest universal question complexity. Performance of TEQUILLA
programming language that expresses any com- reflects how well Accu and Quint (the QA systems
putable function. In particular, we have adopted it used) are adapted to Freebase. This in addition
Typed λ-Calculus presented in (Zettlemoyer and to the fact that majority of the questions fall un-
Collins, 2012). In addition to the constants and log- der simple questions category (471 simple vs 39
ical connectives, we introduced some new temporal complex as shown in Table 4), it is able to achieve
functions and instance variables to avoid function better accuracy on Freebase. Given relatively less
nesting. For example, consider the following ques- focus of research on temporal QA on Wikidata so
tion and its corresponding logical form: far, we believe our benchmark dataset would help
accelerate more research and datasets in the future.
Question: when was Barack Obama born? To gain more insights on the performance, we
λt. born(b,“Barack Obama") ∧ also did an ablation study of SYGMA using
Logical Form:
interval(t, b) TempQA-WD dev set where impact of individual
Here, b is instance variable for event born(b, module on overall performance is evaluated. Ta-
“Barack Obama") and interval(t, b) finds time for the ble 7 shows the results. For example GT-AM R
event denoted by b. Variable t is unknown which is refers to the case where ground truth AMR is fed
marked as λ variable. directly into λ-module. The table shows large jump
Temporal Functions: We introduce interval, over- in accuracy (in both the datasets) when fed with
lap, before, after, teenager, year; where interval ground truth entities (GT-EL) and ground truth rela-
gets time interval associated with event and over- tions (GT-RL). This points to the need for improved
lap, before, after are used to compare temporal entity linking and relation linking on Wikidata.System Dataset Precision Recall F1 question-answer pairs. In Proceedings of the 2013
SYGMA TempQA-WD 0.32 0.34 0.32 Conference on Empirical Methods in Natural Lan-
TEQUILLA TempQA-FB 0.54 0.48 0.48 guage Processing, pages 1533–1544, Seattle, Wash-
ington, USA. Association for Computational Lin-
Table 5: Performance of SYGMA guistics.
System Category Precision Recall F1 Antoine Bordes, Nicolas Usunier, Sumit Chopra, and
Simple 0.39 0.37 0.38 Jason Weston. 2015a. Large-scale simple question
SYGMA Medium 0.16 0.13 0.13 answering with memory networks. arXiv preprint
Complex 0.38 0.38 0.38 arXiv:1506.02075.
Simple 0.59 0.53 0.53 Antoine Bordes, Nicolas Usunier, Sumit Chopra, and
TEQUILA Medium 0.46 0.39 0.40 Jason Weston. 2015b. Large-scale simple ques-
Complex 0.20 0.20 0.18
tion answering with memory networks. CoRR,
abs/1506.02075.
Table 6: Category wise Performance
Qingqing Cai and Alexander Yates. 2013. Large-scale
TempQA-WD semantic parsing via schema matching and lexicon
Precision Recall F1 extension. In Proceedings of the 51st Annual Meet-
NO GT 0.47 0.50 0.47 ing of the Association for Computational Linguis-
GT-AMR 0.50 0.51 0.50 tics (Volume 1: Long Papers), pages 423–433, Sofia,
GT-λ 0.52 0.53 0.52 Bulgaria. Association for Computational Linguis-
GT-EL 0.60 0.62 0.60 tics.
GT-RL 0.92 0.93 0.92
GT-KB-λ 0.93 0.93 0.93 Dennis Diefenbach, Kamal Singh, and Pierre Maret.
GT-SPARQL 1.0 1.0 1.0 2017a. Wdaqua-core0: A question answering com-
ponent for the research community. In Semantic
Table 7: Ablation Study on TempQA-WD Web Evaluation Challenge, pages 84–89. Springer.
Dennis Diefenbach, Thomas Pellissier Tanon, Ka-
mal Deep Singh, and Pierre Maret. 2017b. Question
5 Conclusion answering benchmarks for wikidata. In Proceedings
of the ISWC 2017 Posters & Demonstrations and In-
In this paper, we introduced a new benchmark dustry Tracks co-located with 16th International Se-
dataset TempQA-WD for temporal KBQA on Wiki- mantic Web Conference (ISWC 2017), Vienna, Aus-
data. Adapted from existing TempQuestions tria, October 23rd - to - 25th, 2017.
dataset, this dataset has parallel answer annotations
Mohnish Dubey, Debayan Banerjee, Abdelrahman Ab-
on two KBs. A subset of this dataset is also anno- delkawi, and Jens Lehmann. 2019. LC-QuAD 2.0:
tated with output expected at intermediate stages A Large Dataset for Complex Question Answering
of modular pipeline. Future extenstions include over Wikidata and DBpedia, pages 69–78.
improvement of the baseline approach for general- Freebase. Freebase (database). Information about
izable temporal QA. Freebase database at https://en.wikipedia.
org/wiki/Freebase_(database).
References Zhen Jia, Abdalghani Abujabal, Rishiraj Saha Roy, Jan-
nik Strötgen, and Gerhard Weikum. 2018a. Tem-
Michael Azmy, Peng Shi, Jimmy Lin, and Ihab Ilyas. pquestions: A benchmark for temporal question an-
2018. Farewell Freebase: Migrating the Simple- swering. In Companion Proceedings of the The Web
Questions dataset to DBpedia. In Proceedings of Conference 2018, WWW ’18, page 1057–1062, Re-
the 27th International Conference on Computational public and Canton of Geneva, CHE. International
Linguistics, pages 2093–2103, Santa Fe, New Mex- World Wide Web Conferences Steering Committee.
ico, USA. Association for Computational Linguis-
tics. Zhen Jia, Abdalghani Abujabal, Rishiraj Saha Roy, Jan-
nik Strötgen, and Gerhard Weikum. 2018b. Tequila:
Junwei Bao, Nan Duan, Zhao Yan, Ming Zhou, and Temporal question answering over knowledge bases.
Tiejun Zhao. 2016. Constraint-based question an- In Proceedings of the 27th ACM International Con-
swering with knowledge graph. In Proceedings of ference on Information and Knowledge Manage-
COLING 2016, the 26th International Conference ment, CIKM ’18, page 1807–1810, New York, NY,
on Computational Linguistics: Technical Papers, USA. Association for Computing Machinery.
pages 2503–2514, Osaka, Japan. The COLING 2016
Organizing Committee. Zhen Jia, Soumajit Pramanik, Rishiraj Saha Roy, and
Gerhard Weikum. 2021. Complex temporal ques-
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy tion answering on knowledge graphs. In Proceed-
Liang. 2013. Semantic parsing on Freebase from ings of the 30th ACM International Conference onInformation & Knowledge Management, pages 792– answering. In Proceedings of the 52nd Annual Meet-
802. ing of the Association for Computational Linguistics
(Volume 2: Short Papers), pages 643–648.
Pavan Kapanipathi, Ibrahim Abdelaziz, Srinivas Rav-
ishankar, Salim Roukos, Alexander Gray, Ramon Luke S. Zettlemoyer and Michael Collins. 2012. Learn-
Astudillo, Maria Chang, Cristina Cornelio, Saswati ing to map sentences to logical form: Structured
Dana, Achille Fokoue, Dinesh Garg, Alfio Gliozzo, classification with probabilistic categorial gram-
Sairam Gurajada, Hima Karanam, Naweed Khan, mars.
Dinesh Khandelwal, Young-Suk Lee, Yunyao Li,
Francois Luus, Ndivhuwo Makondo, Nandana Mi-
hindukulasooriya, Tahira Naseem, Sumit Neelam,
Lucian Popa, Revanth Reddy, Ryan Riegel, Gae-
tano Rossiello, Udit Sharma, G P Shrivatsa Bhar-
gav, and Mo Yu. 2020. Question answering over
knowledge bases by leveraging semantic parsing and
neuro-symbolic reasoning.
Sumit Neelam, Udit Sharma, Hima Karanam, Sha-
jith Ikbal, Pavan Kapanipathi, Ibrahim Abdelaziz,
Nandana Mihindukulasooriya, Young-Suk Lee, San-
tosh Srivastava, Cezar Pendus, et al. 2021. Sygma:
System for generalizable modular question an-
swering overknowledge bases. arXiv preprint
arXiv:2109.13430.
Apoorv Saxena, Soumen Chakrabarti, and Partha
Talukdar. 2021. Question answering over
temporal knowledge graphs. arXiv preprint
arXiv:2106.01515.
Daniil Sorokin and Iryna Gurevych. 2018. Model-
ing semantics with gated graph neural networks for
knowledge base question answering. In Proceed-
ings of the 27th International Conference on Compu-
tational Linguistics, pages 3306–3317. Association
for Computational Linguistics.
A. Talmor and J. Berant. 2018. The web as a
knowledge-base for answering complex questions.
In North American Association for Computational
Linguistics (NAACL).
Priyansh Trivedi, Gaurav Maheshwari, Mohnish
Dubey, and Jens Lehmann. 2017. Lc-quad: A cor-
pus for complex question answering over knowledge
graphs. In Proceedings of the 16th International
Semantic Web Conference (ISWC), pages 210–218.
Springer.
Ricardo Usbeck, Axel-Cyrille Ngonga Ngomo, Bastian
Haarmann, Anastasia Krithara, Michael Röder, and
Giulio Napolitano. 2017. 7th open challenge on
question answering over linked data (QALD-7). In
Semantic Web Evaluation Challenge, pages 59–69.
Springer International Publishing.
Ricardo Usbeck, Michael Röder, Michael Hoff-
mann, Felix Conrads, Jonathan Huthmann, Axel-
Cyrille Ngonga Ngomo, Christian Demmler, and
Christina Unger. 2019. Benchmarking question an-
swering systems. Semantic Web, 10(2):293–304.
Wen-tau Yih, Xiaodong He, and Christopher Meek.
2014. Semantic parsing for single-relation questionYou can also read

















































